
通过最小化逆动力学分歧来实现从观察中模仿学习 Consensus-Aware Visual-Semantic Embedding for Image-Text Matching
本文由腾讯 AI Lab 主导,与天津大学合作完成,提出了一种新的视觉-文本匹配模型。
当今互联网中存在海量的多媒体数据,其中最广泛存在的分别是图像和语言数据。图像-文本匹配任务的核心目的是跨越视觉和语言间的语义鸿沟,进而实现更精准的语义理解。现有的方法只依赖于成对的图像-文本示例来学习跨模态表征,进而利用它们的匹配关系并进行语义对齐。这些方法只利用示例级别的数据中存在的表层关联,而忽略了常识知识的价值,这会限制其对于图像与文本间更高层次语义关系的推理能力。
本论文提出将两种模态间共享的常识知识注入到视觉语义嵌入模型中,进而用于图像文本匹配。具体来说,首先基于图像描述语料库中概念间的统计共生关系构造了语义关系图,并在此基础上利用图卷积得到共识知识驱动的概念表征。通过共识知识和示例级表征的联合利用,能够学习到图像和文本间的高层次语义关联并进行语义对齐。
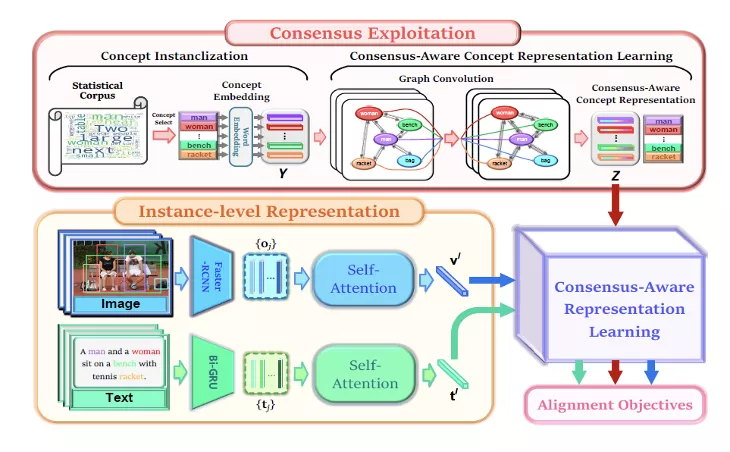
模型的不同模块的结构
给定输入的图像区域特征和文本单词特征,本文提出的 CVSE 模型不仅可以学习示例级别特征,还挖掘共识知识来学习更高层次的语义关联,从而实现更加准确的文本图像匹配。
在两个公共数据集上的大量实验表明,使用共识知识可以大幅增强视觉语义嵌入模型的表征能力,使其在图像-文本双向检索任务上的表现显著优于现有方法。
https://www.zhuanzhi.ai/paper/ba61441001c8cee4cdd68743008a3706
成为VIP会员查看完整内容
相关内容

模仿学习是学习尝试模仿专家行为从而获取最佳性能的一系列任务。目前主流方法包括监督式模仿学习、随机混合迭代学习和数据聚合模拟学习等方法。模仿学习(Imitation Learning)背后的原理是是通过隐含地给学习器关于这个世界的先验信息,比如执行、学习人类行为。在模仿学习任务中,智能体(agent)为了学习到策略从而尽可能像人类专家那样执行一种行为,它会寻找一种最佳的方式来使用由该专家示范的训练集(输入-输出对)。当智能体学习人类行为时,虽然我们也需要使用模仿学习,但实时的行为模拟成本会非常高。与之相反,吴恩达提出的学徒学习(Apprenticeship learning)执行的是存粹的贪婪/利用(exploitative)策略,并使用强化学习方法遍历所有的(状态和行为)轨迹(trajectories)来学习近优化策略。它需要极难的计略(maneuvers),而且几乎不可能从未观察到的状态还原。模仿学习能够处理这些未探索到的状态,所以可为自动驾驶这样的许多任务提供更可靠的通用框架。
Arxiv
8+阅读 · 2020年4月13日
Arxiv
3+阅读 · 2019年5月10日
Arxiv
4+阅读 · 2018年11月26日
相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2020年4月13日
Arxiv
3+阅读 · 2019年5月10日
Arxiv
4+阅读 · 2018年11月26日