

- 我们呈现了 SpeechLMs 领域的首次综述。
- 我们提出了一个基于底层组件和训练方法的 SpeechLMs 分类新体系(图3)。
- 我们提出了 SpeechLMs 评估方法的新分类系统。
- 我们识别出构建 SpeechLMs 的若干挑战。
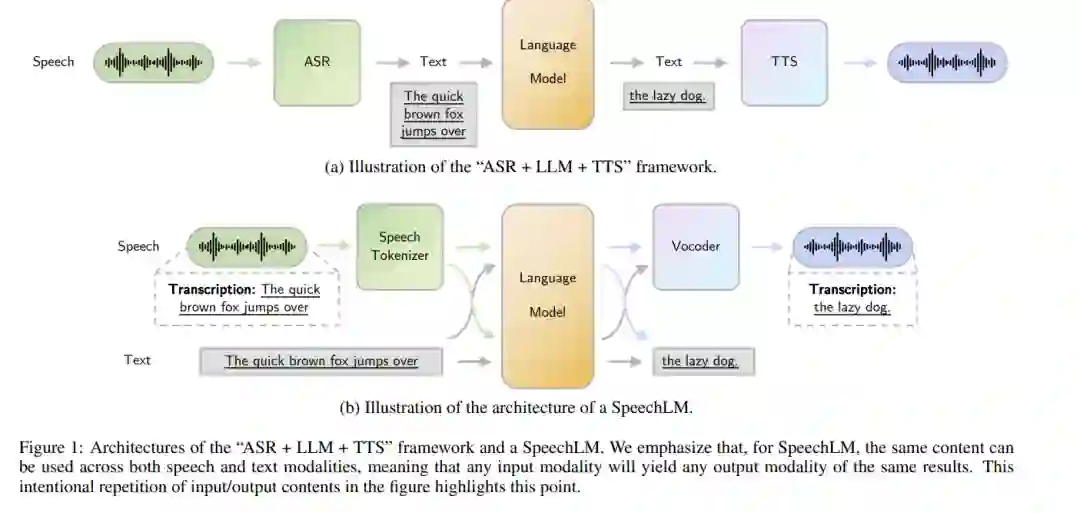
2 问题定义
在此部分中,我们将正式定义语音语言模型(Speech Language Models,简称SpeechLMs)。语音语言模型是一种自回归基础模型,能够处理并生成语音数据,通过上下文理解生成连贯的语音序列。SpeechLMs 支持多种模式,包括语音到文本、文本到语音,甚至是语音到语音,具备上下文感知能力,从而能够执行广泛的任务。与传统的文本语言模型(如 LLM)不同,SpeechLMs 处理的是语音和文本两种模式。这使得 SpeechLMs 能够进行更自然的多模态交互,在同一模型框架内处理多种输入和输出模式,具有更高的应用潜力。
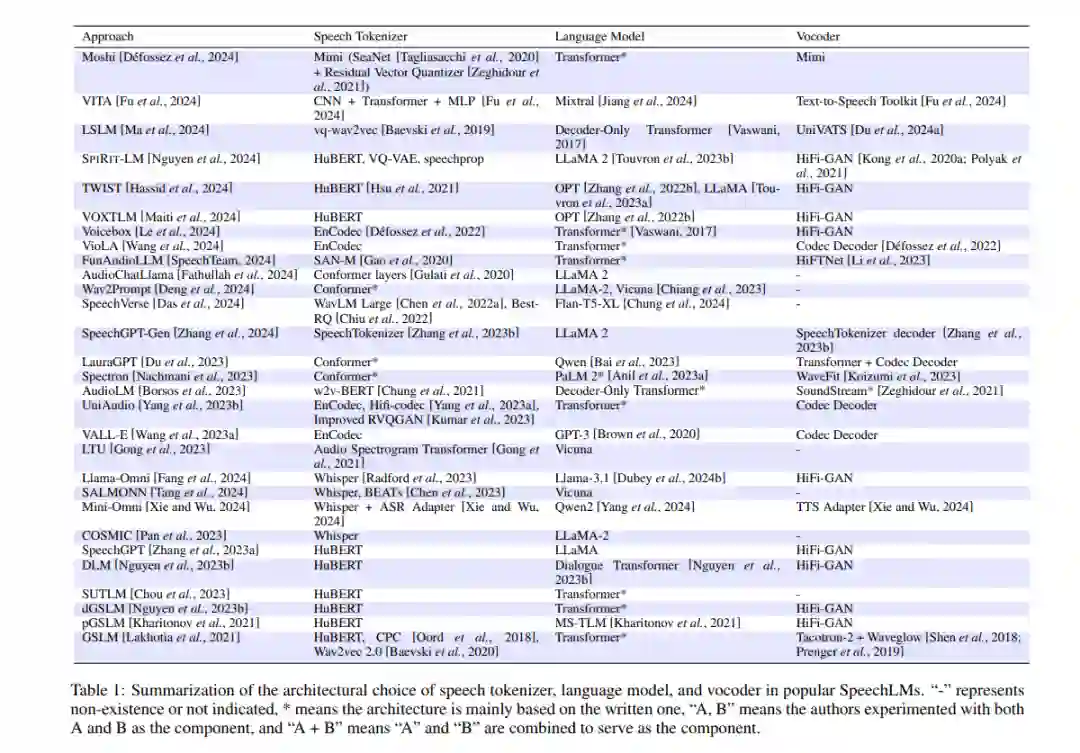
3 SpeechLM的组件
语音语言模型主要包括三个组件:语音分词器、语言模型和语音合成器(声码器),这种三阶段的设计模式的主要原因是使语言模型架构(如仅解码器的 transformer)能够以音频波形的形式自回归地建模语音。由于语言模型的输入和输出都是离散 tokens,因此需要附加模块来处理输入输出格式。下面将详细介绍各个组件:
**3.1 语音分词器
语音分词器是 SpeechLM 的第一个组件,它将连续的音频信号(波形)编码为潜在表示,再将其转换为离散 tokens,使其能够被语言模型有效处理,用于诸如语音识别或合成等任务。语音分词器的核心目标是捕捉音频中的关键特征,同时降低其维度,便于后续对语音模式的建模和分析。 语义理解目标: 设计语义理解目标的语音分词器旨在将语音波形转化为能够准确捕捉语音内容和意义的 tokens。通常情况下,这些分词器包含一个语音编码器和一个量化器,语音编码器对波形的关键信息进行编码,而量化器则将连续表示离散化为离散 tokens。 声学生成目标: 具有声学生成目标的语音分词器注重捕捉生成高质量语音波形所需的声学特征,优先保留关键信号,而非语义内容。为生成高质量的语音波形,这些分词器通常采用包含编码器、量化器和解码器的架构,将原始波形转换为离散 tokens,再通过解码器将其重构回语音波形。 混合目标: 混合目标的语音分词器平衡语义理解和声学生成任务。大部分混合分词器采用声学生成分词器的架构,并侧重于将语义信息从语义分词器提取到声学分词器中。某些系统还利用单独的向量量化器来从语音模型(如 WavLM)提取信息,并结合声学特征模块以提升性能。
**3.2 语言模型
由于文本语言模型的成功,大部分 SpeechLMs 采用了类似的架构,主要使用 transformer 或仅解码器的架构进行自回归语音生成。为适应语音生成,原文本分词器被替换为语音分词器,使模型能够联合建模文本和语音两种模态。通常做法是扩展原文本模型的词汇量以容纳文本和语音 tokens,形成一个更大的嵌入矩阵,从而使模型在单一序列中生成文本和语音。
**3.3 声码器
声码器在语言模型生成 tokens 后将其合成为语音波形,这一过程涉及将生成的语音 tokens 所代表的语言和副语言信息转换为音频波形。声码器通常包括直接合成和输入增强合成两种流程。直接合成方式较为简单,适用于包含足够声学信息的 tokens;输入增强合成则在 tokens 进入声码器之前将其转换为包含丰富声学特征的表示,以生成更高质量的语音波形。
4 训练策略
SpeechLMs 的训练过程分为三个主要阶段:预训练、指令微调和对齐。这一节将主要回顾语言模型组件的主要训练技术。
**4.1 预训练
预训练阶段对语言模型的影响至关重要,因为它能够帮助模型学习语音数据中的统计模式和依赖关系,以便在上下文中预测下一个 token。SpeechLMs 预训练通常使用大规模的开放语音数据集,包括用于 ASR、TTS 和多模态任务的数据集。为了增强语音和文本模态的对齐,部分模型从预训练的文本模型开始进行预训练,并调整以支持语音 tokens,从而加速收敛并提升语音理解性能。
**4.2 指令微调
指令微调通过特定的任务指令来提升模型的泛化能力,使其适应更多样的应用场景。常见的指令微调方法包括多模态指令微调和模态链微调。SpeechGPT 使用指令微调来处理 ASR、TTS 等任务,通过生成包括语音输入、文本输出在内的数据集,进一步提高模型的适用性。
**4.3 对齐阶段
对齐阶段指的是通过特定方法来增强文本与语音模态间的表示对齐。通过交替输入文本和语音 tokens 的方法,可以显著提高模型在语音理解和生成方面的性能。此外,通过将文本和语音版本的提示都用于训练,确保模型能够为两种输入模态生成一致的输出。这样,模型既可以在纯文本环境中运行,也可以在语音模式下自然地响应。
**
**
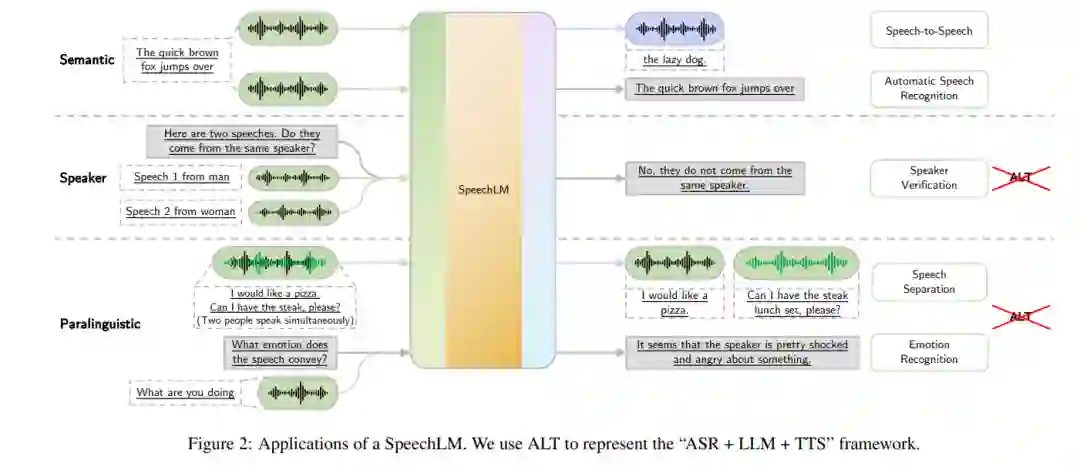
5 下游应用
SpeechLMs 可处理多种下游任务,远超传统的ASR 和TTS系统,它们不仅支持文本与语音的多模态任务,还能处理复杂的语音和文本组合任务。下游应用可分为以下几类:
**5.1 语义相关应用
口语对话:SpeechLMs 可用于口语对话系统,使系统能够在上下文中理解用户意图并生成语音响应。 * 语音翻译:支持语音到文本或语音到语音的翻译任务,SpeechLMs 能够根据不同语言生成对应翻译。 * 自动语音识别:通过ASR将语音转换为文本,是SpeechLMs 最基本的功能之一。 * 关键字检测:用于语音激活的场景,SpeechLMs 可识别并提取特定关键字,从而触发特定操作。 * 文本到语音合成:与ASR相反,TTS从文本生成对应的语音输出,以实现从文本指令到语音的转换。
**5.2 说话人相关应用
说话人识别:能够识别语音中的说话人身份,是一种多类分类任务。 * 说话人验证:判定两段语音是否来自同一说话人,为二分类任务。 * 说话人分离:将音频流分割为不同说话人片段,从而标识出谁在什么时间说话。
**5.3 副语言应用
SpeechLMs 还可以处理语音中的副语言信息,如情感识别、语音分离等任务。通过捕捉音高、音色、说话速度等信息,SpeechLMs 能够识别语音中的情感和态度,使得语音系统能够生成更具情感化的响应。
6 评价与未来研究方向
本综述概述了语音语言模型的关键组成部分、训练方法、下游应用及其在语音生成中的不同表现。未来,SpeechLMs 的研究可以朝以下方向发展: * 增强多模态对齐:进一步提高语音与文本模式的对齐能力,使SpeechLMs 更加适应多种任务。 * 提高实时交互性能:开发具有更高响应速度的模型,支持用户打断等更自然的交互方式。 * 扩展评估指标:目前大多使用传统的语音合成和语音识别指标,对这些模型进行更全面的评估需要结合新指标。
