机器人系统传统上用于制造业中自动化重复任务,如焊接、喷漆和拾放操作。尽管机器人研究取得了巨大进展,传统的装配技能仍然是一个挑战。在大多数情况下,复杂的装配技能仍然严重依赖工程师的专业知识。此外,这些技能在面对新任务或变化时容易失败,例如对象的形状或大小。随着客户对更大产品多样性的需求最近增加,这一点尤为重要。学习方法将在这种背景下变得突出,因为学习将负担从人类转移到机器人。与其试图获得周围环境的精确模型或编程控制器,机器人可以通过经验获取动力学模型或直接学习最优控制策略。
强化学习(Reinforcement Learning, RL)赋予机器人通过与周围环境互动自主找到最优行为的能力。将深度学习模型整合到RL中的方法被称为深度强化学习(Deep Reinforcement Learning, DRL),已在多个领域取得显著成就。然而,当应用于现实世界的机器人操作时,现代深度强化学习算法仍面临许多挑战。首先,机器人系统上的样本获取昂贵且繁琐。加之,无模型深度强化学习算法通常样本效率低下,即它们需要大量样本。其次,现实世界的训练引发安全问题。环境或工程师可能会施加一些约束,机器人必须始终满足这些约束以确保安全。在探索阶段,这些约束难以维持,因为这通常涉及随机动作采样。这两个挑战是阻碍深度强化学习集成到机器人控制系统中的基本问题。
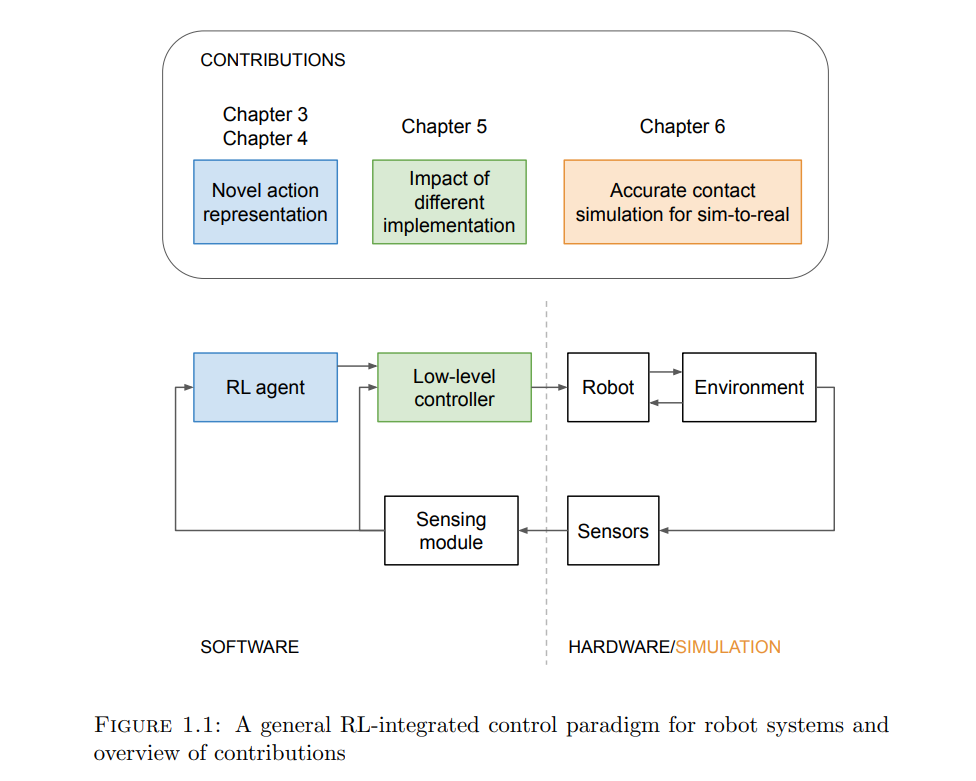
本论文展示了如何可能提高样本效率和实现安全学习,使RL在现实机器人任务中更具实用性。首先,通过使用操控原语(manipulation primitives)作为动作显著提高了样本效率。操控原语既简单又足够通用,可以推广到各种任务。其次,将低层次反馈控制器纳入RL提供了先验知识,可以提高学习速度和策略性能。本研究的一个关键信息是,鲁棒且高性能的低层次控制器可以进一步提高策略的鲁棒性和性能。最后,论文探讨了缩小现实差距的方法,这是模拟到现实强化学习中的基本问题。本研究提出了一种新的接触减少方法,以提高模拟精度,促进复杂装配任务的模拟到现实的转移。