
文 / 陶建华,张帅,温正棋
**摘 要:**本文简述了 DeepSeek 系列大模型的技术特点析,并从技术路径、开源生态与应用影响等维度,对大模型发展进行了展望分析。
**关键词:**DeepSeek;混合专家模型;强化学习推理;开源生态
近两年来,大模型技术通过不断的技术创新,实现了在同等参数规模情况下更高的智能能力,其中 DeepSeek 系列大模型具有很强的代表性。2024年12月,DeepSeek 系列大模型通过 V3 与 R1 模型的迭代,在文本生成与推理任务中展现了很好的技术进展。V3 模型通过架构创新与软硬件协同优化,以较低训练成本实现了与 GPT-4 相近的文本生成性能;R1 模型则基于强化学习框架提升了数学计算与逻辑推演的准确性。虽然算力依然是大模型发展的重要支撑平台,但大模型的性能提升,正从过度依赖算力的局面走出来。
1 技术路径分析:算法创新与工程优化的协同
1.1算法创新
DeepSeek 系列大模型在算法层面具有多项改进。例如,DeepSeek-V3 采 用多头潜在注意力(multi-head latent attention, MLA)机制和优化的混合专家架构 DeepSeek MoE,相比标准多头注意力(multi-head attention,MHA), 这些创新不仅优化了推理效率,还通过无辅助损失的负载平衡策略(auxiliary-loss-free)有效解决了专家负载不平衡问题。此外,多 token 预测(multi-token prediction,MTP)训练目标的应用进一步提升了模型性能。这些工作体现了参数的有效组织对模型性能的影响不亚于参数规模本身,并进一步证明了通过仔细的设计(如 DeepSeek-V3 将全部前馈网络参数划分为 256 个专家模块,每次只激活其中 8 个模块进行计算),遵循类似生物神经系统的“稀疏激活”原理的架构,依然能够形成很好的模型性能。
DeepSeek R1 系列模型通过组相对策略优化强化学习算法(group relative policy optimization, GRPO),实现了推理能力的明显提升,并通过推理能力蒸馏技术,将长链思考(chain-of-thought, CoT)能力高效传递到其他模型中,为快速构建强推理模型提供了简易高效的途径。这些技术不仅提高了模型的性能,还为未来大模型的发展提供了有益的借鉴。但也需要注意到,强化学习对高质量训练数据的依赖可能限制其在低资源场景中的应用。此外,推理能力蒸馏的效率高度依赖于教师模型的质量,若教师模型存在偏差,可能加剧下游模型的错误传播风险。
1.2工程优化的成效与约束
在工程优化方面,如图 1 所示,DeepSeek-V3采用 FP8 混合精度训练,结合多种硬件优化技术,如定制化的跨节点全连接通信核心、重计算技术,以及共享嵌入层和输出头等,有效降低了训练成本。尽管如此,FP8 精度对硬件兼容性要求较高,可能影响其在非主流芯片生态中的部署效率。此外,通过 DualPipe 并行算法的应用,进一步提升了模型的训练速度和资源利用率。这些工程深度优化措施不仅使得 DeepSeek 系列大模型能够以较低的成本实现高性能训练,也为 AI 技术的普及和应用提供了有力支持。但其对特定集群架构的适配性可能限制大规模分布式训练的灵活性。
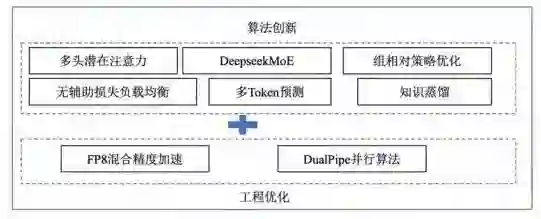
图 1 DeepSeek 模型核心技术
2 未来发展趋势展望
2.1技术架构持续演化:新的模型架构将带动大模型进一步发展
大模型所基于的 Transformer 架构虽然能力很强,但计算复杂度高,尤其是自注意力机制的平方复杂度。未来的模型还将会探索更高效的架构,如混合架构,结合 CNN、RNN 的优势等。此外,将大模型分解为多个专家模型 MoE 也是一种有效的措施,但现有的激活机制过于简单,未来的发展还可能与生物启发机制融合,建立更为高效和更高性能的激活架构。近两年来,采用类脑学习机制的大模型技术上取得了一定成功,这也可能会成为大模型未来发展的重要技术方向之一。
2.2推理和泛化能力:大模型的推理能力提升可解释性增强是关键
当前模型在复杂逻辑推理、数学问题、现实场景应用中仍有不足。未来的模型可能需要结合符号系统,如神经符号计算,将深度学习与符号推理结合,类似于DeepMind的 AlphaGeometry 结合了神经网络和符号引擎。此外,还可通过结构化的因果模型来提升大模型的可解释性和泛化性,以增强模型的因果推理能力,同时可采取更复杂的训练策略,如引入因果推断的损失函数,或者在预训练中融入因果数据等。
2.3 多模型协同:从单模型智能实现模型集群智能随着大模型应用爆发式增长,单一模型的局限性会加速催生基于多模型协同的“模型集群智能”。清华大学团队通过在 7B 主模型的基础上融合另一个 7B 大模型,并使用蒙特卡洛方法进行任务调度,实现了多个大模型的协同工作,显著提升了 7B 模型在数学推理等复杂推理任务中的性能,超越了 GPT-4o,成功实现了小模型协作达到大模型性能的效果。这一范式通过分层架构、动态调度与生态协同重构AI 服务生态,基础层作为通用智能基座支撑语言理解等核心能力;垂直领域则通过参数插拔式微调接入专业子模型,破解通用模型在专业场景的精度瓶颈;边缘端部署的轻量化模型实现用户个性化需求的快速响应,形成“云 - 边 - 端”协同网络。从未来发展上看,单一大模型性能提升与多大模型协同计算,将会出现并行发展态势。
2.4 大模型低成本训练:算力堆砌转向软硬件协同优化
通过软硬件协同优化,DeepSeek 降低了对高端计算加速卡的依赖。在硬件适配层面可通过深度优化指令集架构,并进行软硬件协同的模型优化,实现华为昇腾等国产芯片的推理效率提升至英伟达旗舰产品的 90% 以上,可推动国产芯片在 AI 数据中心占比快速加大。这种软硬件协同创新冲击传统算力堆砌模式,使训练效率提升与硬件生态适配形成双向互促,有助于国产硬件产业的发展。然而这种技术模式会进一步加大软件与硬件的深度绑定,使得创新性的软件架构与硬件设计需要彼此兼容,一定程度上限制了创新空间。
2.5开源冲击闭源垄断:闭源引领转向开源生态
DeepSeek 的开源策略推动了技术普惠,促使闭源厂商调整战略,从技术封闭转向开放生态共建。国内云厂商(如阿里云、腾讯云)基于开源框架推出定制化工具链,形成“开源框架 + 商业服务”的生态模式。行业竞争焦点从参数规模转向生态兼容性,开发者社区黏性成为核心指标。当模型架构成为开源社区的公共知识,开发者从“技术消费者”转变为“认知共创者”。这种转变正在催生新型创新网络:企业提供基础模型作为“认知基座”,开发者通过微调 / 蒸馏创造垂直领域“认知插件”,用户数据反馈形成“认知飞轮”。这种三位一体的协同体系,正在重塑传统 AI 价值链的结构。然而,开源可能导致核心优化技术被少数机构通过协议控制形成隐性垄断,同时增加模型滥用与安全漏洞暴露的风险。如何平衡开放共享与技术主权,仍需建立全球协同的治理框架。
2.6安全治理的滞后性矛盾
人工智能技术的突破性发展,正推动全球安全治理体系面临根本性考验。技术迭代速度与开源生态的扩散效应形成叠加冲击,暴露出传统治理框架在时间响应、空间管控和价值协调维度的系统性滞后:技术迭代速度已远超政策制定流程周期,导致制度性防御真空持续扩大;开源模型的跨国流动与主权管辖冲突,传统治理框架在智能时代的适应性不足。构建动态合规机制与跨文化伦理标准,是亟待突破的难题。
3 结束语
DeepSeek 系列模型通过算法与工程创新,为大模型的高效训练与推理提供了有效参考,其开源策略亦加速了技术普惠进程。但总体上,大模型在复杂任务泛化性、硬件兼容性、多模型协同效率及安全治理等方面仍存在显著挑战。唯有通过技术创新与风险治理的平衡,方能实现人工智能的可持续发展。
(参考文献略)

陶建华
CAAI 元宇宙技术专委会主任,清华大学自动化系长聘教授,国家杰青获得者,享受国务院政府特殊津贴,CAAI Fellow。研究方向为多源信息融合、模式识别、大数据分析等。负责国家“863 计划”、国家自然科学基金重点、国家重点研发计划等项目 20 余项,在多个国内外主要学术期刊和会议上发表论文 300 余篇。曾获 CAAI 吴文俊人工智能技术发明特等奖、 CIE 技术发明一等奖。多个国际期刊副主编,多次担任国内外重要学术会议的主席。
选自《中国人工智能学会通讯》 2025年第15卷第2期 大模型技术专栏

