图像编辑旨在编辑给定的合成或真实图像以满足用户的特定需求。近年来,图像编辑作为一个前景广阔且充满挑战的人工智能生成内容(AIGC)领域被广泛研究。该领域最近的显著进展基于文本到图像(T2I)扩散模型的发展,这些模型根据文本提示生成图像。T2I模型展现了非凡的生成能力,已成为图像编辑的广泛使用工具。基于T2I的图像编辑方法显著提升了编辑性能,并提供了一个用户友好的界面,通过多模态输入引导内容修改。在本综述中,我们对利用T2I扩散模型的多模态引导图像编辑技术进行了全面回顾。首先,我们从整体角度定义了图像编辑的范围,并详细说明了各种控制信号和编辑场景。然后,我们提出了一个统一的框架来形式化编辑过程,将其分类为两大主要算法家族。该框架为用户提供了一个设计空间以实现特定目标。随后,我们对该框架内的每个组件进行了深入分析,考察了不同组合的特征及其适用场景。鉴于基于训练的方法在用户引导下学习直接将源图像映射到目标图像,我们将其单独讨论,并介绍了在不同场景中源图像的注入方案。此外,我们回顾了2D技术在视频编辑中的应用,重点解决帧间不一致的问题。最后,我们讨论了该领域的开放挑战,并提出了潜在的未来研究方向。我们在https://github.com/xinchengshuai/Awesome-Image-Editing持续追踪相关工作。
随着跨模态数据集[1], [2], [3], [4], [5], [6], [7]和生成框架[8], [9], [10], [11], [12]的发展,新兴的大规模文本到图像(T2I)模型[13], [14], [15]使人们能够创建所需的图像,开启了计算机视觉中的人工智能生成内容(AIGC)时代。大多数这些工作基于扩散模型[12],这是一个广泛研究的流行生成框架。最近,许多工作探索了这些基于扩散的模型在其他领域的应用,如图像编辑[16], [17], [18], [19], [20], [21],3D生成/编辑[22], [23], [24],视频生成/编辑[25], [26], [27], [28]等。与图像生成不同,编辑旨在进行二次创作,即修改源图像中的所需元素并保留与语义无关的内容。质量和适用性方面仍有进一步改进的空间,使得编辑仍然是一个有前景且充满挑战的任务。在这项工作中,我们对利用T2I扩散模型的多模态引导图像编辑技术进行了全面综述。
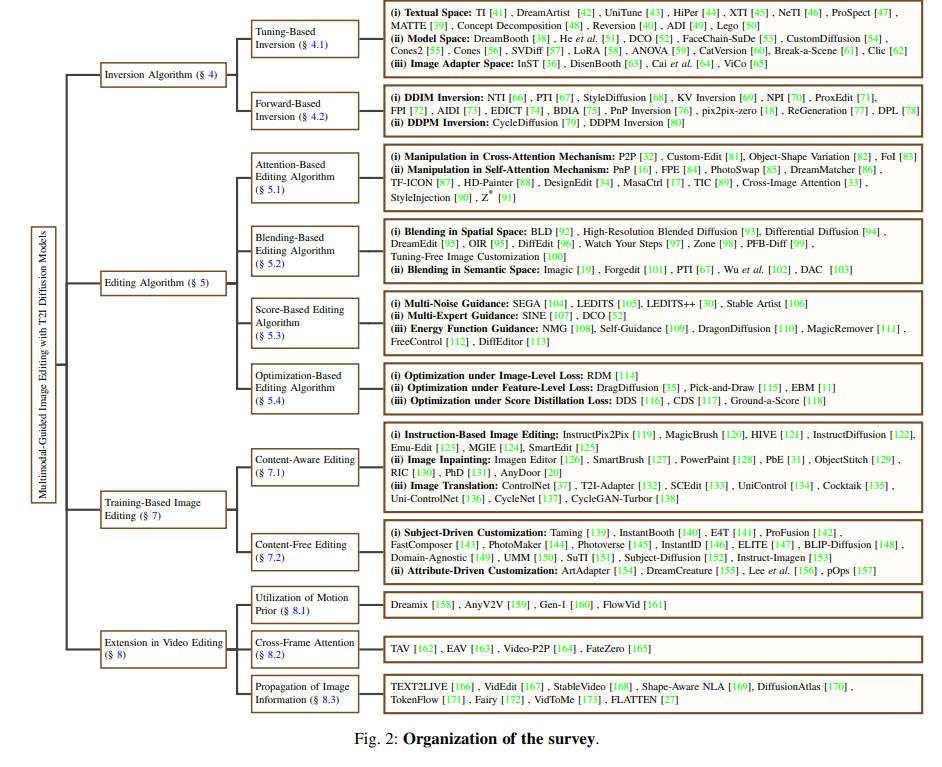
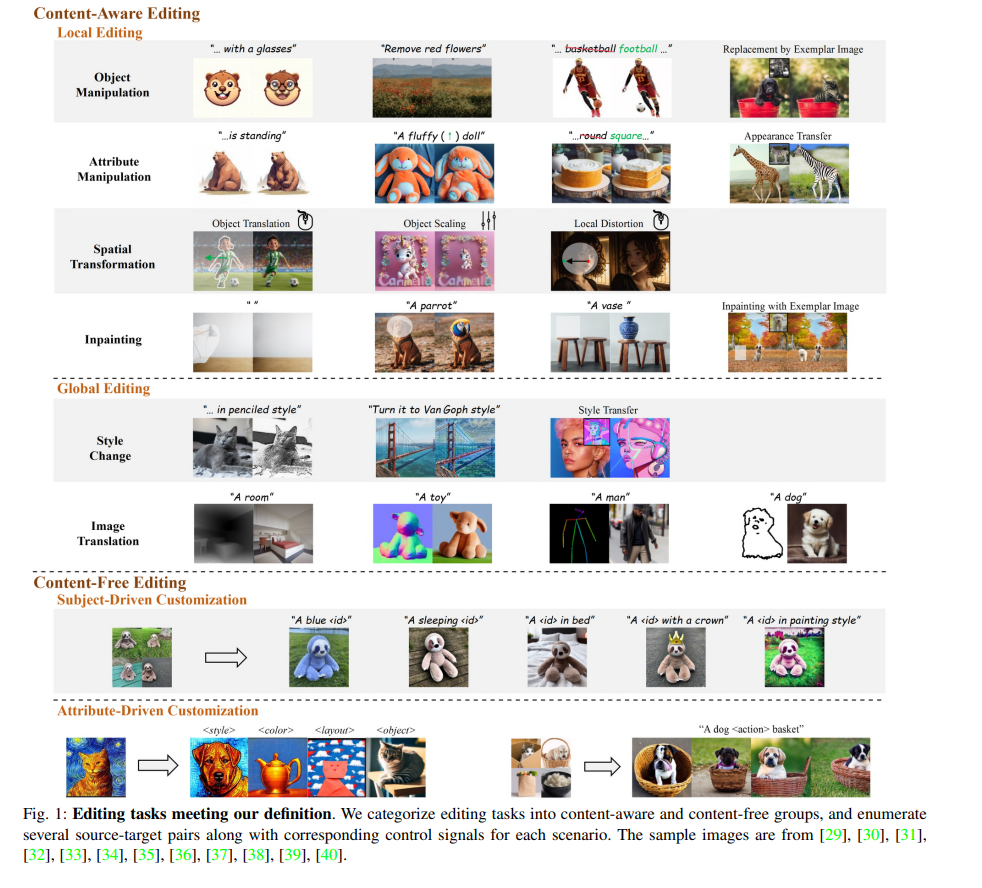
已有一些综述[174], [175], [176], [177], [178]从不同角度回顾了最先进的基于扩散的方法,如图像修复[179],超分辨率[176],医学图像分析[177]等。与这些综述相比,我们专注于图像编辑领域的技术。有两个相关的并行工作[175], [178]与我们的综述相关。其中,[178]介绍了扩散模型在图像编辑中的应用,并根据其学习策略对相关论文进行了分类。与之相比,我们从一个新颖而全面的角度讨论了这一主题,并提出了一个统一的框架来形式化编辑过程。我们发现,之前文献[16], [32], [66], [178]对编辑的解释是有限和不完整的。这些工作限制了保留概念的范围,并倾向于从源图像中重建最大量的细节。然而,这种常见设置排除了某些高层语义(如身份、风格等)的维护。为了解决这个问题,我们首先提供了严格而全面的编辑定义,并在本综述中纳入了更多相关研究,如[37], [38], [61], [146]。图1展示了符合我们定义的各种场景。值得注意的是,一些生成任务如定制化[41], [54]和带图像引导的条件生成[37], [134]都符合我们的讨论范围。这些任务在另一项关注可控生成的并行工作[175]中有所讨论。其次,我们将审查的方法整合到一个统一的框架中,将编辑过程分为两大算法家族,即反演和编辑算法。在[178]中,引入了一个类似的框架来统一那些不需要训练或测试时微调的方法。不同的是,我们的框架在讨论的广义编辑场景中更为多样化。同时,该框架为用户提供了一个设计空间,以根据其具体目的结合适当的技术。综述中的实验展示了不同组合的特征及其适用场景。此外,我们还调查了2D方法[32], [180]在视频编辑[165], [173]中的扩展,并集中讨论了它们解决时间一致性问题的方法,补充了研究领域的缺失部分。
我们对三百多篇论文进行了广泛的综述,审查了现有方法的本质和内部逻辑。本综述主要关注基于T2I扩散模型的研究[13], [14], [181]。在第二部分中,介绍了扩散模型和T2I生成中的技术,提供了基本的理论背景。在第三部分中,我们给出了图像编辑的定义,并讨论了几个重要方面,如不同模态的用户引导、编辑场景以及一些定性和定量评估指标。同时,我们形式化了提出的统一框架以整合现有方法。接下来,在第四和第五部分中分别讨论了我们框架的主要组成部分。反演算法从源图像中捕捉要保留的概念,而编辑算法则旨在在用户引导下再现视觉元素,实现内容一致性和语义保真度。在第六部分中,我们检查了反演和编辑算法的不同组合,并探讨了它们的特征和适用场景,从而指导用户为不同目标选择适当的方法。由于基于训练的方法[20], [119], [122], [182]学习直接将源图像转化为目标图像,我们在第七部分中讨论了这些工作,并详细介绍了源图像在不同任务中的注入方案。第八部分介绍了图像编辑在视频领域的扩展。由于视频数据的稀缺,直接应用图像域方法通常会导致帧间不一致。该部分讨论了现有工作[158], [164], [166], [171]中的几种解决方案。最后,在第九部分中,我们讨论了未解决的挑战,并提出了潜在的未来研究方向。图2展示了我们工作的组织,并分类了每部分中审查的论文。