
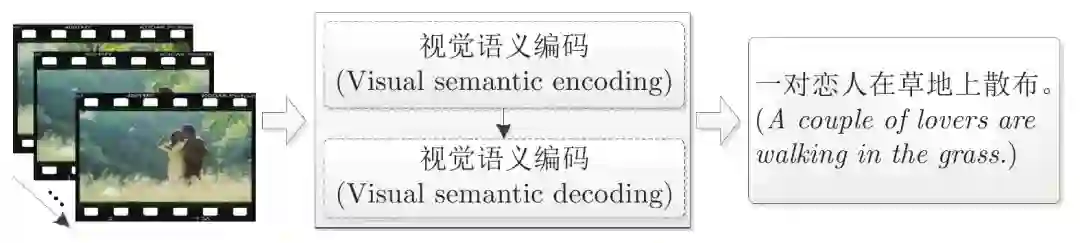
视频标题生成与描述是使用自然语言对视频进行总结与重新表达. 由于视频与语言之间存在异构特性, 其数据处理过程较为复杂. 本文主要对基于“编码-解码”架构的模型做了详细阐述, 以视频特征编码与使用方式为依据, 将其分为基于视觉特征均值/最大值的方法、基于视频序列记忆建模的方法、基于三维卷积特征的方法及混合方法, 并对各类模型进行了归纳与总结. 最后, 对当前存在的问题及可能趋势进行了总结与展望, 指出需要生成融合情感、逻辑等信息的结构化语段, 并在模型优化、数据集构建、评价指标等方面进行更为深入的研究.

成为VIP会员查看完整内容
相关内容
Arxiv
4+阅读 · 2019年7月4日
Arxiv
6+阅读 · 2018年7月24日
Arxiv
5+阅读 · 2018年7月6日



相关资讯
相关论文
Arxiv
4+阅读 · 2019年7月4日
Arxiv
6+阅读 · 2018年7月24日
Arxiv
5+阅读 · 2018年7月6日