大型语言模型(LLMs)在多个领域展现了卓越的能力,从自然语言理解到文本生成。相比于非生成型的大型语言模型(如 BERT 和 DeBERTa),生成型的大型语言模型(如 GPT 系列和 Llama 系列)因其出色的算法性能而成为当前的研究重点。生成型大型语言模型的进步与硬件能力的发展密切相关。不同的硬件平台具有各自独特的硬件特性,可以帮助提升大型语言模型推理的性能。因此,本文对在不同硬件平台上高效生成型大型语言模型推理进行了全面综述。首先,我们概述了主流生成型大型语言模型的算法架构,并深入探讨了推理过程。接着,我们总结了不同平台(如 CPU、GPU、FPGA、ASIC 以及 PIM/NDP)的优化方法,并提供了生成型大型语言模型的推理结果。此外,我们对不同硬件平台在批处理大小为 1 和 8 时的推理性能进行了定性和定量的比较,考虑了硬件功耗、绝对推理速度(tokens/s)和能效(tokens/J)。我们比较了相同优化方法在不同硬件平台上的性能、不同硬件平台之间的性能以及相同硬件平台上不同方法的性能。本文通过整合软件优化方法与硬件平台,对现有的推理加速研究进行了系统而全面的总结,这将有助于指引生成型大型语言模型及其硬件技术在边缘场景中的未来趋势和潜在发展方向。
https://www.zhuanzhi.ai/paper/a4b8faafe1652c6eedeeed04639239a4
关键词:生成型大型语言模型 · 硬件 · CPU · GPU · FPGA · ASIC · PIM · NDP
1 引言
大型语言模型(LLMs)已成为现代人工智能的基石,在从自然语言理解到文本生成等各个领域展现出卓越的能力【1, 2, 3, 4, 5】。LLMs可以分为两种主要类型:生成型LLMs和非生成型LLMs。非生成型LLMs,如BERT【6】、RoBERTa【7】、ELECTRA【8】和DeBERTa【9】,旨在基于输入文本进行分类和预测。这些模型通常包含数百万个参数,使其在需要辨别和细致理解的任务中表现出色。BERT于2018年推出,参数量仅为3.4亿。RoBERTa在2019年推出,参数量增加到3.55亿。2021年推出的DeBERTa则增加到15亿参数。生成型LLMs,如GPT系列【10, 11, 12, 13】、T5【14】、OPT【15】、BLOOM【16】以及Llama系列【17, 18, 19】,在语言生成方面实现了新突破。生成型LLMs模型规模的显著增长【10, 11, 20, 12, 14, 21, 22, 23, 24, 25, 26, 27, 28, 29, 15, 16, 30, 13, 31, 32, 33, 34, 35, 17, 18, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 19, 51, 52, 53, 54, 55, 56, 57】在过去六年尤其显著,见图1。2018年,GPT1只有1.1亿参数,而到2019年,GPT2增长至15亿参数。2020年推出的GPT3达到了惊人的1750亿参数,而GPT3.5则保持相同规模。在2022年后,模型规模稳定在数百亿甚至数万亿参数,如GPT4、Llama3和Grok1【58】。LLMs的演变以模型参数的指数增长为特征,这对提升其性能和多功能性至关重要。与非生成型LLMs相比,生成型LLMs凭借其出色的算法性能,成为LLMs领域当前研究与发展的主要焦点。

近年来,生成型LLMs的参数规模在2022年达到数万亿规模后,停止了指数增长。这一现象的主要原因有二:(1)随着计算量的增加,对计算能力的需求也显著增加。硬件能力的增长缓慢,尤其是摩尔定律的放缓【59】,限制了单芯片计算能力的提升。(2)研究人员发现,模型性能不仅依赖于参数数量,还依赖于训练数据的数量和质量【60】。通过提供更优质的训练语料,可以进一步提升算法性能【18, 19】。同时,生成型LLMs的参数规模逐渐从“大”转向“稳定”甚至“缩小”。更多适用于边缘设备的较小模型不断涌现。值得注意的是,OpenAI近期推出的o1【61】通过引入连锁思维(CoT)推理和多步推理提高了算法性能。这种新的计算模式增加了模型推理的作用,进一步凸显了加速推理效率的必要性。 生成型LLMs的进展与硬件能力的发展密不可分。受摩尔定律持续作用的影响,从2018年到2022年,GPU制造工艺从12nm提升到3nm,单GPU芯片的浮点性能从130 TFLOPS增加到989 TFLOPS。在模型训练中,由于CUDA编程栈的用户友好性和GPU芯片的高扩展性(如NVLink【63】),GPU被广泛使用。在推理过程中,CPU、GPU、FPGA和ASIC等硬件选项则展示出不同的硬件特性,有助于提升LLM推理性能。CPU提供高可编程性,计算能力约为4到70 TOPS,功耗范围从4W到200W以上。现代CPU(包括一些片上系统SoCs)通过集成特定领域架构(DSA)单元来增强AI性能,如Apple的M2 Ultra中的神经引擎【64】、高通Snapdragon 8 Gen3中的NPU【65】,以及英特尔的AVX/AMX ISA扩展【66】。GPU在并行性和计算能力方面表现出色,计算能力在约70到1000 TOPS以上,内存带宽可达1555 GB/s。一方面,GPU集成了大量的SIMD核心和NVIDIA V100/A100/H100【67, 68, 69】中的Tensor Cores或AMD Instinct MI100/MI200/MI300系列中的Matrix Cores【70, 71, 72】,以增强计算能力。另一方面,GPU支持较低精度计算(如INT8、FP8和INT4【68, 69】),允许在给定的芯片面积中容纳更多的乘法单元。然而,其功耗也显著更高,范围从约20W到700W以上。FPGA提供了显著的并行性和优化能力,计算性能在50到100 TOPS之间,功耗大约为75到100W。ASIC通常为特定应用设计并定制芯片,计算能力范围广泛,从GOPS到TOPS,功耗可从0.1W左右到几百瓦不等。由于其专业设计,ASIC通常比GPU和CPU具有更高的计算效率和能效。每种硬件类型的独特属性影响其在各种推理场景中的最佳应用。
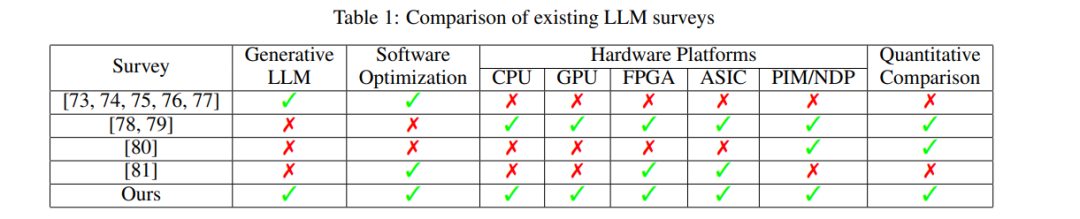
在表1中,我们列出了现有LLM推理的综述。之前的综述【73, 74, 75, 76, 77】主要从算法角度总结了生成型LLMs的量化、稀疏性、快速解码等各种软件优化方法。然而,它们并未考虑不同优化方法在不同硬件平台上的推理性能差异,同样也缺乏公平且定量的比较。综述【78, 79】关注于加速基于Transformer的LLMs,包括非生成型LLMs如BERT和少量生成型LLMs如GPT,但仅列出在不同硬件平台上的研究成果,缺乏对不同加速器所用优化方法的总结和抽象。此外,它们仅相对比较了不同基准的加速和能效,而缺乏生成型LLMs最重要的绝对推理速度(每秒生成token数,tokens/s)和推理能效(每焦耳生成token数,tokens/J)方面的公平比较。与【78, 79】类似,综述【80, 81】主要关注于非生成型LLMs和一两个特定硬件平台。我们的综述专注于生成型LLMs,总结了结合多种硬件平台(包括CPU、GPU、FPGA、ASIC和PIM/NDP)的各种软件优化方法。我们首次创新性地使用了对生成型LLMs至关重要的性能指标:每秒生成的token数量(tokens/s)和每焦耳生成的token数量(tokens/J)。我们比较了(1)相同优化方法在不同硬件平台上的性能,(2)不同硬件平台之间的性能,以及(3)相同硬件平台上不同方法的性能。这一系统性和全面的综述整合了软件优化方法和硬件平台,对现有推理加速研究进行了总结。文章结构精细,全面总结了不同硬件平台上生成型LLMs的不同优化方法。第2节深入探讨了LLMs的推理过程,概述了主流生成型LLMs的架构及功能。第3节首先以表格形式总结了在CPU、GPU、FPGA、ASIC和PIM/NDP等平台上的不同优化方法,然后详细描述了每种方法及相关研究。此外,我们对每种方法进行了定性和定量的比较,以展示硬件平台间的差异。第4节对批处理大小为1和8时在不同硬件平台上的推理性能进行了定性和定量比较,同时指出生成型LLMs和硬件技术在边缘场景中的未来趋势和潜在发展。第5节总结了本综述的工作。