大型语言模型(LLMs)展示了出色的泛化能力,这促进了众多模型的发展。这些模型提出了各种新的架构,微调了现有架构的训练策略,增加了上下文长度,使用了高质量的训练数据,并增加了训练时间,以此超越基线性能。分析新的发展对于识别那些能提高LLMs训练稳定性和改善泛化能力的变化至关重要。这篇综述论文全面分析了LLMs的架构及其分类,训练策略,训练数据集,性能评估,并讨论了未来的研究方向。此外,这篇论文还讨论了LLMs背后的基本构建模块和概念,然后对LLMs的重要特性和功能进行了全面概述。最后,这篇论文总结了LLMs研究的重要发现,并整合了开发高级LLMs的重要架构和训练策略。鉴于LLMs的持续发展,我们打算定期更新这篇论文,通过添加新的部分并展示最新的LLMs模型。
https://www.zhuanzhi.ai/paper/c50ae8aa97761c357e5a03b701379652
1. 引言
语言在人类的交流和自我表达中起着基础性的作用,同样,通信对于机器与人类和其他系统的互动也极为重要。大型语言模型(LLMs)已经成为处理和生成文本的尖端人工智能系统,旨在进行连贯的交流[1]。对LLMs的需求源于对机器处理复杂语言任务的日益增长的需求,包括翻译,摘要,信息检索和对话交互。最近,语言模型方面取得了显著的突破,主要归功于深度学习技术,像transformers这样的神经结构的进步,增加的计算能力,以及从互联网中提取的训练数据的可获取性[2]。这些发展引起了革命性的转变,使得能够创建在某些评估基准上接近人类水平表现的大型语言模型(LLMs)成为可能[3],[4]。尤其是预训练语言模型(PLM),在大规模文本语料库的自监督设置下训练,展示了对于文本理解和生成任务的巨大泛化能力[5],[6],[7]。当预训练语言模型(PLMs)微调用于下游任务时,其性能显著提升,超越了从头开始训练的模型的表现。这些语言模型的特性激励了研究者在更大的数据集上训练更大的PLMs,他们发现,进一步扩大模型和数据集的规模可以提高泛化能力。
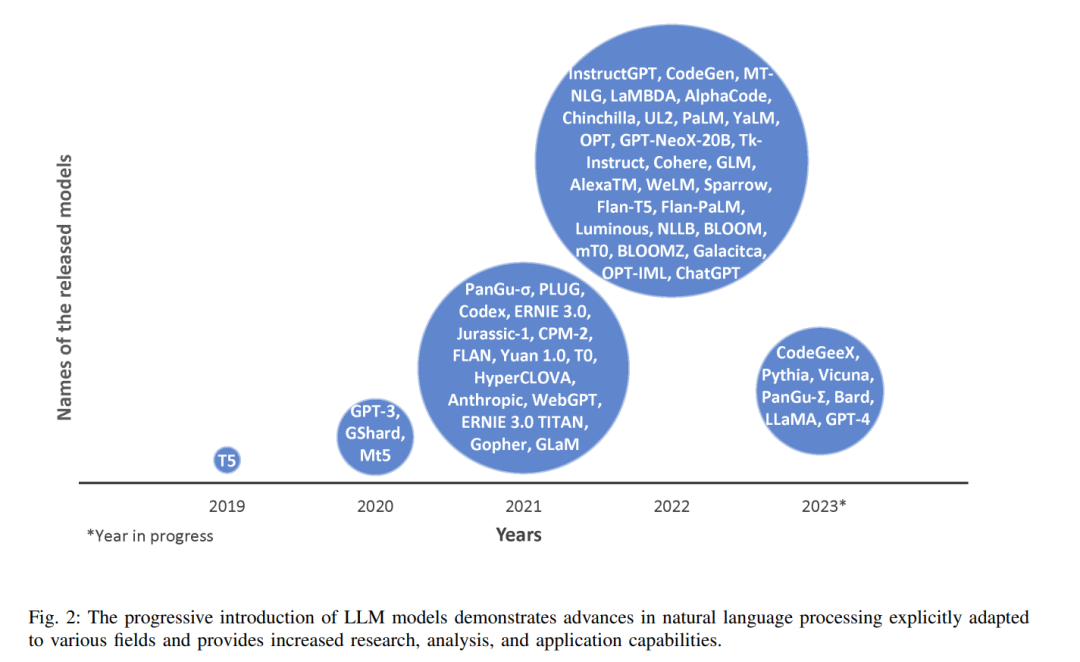
如今,现代LLMs能够在多个领域进行诸如代码生成、文本生成、工具操作、推理和理解等多种任务,在零样本和少样本的情况下,甚至不需要在下游任务上进行任何微调就能做到这一点[8],[9],[10]。以前,较小的模型无法达到这样的泛化,这标志着语言建模的重大进步。这一发展在研究社区中激发了对LLM架构和训练策略改进的热情和兴奋,导致了众多LLMs的开发[11],[12],[13],[8],[9],[10],[14]。图1展示的图表显示了随着时间的推移,发布的LLMs数量(包括开源和闭源模型)的增加趋势。此外,图2突出显示了各种LLMs的重要发布名称。在大型语言模型(LLMs)的早期阶段,许多研究工作都集中在为下游任务开发转移学习的模型[11],[12],[15],直到像GPT-3这样的模型的出现[8],即使不进行微调也表现出了令人印象深刻的性能。由于GPT-3的闭源性质,人们对开源替代品有需求,这导致了各种模型的开发[9],[10],这些模型与GPT-3的规模相当,并在广泛的基于网络的数据集上进行训练[16],[17],[18],[19]。随后,研究人员提出了几种架构设计和训练策略,这些设计和策略在各种任务上显示出优于GPT-3的性能[15],[14],[20],[21]。
LLMs的性能可以通过指令微调进一步提高,超越了在各种基准测试中预训练的LLMs的表现[22],[23]。LLMs的指令微调指的是在微调阶段引入额外的提示或指令的特定训练方法,以指导输出,从而使用户能够更细粒度地控制LLMs的输出。这些提示可以是自然语言指令,也可以是根据任务需求的示例演示。在文献中,已经为指令微调策略整理了不同的数据集。这些数据集包含更多的实例和任务,进一步提高了对基线的性能[24],[23],[25],[26]。进行指令微调时,需要更新所有的模型参数。然而,参数效率微调采取了不同的方法,只更新少数参数,同时仍然保持良好的性能。这种方法保持原模型不变,而在模型的不同位置添加少量额外的参数[27],[28],[29],[30],[31]。这种方法有助于实现高效的微调,同时最小化对模型总体性能的影响。文献中介绍了采用各种方法的众多预训练和微调模型用于LLMs。一些综述论文提供了LLMs中增强技术的概述[32]。此外,还有一篇全面的评论可供参考,涵盖了架构,微调,新能力,以及LLMs的可用性[33]。另一篇综述提供了基础模型的历史记录[34]。然而,这些评论论文并未深入探讨个别模型的具体细节,只提供了对架构和训练方法的表面理解。相反,我们的论文旨在通过讨论细节,提供更深入的分析单个LLMs。
大型语言模型(LLMs)的架构、训练数据集以及其他颗粒度方面的细节,特别是从历史的角度来看,缺乏全面和详细的讨论,这激励我们进行一项详尽的调查。本次调查旨在对LLMs进行深入且全面的分析,深入探讨其开发、架构、训练数据集和相关组件的细节。
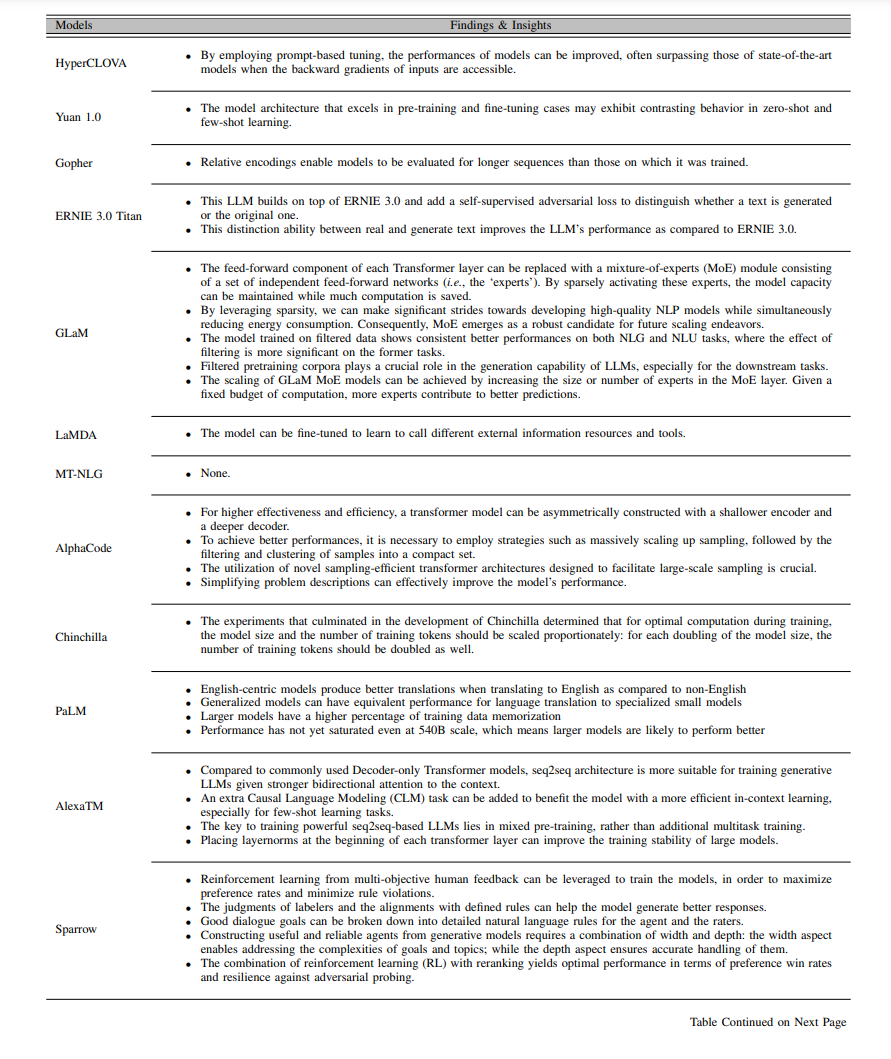
据我们所知,这是第一篇讨论LLMs细节的全面调查论文。 我们对各种LLMs架构及其分类进行了深入分析。此外,我们还讨论了LLMs的基础知识,以使对LLMs不熟悉的读者能够自给自足,从而使论文更具生产力。 我们的论文侧重于为每一个LLM模型提供全面的细节,并涵盖了如架构修改、训练目标、使用的数据集、稳定训练的策略、关键发现、建议以及训练过程中遇到的挑战等方面。 我们的目标是在我们的论文中总结这些关键细节,以帮助研究人员在他们的工作中确定更好的架构和训练方法。
我们的论文补充了一篇关于LLMs的最新综述论文[33],其中涵盖了数据预处理、数据清洗、规模定律、新出现的能力、调整调优和利用等主题。尽管该综述论文提供了关于架构的信息,但并未深入探讨架构变化、训练目标和提出的LLMs的具体发现的细节。我们讨论的LLMs模型的参数至少有100亿个,或者更多,类似于论文[33]。我们的论文中并未讨论小于这个规模的模型。可以参考[35],[36],[32]等综述论文来探索较小的模型。本论文的结构如下。第二部分讨论了LLMs的背景,简洁地概述了构成这些模型的基本构建模块。我们讨论了架构风格、微调策略、库以及分布式训练方法。该部分作为理解后续对LLMs讨论的基础。第三部分重点介绍了LLMs的概览、架构以及训练管道和策略。第四部分提出了每个LLM的关键发现。第五部分强调了在这些模型的功能中起关键作用的配置和参数。在第六部分讨论了LLM的训练和评估基准,然后在结论部分给出了总结和未来方向。