【手把手学习笔记】基于深度学习的自然语言处理(附实现代码)
【导读】这篇自然语言处理的学习笔记手把手记录了当前基于深度学习的文本分类常见的模型,分别介绍了数据集处理、特征转换、卷积神经网络、循环神经网络、以及最近很火的注意力机制等方法,手把手教大家如何使用不同的深度网络进行文本分类任务。
作者:Antoine J.-P. Tixier
编译:专知
IMDB电影评论数据集:
该任务是对来自互联网电影数据库(IMDB)数据集的评论进行二元分类(积极/消极),这被称为情感分析或意见挖掘。 该数据集包含五万条电影评论,标记为积极或消极。 数据的50%用于训练,50%用于测试。作者在GitHub上的“imdb_preprocess.py” 代码进行预处理评论并将它们放在一个适合传递给神经网络的格式中:每条评论都是来自大小为V的字典的单词索引(整数)列表。
二元分类目标函数:
我们的模型要最小化的目标函数是对数损失,也称为交叉熵(cross entropy.)。更精确地说,在有两个类(比如0和1)的二进制分类设置中,对数损失被定义为:
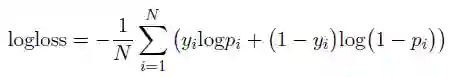
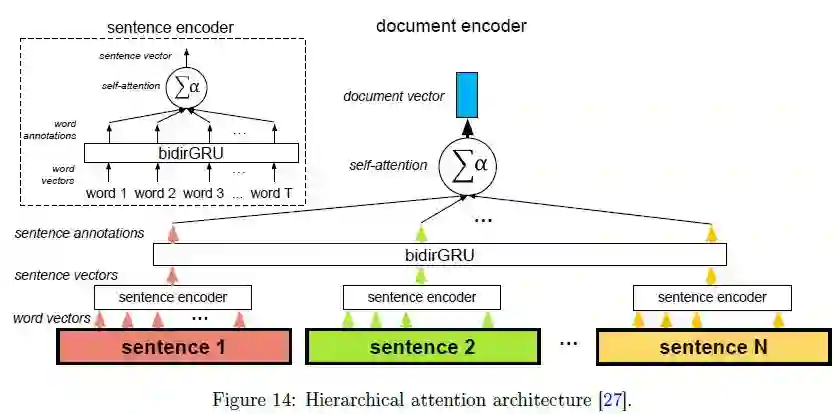
层次注意力机制(Hierarchical attention):
下图所示的体系结构提供了一个关于自注意力机制如何良好地在实践中运用的简单的例子。在这种体系结构中,自注意力机制发挥了两次作用:在单词级别和句子级别。这种方法有意义的原因有两个:首先,它符合文档的自然层次结构(单词-》句子-》文档)。其次,在计算文档的编码时,它允许模型首先确定每个句子中哪些单词是重要的,然后确定哪些句子是重要的。通过句子的注意力系数重新调整单词的注意力系数,该模型捕获了这样一个事实:当在给定的句子中找到时,给定的单词实例可能非常重要,但是当在另一个句子中找到时,同一单词的另一个实例可能不那么重要。
目录:
1. 免责声明
2. 代码
3. IMDB电影评论数据集
1. 概述
2. 二分类目标函数
4. 范式转换
1. 特征嵌入
2. 特征嵌入的好处
3. 结合核心特征
5. 卷积神经网络(CNNs)
1. 局部不变性与组合性
2. 卷积与池化
1. 输入
2. 卷积层
3. 池化层
4. 文档编码
5. Softmax层
3. 参数数目
4. 可视化和理解内部表征和预测
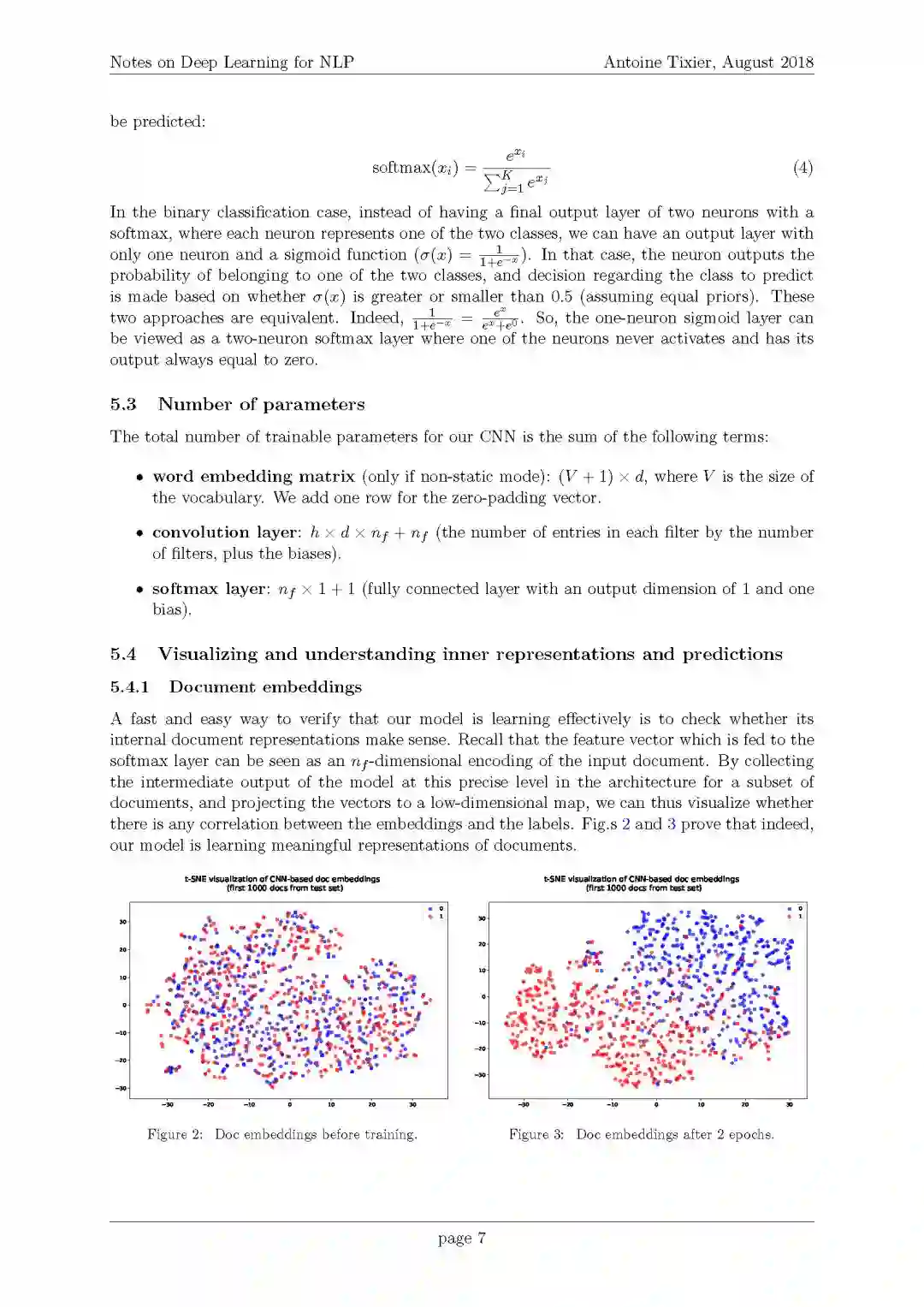
1. 文档嵌入
2. 预测区域识别
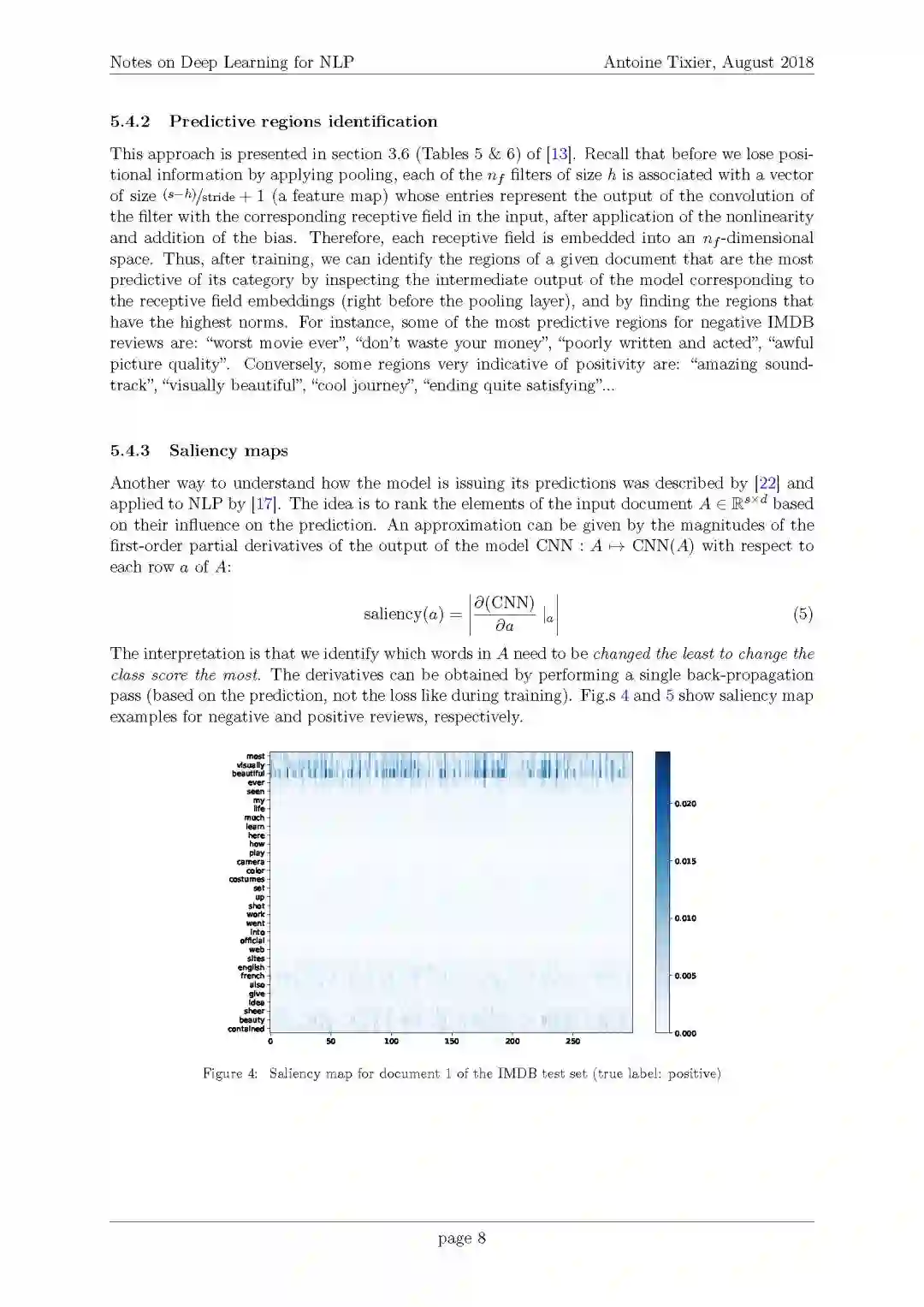
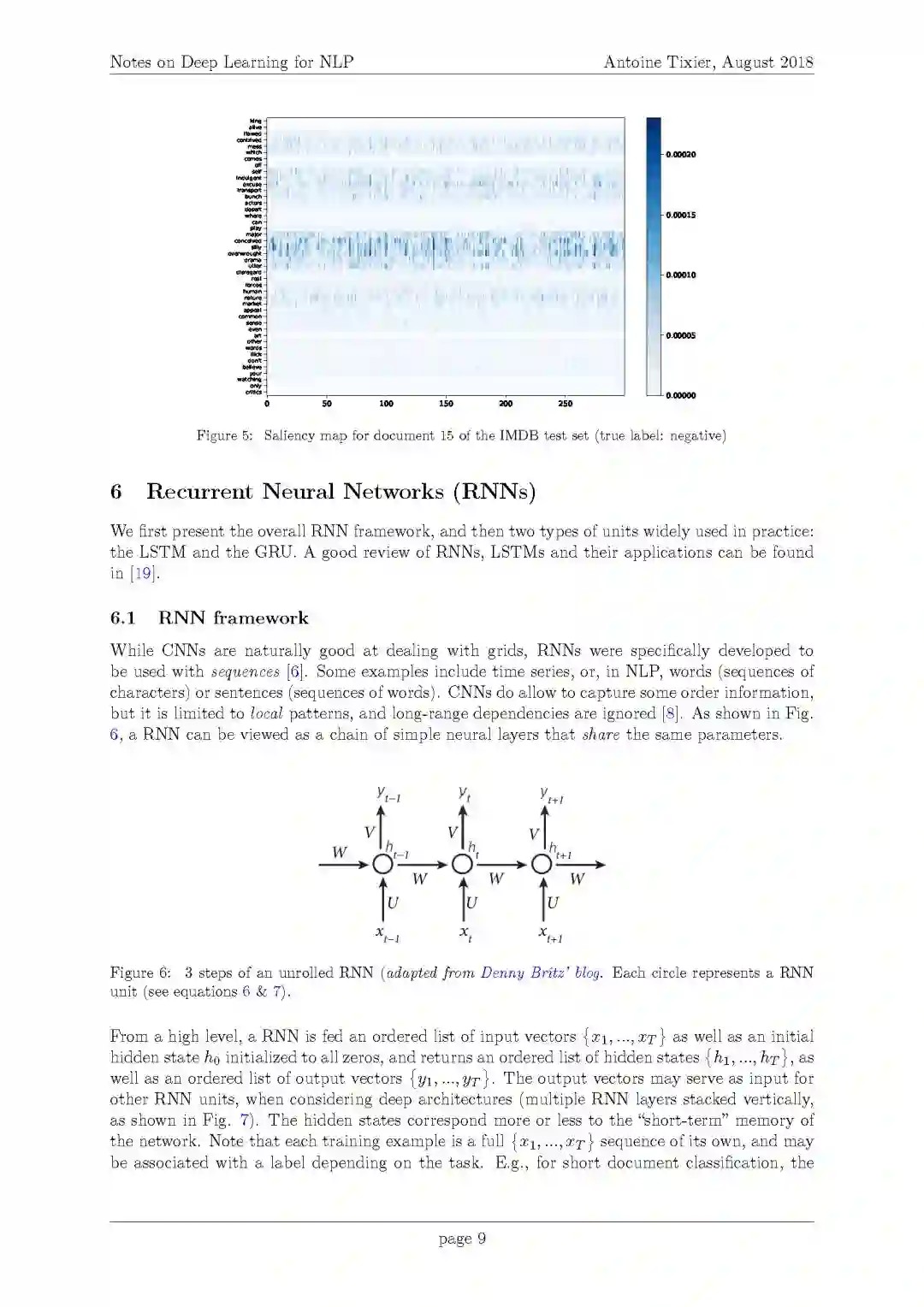
3. 显著性图
6. 循环神经网络(RNNs)
1. RNN框架
1. 语言模型
2. LSTM单元
1. 内部层
2. 遗忘/学习(Forgetting/learning)
3. Vanilla RNN类比
3. Gated Recurrent Unit(GRU)
4. RNN vs LSTM vs GRU
7. 注意力机制
1. Encoder-decoder注意力模型
1. Encoder-decoder 概述
2. 编码(Encoder)
3. 解码(Decoder)
4. 全局注意力
5. 局部注意力
2. 自注意力机制(Self-attention)
1. 与seq2seq注意力机制的不同
2. 层次注意力机制(Hierarchical attention)
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“DLNLPN” 就可以获取最新PDF 下载链接~
代码:
作者在Keras框架中实现了这篇文档中描述的一些模型,并在IMDB电影评论数据集上进行了测试。代码可以在GitHub上找到:
https://github.com/Tixierae/deep_learning_NLP
https://arxiv.org/pdf/1808.09772.pdf
附PDF内容















参考链接:
https://github.com/Tixierae/deep_learning_NLP
https://arxiv.org/pdf/1808.09772.pdf
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知





