多标签学习是一个迅速发展的研究领域,旨在从单个输入数据点预测多个标签。在大数据时代,涉及多标签分类(MLC)或排名的任务提出了重大而复杂的挑战,在多个领域吸引了相当多的注意力。MLC固有的困难包括处理高维数据、解决标签相关性和处理部分标签,传统方法在这些方面效果不佳。近年来,采用深度学习(DL)技术来更有效地解决MLC中的这些挑战的尝试显著增加。值得注意的是,有一个增长中的努力旨在利用DL的强大学习能力,以改进对标签依赖性及MLC中其他挑战的建模。 然而,值得注意的是,专门针对多标签学习的DL的综合研究相对有限。因此,这项综述旨在彻底回顾DL在多标签学习中的最新进展,以及MLC中开放研究问题的总结。 该综述整合了DL在MLC中的现有研究努力,包括深度神经网络、变换器(Transformer)、自编码器、卷积和循环架构。最后,该研究提出了现有方法的比较分析,以提供有洞察力的观察,并激发该领域未来研究方向的思考。
在许多实际应用中,一个对象可能同时与多个标签关联,这类问题被认为是多标签学习(MLL)【1】。MLL是标准单标签学习范式的扩展,在这个范式中,通常有一个有限的潜在标签集,这些标签可以应用于多标签数据(MLD)的实例。基本目标是同时预测给定单个输入的输出向量,这意味着它可以解决更复杂的决策问题。这与单标签分类相对,单标签分类中每个实例只与一个标签关联。在多标签任务的上下文中,一个实例通常与一组标签相关联,构成称为相关标签(活动标签)的不同组合,而与实例未链接的标签被称为不相关标签。相关和不相关标签都表示为一个二进制向量,其大小与MLD中标签的总数对齐。根据目标的不同,MLL中存在两个主要任务:多标签分类(MLC)和多标签排名(MLR)【2】。MLC是主要的学习任务,涉及学习一个模型,该模型输出一个标签集的二分划分,将其分为与查询实例相关和不相关的标签。另一方面,MLR关注于学习一个模型,该模型输出类标签的排序,根据它们对查询实例的相关性进行排序。
尽管MLC应用传统上集中在文本分析、多媒体和生物学上,但它们的重要性正在逐渐增长,涵盖了多个领域,如文档分类【3】【4】【5】、医疗保健【6】【7】【8】、环境建模【9】【10】、情感识别【11】【12】、商业【13】【14】、社交媒体【15】【16】【17】等。许多其他要求严格的应用,如视频注释、网页分类和语言建模,也可以从被构建为MLC任务中获益,这涉及到数百、数千甚至数百万的标签。如此广泛的标签空间提出了研究挑战,例如与数据稀疏性和可扩展性相关的问题。MLC还包含额外的复杂性,包括建模标签相关性【18】【19】、不平衡标签【20】和噪声标签【21】。传统的MLC方法,如问题转换和算法适配【22】【23】,在解决这些挑战时表现出次优性能。
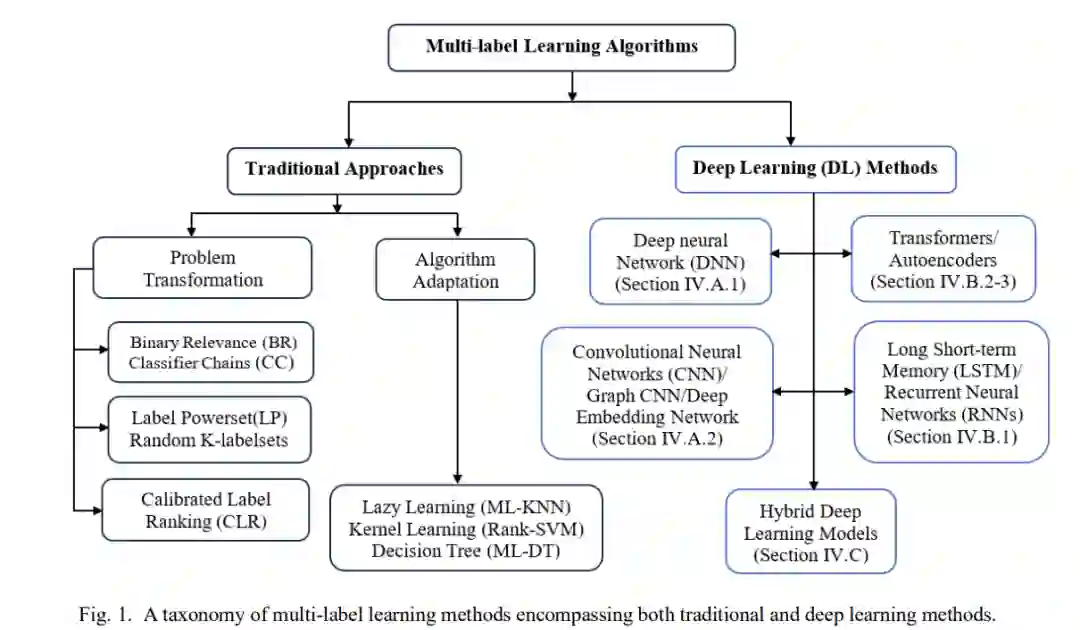
除了传统方法外,深度学习(DL)技术在解决MLC挑战中越来越受欢迎。深度学习的强大学习能力特别适用于解决MLC挑战,这通过它们在解决单标签分类任务中的显著成功得到了证明。目前,MLC中的一个主要趋势是广泛地结合DL技术,即使是对于更具挑战性的问题,如极端MLC【24】【25】【26】、不平衡MLC【27】【28】、弱监督MLC【29】【30】【31】和缺失标签的MLC【32】【33】。有效地利用DL的强大学习能力对于更好地理解和建模标签相关性至关重要,从而使DL能够有效地解决MLC问题。一些研究表明,专门设计用于捕获标签依赖性的MLC方法通常展示出更优越的预测性能【34】【19】。本文对现有文献进行了简要回顾,旨在识别一系列基于DL的技术用于MLC问题,以激发对MLC的创新DL基方法的进一步探索。已有一些关于MLC传统方法的综述,如在【35】【23】【36】中引用的那些。此外,还有一些综述包含了传统方法和DL方法【37】【38】,但这些综述对MLC的DL方法的覆盖有限,并且集中在特定领域。然而,本文独特地关注于一系列DL架构,包括循环和卷积网络、变换器、自编码器和混合模型,用于解决多个领域中的MLC挑战。在图1中,我们提出了一个包含传统方法和DL方法的多标签学习方法的分类。
本文的主要贡献可以概括如下:
据作者所知,本综述是第一个全面覆盖用于解决MLC任务的DL方法的,涵盖了多种领域和数据模态,包括文本、音乐、图像和视频。
提供了一个关于多个公开可用数据集上最新DL方法的综合总结(表I、II和III),简要概述了每种DL方法并进行了深刻的讨论。因此,本综述为读者提供了最先进的方法。
我们提供了当前面临MLC领域挑战的简要描述。此外,我们还总结了在MLC中使用的多标签数据集,以及评估这些数据集特性所用的属性定义。 最后,本文提供了一项涉及各种DL技术的现有方法的比较研究,并调查了每种方法的优缺点(表V)。它提供了可以指导选择合适技术和在未来研究中开发更好DL方法的见解。 本文的后续部分组织如下。 第II部分介绍多标签学习的基本概念。第III部分介绍了研究方法论,重点是数据来源和搜索策略、选择标准以及出版物的统计趋势。第IV部分是本综述的主要部分,讨论了解决MLC挑战的各种DL方法。第V部分关注MLC中的开放性挑战和数据集。第VI部分提供了解决方案的比较分析,包括优势和局限。最后,第VII部分给出了本文的结论。
近年来,DL(深度学习)的进步显著丰富了MLC(多标签分类)的领域景观。DL架构在生成输入特征和输出空间的嵌入表示方面发挥了关键作用。DL的强大学习能力在各个领域的MLC任务中得到了广泛应用,例如图像、文本、音乐和视频。用于MLC的最常用DL方法包括深度神经网络、卷积、循环、自编码器和变压器架构,以及混合模型。有效地利用这些DL方法的优势对于解决MLC中的标签依赖性和其他挑战至关重要。本节提供了这些突出DL方法在MLC中的应用概览,并对每种技术进行了专门针对MLC的详细考察。