![]()
论文链接:http://arxiv.org/abs/2003.00392
代码链接:https://github.com/cshizhe/hgr_v2t
互联网上短视频的快速涌现为视频内容的精准检索带来了前所未有的挑战。使用自然语言文本描述对视频进行跨模态检索(Cross-modal Video-Text Retrieval)是最符合自然人机交互的方式之一,能更加全面细粒度地表达用户检索需求,得到了越来越多的研究关注。
当前跨模态检索的主要方法将视频和文本模态映射到联合视觉语义空间以计算跨模态相似度。大部分工作[1,2]使用全局特征向量分别表示视频和文本信息,但是文本和视频中包含了丰富复杂的元素,例如图1中的事件检索涉及了不同的动作、实体、以及动作实体之间的关系等等,使用单一的特征表示很难捕获细粒度的语义信息。少量工作[3]提出细粒度的密集匹配,将视频和文本表示为序列化特征,对每一序列元素进行局部对齐匹配,融合得到全局跨模态相似度,然而仅使用序列化表示忽略了文本或视频内部复杂的拓扑结构,不能准确地表示事件中不同元素之间的关系,使得局部对齐匹配的语义表达能力下降。
![]()
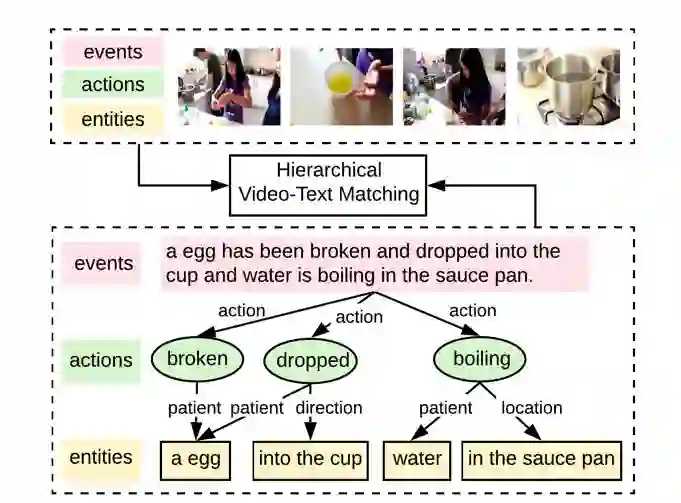
视频文本匹配被分解包括事件(Event)、动作(Action)和实体(Entities)的三个层次,形成整体到局部的结构。一方面,模型可借助局部语义元素增强全局语义匹配;另一方面,全局语义信息也能帮助局部元素的语义理解,增强局部信息的跨模态匹配。
因此,我们提出了层次化图推理模型(Hierarchical Graph Reasoning model, HGR),更好地结合全局和局部密集匹配的优点,并弥补其不足。如图1所示,我们将视频文本匹配分解为三层的语义级别,分别负责刻画全局事件(Event)以及局部的动作(Action)和实体(Entities),以涵盖整体到局部的语义信息。
首先对于文本编码,全局事件由整个句子表示,动作由动词表示,实体则由名词短语表示。
不同语义级别不是独立的,它们之间的交互反映了它们在事件中扮演的语义角色(Semantic Role),因此我们建立三层语义级别的语义角色图(Semantic Role Graph),提出利用基于注意力的图推理方法来捕捉图中的交互信息。
然后,不同层次的文本特征用于指导多样化的视频编码,视频也被编码为与事件、动作和实体相关的层次化表示。
每一层次级通过注意力机制进行跨模态匹配,最后进行不同层次的融合。
我们在三个视频描述数据集上进行实验,从3个方面证明了所提出模型的有效性: 1) HGR模型在多个数据集中取得更好的跨模态检索结果;2) 在跨数据集实验中,HGR模型具有更强泛化性能;3) 提出了一个新的细粒度二元选择任务,HGR模型更能区分细粒度语义变化和选择更加全面的检索结果。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
![]()
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源