
文 / 节世博,邓志鸿
摘 要:**
**
本文系统介绍将预训练模型应用于计算机视觉领域下游任务的新范式——参数高效微调。参数高效微调通过在微调过程中冻结绝大部分(或全部)预训练模型的参数,只学习(更新)少量参数,来达到与微调模型所有参数相当的性能。这一新的学习范式在训练效率、储存效率、通讯效率上都显著优于传统的微调方法,具有广泛的应用前景。 关键词:
预训练模型;计算机视觉;全量微调;参数高效微调;机器学习
1 背景
随着计算机视觉的发展,基于深度神经网络的方法逐渐成为了计算机视觉各个子领域的主流方法。深度神经网络模型虽然具有强大的拟合能力,但同时也带来了不可忽视的过拟合风险。为了保证神经网络的泛化性能,需要对其在数量足够大的标注数据上进行训练。然而,面向特定视觉任务的大规模标注数据集往往难以获取,使得神经网络在很多场景下无法得到充分训练,其强大的能力难以充分发挥。
虽然获取大量特定任务和场景的标注数据非常困难,但互联网上存在着海量的有标注或无标注的图片数据。这些数据可以帮助视觉模型进行有效的训练,进而提高性能。基于上述理念,先预训练基础模型再微调基础模型以适应特定任务的一种学习范式——“预训练 - 全量微调”被提出来,在计算机视觉领域内各种任务取得了性能上的突破,成为主流的框架。视觉领域中的“预训练 - 全量微调”范式如图 1 所示。其中,“预训练”指的是对随机初始化的神经网络,先使用已有的大量有标注或无标注图片数据集进行有监督或无监督(自监督)的训练来获取一个具有通用性的基础模型。预训练常用到的数据集有 ImageNet、JFT、Object365 等。预训练的方法既可以是有监督也可以是无监督,有监督的预训练利用有标注的数据进行具体任务(如图像分类、目标检测)的训练;无监督的预训练则基于无标注的数据构造代理任务,采用对比学习、掩码图片建模等自监督技术进行模型学习。这里的“全量微调”,指的把预训练后的模型参数作为初始参数,在特定下游任务上的有标注数据集进行训练,进而学习获得针对特定任务的模型。通过“预训练 - 全量微调”范式,预训练后的视觉模型可以有效适应到多种视觉下游任务上,例如分类、检测、分割等。
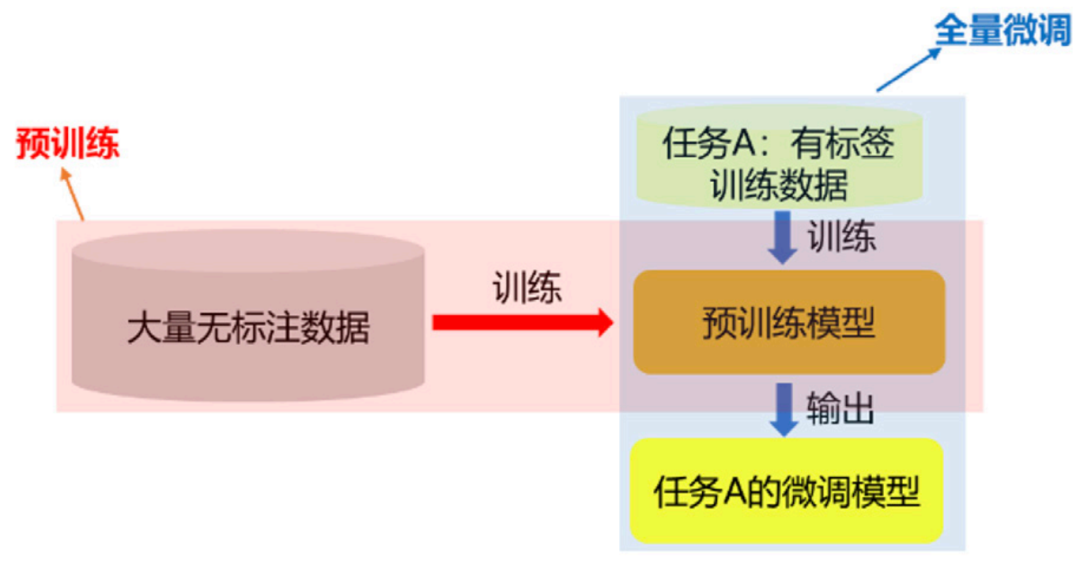
图1 “预训练 - 全量微调”范式
近年来,基于深度神经网络的视觉模型在规模上呈指数增长趋势,从2015年具有6000万参数的ResNet-152,发展到2023年具有220亿参数的 ViT-22B。随着视觉模型参数量的激增,“预训练 - 全量微调”范式在一些应用场景中的缺陷逐渐暴露出来。首先,全量微调造成预训练大模型的所有参数都发生了改变。因此,对于每个下游任务,我们都需要储存一个与预训练大模型大小相当的任务专用模型。在多任务场景或需要模型多版本迭代的场景下,“预训练 - 全量微调”范式需要储存多个规模相当的大模型,造成了很大的储存开销,如图2所示。其次,由于微调后的任务专用大模型的参数量巨大,对大模型进行频繁的跨设备传输将导致大量的通讯开销和显著的通讯时延。最后,对大模型的微调也需要设备具有较大的运行内存,从而限制了大模型在计算资源有限时的使用场景。
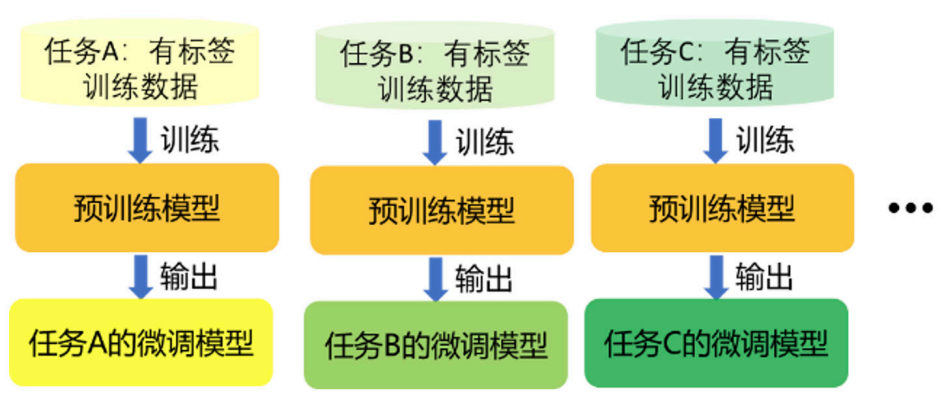
图 2 任务与模型数量
为了解决上述问题,参数高效微调这一新的研究方向被提出,并获得了学术界和业界越来越多的关注。不同于之前的参数微调方法对预训练模型的全部参数进行更新,参数高效微调只更新预训练模型中的少量参数或训练新的少量任务相关的参数,而冻结预训练模型中的绝大部分(或全部)参数。“预训练 - 参数高效微调”范式,如图 3 所示。参数高效微调的基本理念在于假定通过大量视觉数据预训练的模型应该蕴含丰富的通用视觉知识(概念),并且这些通用知识是下游任务所需要的。因此,基于这些通用视觉知识,只需要对模型进行微小的修改,就能够适应到特定的下游任务上并取得很好的效果。
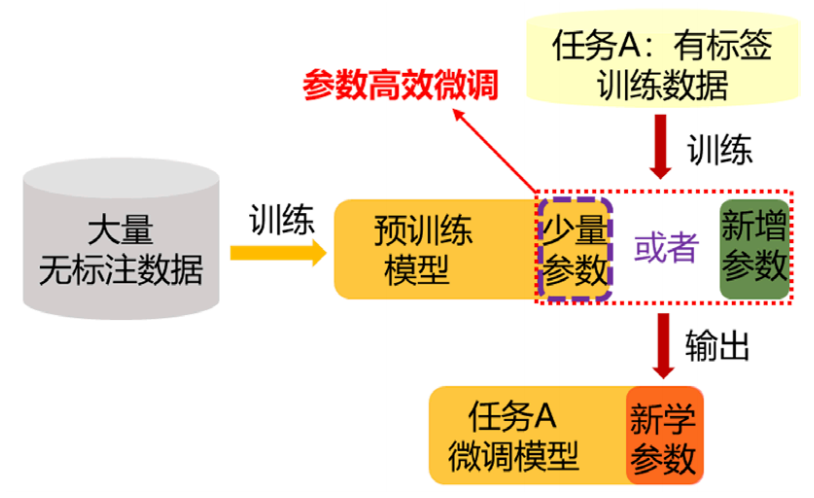
图3 “预训练 - 参数高效微调”范式
参数高效微调具有以下优点。
首先,将预训练模型在一个下游任务上进行参数高效微调,只需要额外储存变化了的参数,而冻结的预训练模型参数则由多个任务共享,这极大地提升了多任务场景下的储存和传输效率。具体可形式化如下,对于预训练模型的参数Θpt,在第k个任务上进行参数高效微调时,所更新的参数为θk。θk可以与Θpt不相交、相交,甚至是Θpt的子集,但θk包含的参数量要远远小于Θpt,即满足 |θk |<<|Θpt |。参数高效微调过程中,Θpt(或 Θpt-θk)保持不变,而θk通过梯度下降更新至θk*。在n个任务上进行微调后,需要储存的参数为 Θpt,以及θ1*,θ2*,…,θn*。由于|θk*|<<|Θpt |,我们可以预计|Θpt |≈|Θpt∪θ1∪θ2∪…∪θn*|,即多任务场景下的储存开销与单任务场景处于同一量级。
其次,在参数高效微调的过程中,只对少量参数进行梯度更新,从而极大减小了参数空间,使得模型优化在一定程度变得更简单和容易,即模型可以更快收敛。较小的参数空间还使得微调后的模型具有更好的泛化性能,在规模较小的数据集上训练能取得比微调全部参数方式更好的效果。
最后,参数高效微调在一定程度上减少了训练过程中的运行内存需求。以全连接层为例,其前向传播过程可以写为 y=Wx 其中,W为全连接层权重(参数);x为输入;y为输出。在反向传播中,需要先将梯度传递到前一层中,因此要计算y对x的梯度:
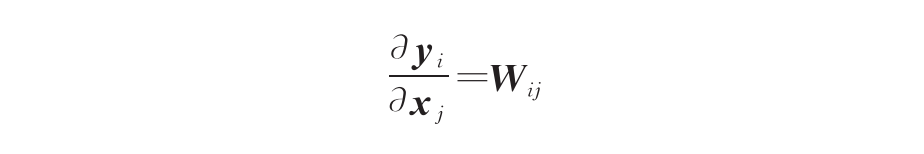
这一过程中只需要使用到权重W。然而,在更新W时,还需要计算y对W的梯度:
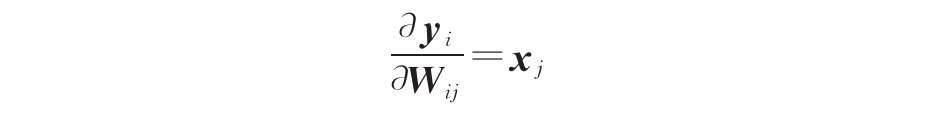
这就要求额外储存x。此外,如果训练过程中使用了动量优化器,如Momentum、Adam等优化W,则还需要储存对W的一阶矩和二阶矩估计。这些矩的规模与W相当。因此,通过冻结大部分(全部)模型参数,可以显著减少微调过程对设备运行内存的需求。
相对于全微调方式,参数高效微调方式的优势明显,使得这一新兴研究方向吸引越来越多研究人员的关注,在计算机视觉的各个领域得到了广泛的应用,展现出巨大的发展潜力和广阔的应用前景。
2 主要方法
根据微调的参数和模块的设计与选取,参数高效微调方法可以被归为基于特征的微调、部分参数微调、基于提示的微调和基于适配器的微调四大类。
2.1 基于特征的微调
基于特征的微调方法,可以追溯到深度神经网络尚未普及的传统机器学习时代。其基本思想是先对数据进行特征工程,提取出有用的特征后,再使用机器学习算法训练分类器对特征进行分类。如果将预训练模型视为一个训练好的特征提取器,用来进行特征工程,则只需要额外训练一个具有少量参数的浅层神经网络即可完成指定的任务。例如,对于分类任务,可以在预训练模型的基础上训练一个线性分类器。但是,当预训练数据集与下游任务数据集的差异过大时,预训练模型提取的下游任务数据特征可能并不具有线性可分性。
考虑一个多层全连接神经网络,其输入为x、权重为w、输出为F(x;w)。令w为修改前权重,w为修改后权重。将F(x;w) 进行泰勒展开可得
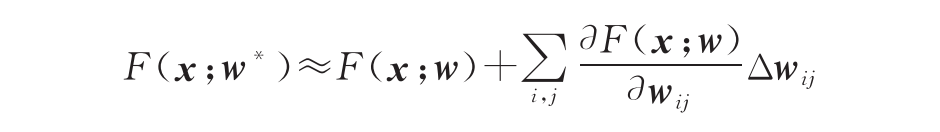
其中 ∆wij=wij*-wij,假设每一层的激活计算可以表示为

其中f为激活函数。则有
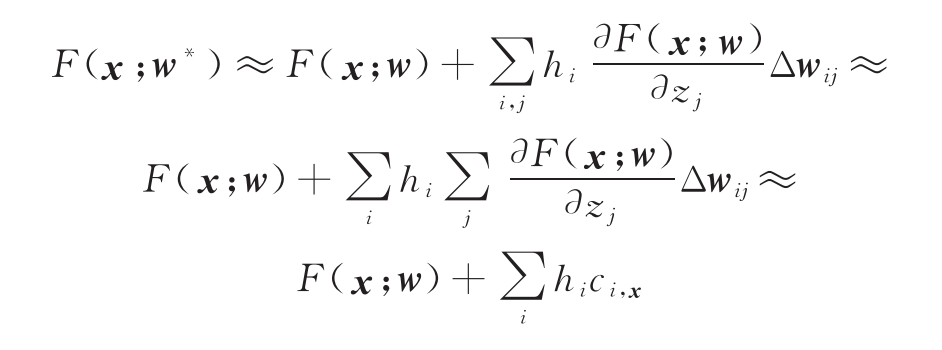
其中hi可视为中间层特征。上式表明,微调过程中网络输出的变化量可以近似为中间各层特征的线性组合。基于上述分析,Head2toe方法假定ci,x与x无关,即中间特征的线性组合系数为常数,可以通过一个训练的线性层进行拟合。因此,在最后一层特征的基础上,Head2toe还利用了预训练模型中间各层输出的特征,将各层特征拼接起来作为总的特征,在其上训练一个线性分类器进行分类。由于总特征的维数过大,为了减少分类器的参数量,Head2toe还通过对分类器进行正则化和剪枝来实现特征选择,删除不重要的特征。
Side-Tuning方法则假设预训练模型提取的特征总体上是线性可分的,对于极少量线性不可分的分量,可以使用一个小的非线性模型进行拟合并消除。Side-Tuning使用了一个可训练的小模型,与预训练模型进行并联,两者的最后一层特征相加作为总特征,并在其上进行分类。由于小模型是非线性的,它能对预训练模型提取的特征进行非线性的修改,从而增加特征的线性可分性。
基于特征的微调方法在很大程度上依赖于预训练模型的质量,即预训练模型提取的特征的可分性越好,基于特征的微调效果也就越好。基于特征的微调方法最大优势在于其不需要对预训练模型提取的特征进行任何修改,因此可以把预训练模型当作黑箱使用,不需要将梯度反向传播回预训练模型,从而能有效减少运行内存开销,并提高微调速度。
2.2 部分参数微调
部分参数微调旨在更新预训练模型本身的一小部分参数,而不添加额外的模块,来达到高效学习参数的目的。这方面代表性的方法包括Diff Pruning、SPT和BitFit等。Diff Pruning方法对预训练权重的增量进行剪枝,使得参数的更新是稀疏的,即只有少部分参数被更新。SPT选择在训练前预先算出需要更新的重要权重,而不是像Diff Pruning一样在训练时裁剪。SPT使用每个训练数据分别计算每个权重元素的梯度,并根据每个权重在所有训练样本上梯度的平方和衡量权重重要性,且只更新稀疏的重要权重。不同于 Diff Pruning和SPT的自动化裁剪,BitFit方法手动选择要更新的参数。具体而言,BitFit方法只更新模型中的所有偏置(bias)参数,从而有效地简化了参数选择的问题。
部分参数微调方法的动机很直观,不会增加新的参数使得部分参数微调的模型与完全微调的模型没有架构上的区别,也不会增加额外的推理计算量。但由于部分微调只能从预训练模型的固有参数中进行有选择性的微调,使其高度依赖于预训练模型的架构。
2.3 基于提示的微调
提示微调来源于自然语言处理任务中的“提示”(prompt)。“提示”最初指的是人手工设计的语言指令模板,用来填补语言模型预训练任务和下游任务在形式上的差距,从而提升下游任务的性能。
VPT和visual prompt是两个典型的,基于视觉提示的参数高效微调方法。VPT使用可训练的 token作为提示。VPT将提示token与patch token和分类token相连接,共同输入transformer层。其 中, 提示token可以只作用于第一层,也可以在每一层之前都拼接新的提示token。由于提示token增加了transformer层输入的序列长度,因此会显著增加计算量。
Visual prompt方法则使用了不同的提示方法。visual prompt使用叠加在图片上的可训练噪声作为提示。由于提示是作用在图片上的,因此其与预训练模型的架构无关,从而可以应用于任何视觉模型,同时不会增加计算量。
2.4 基于适配器的微调
基于适配器(adapter)的微调方法仅对附加在预训练模型上的子模块进行训练,预训练模型的参数是冻结不更新的。这种额外的子模块被称为适配器。由于适配器的设计独立于预训练模型的架构,所以适配器方法也是变种最多,使用最为广泛的一类方法。
AdaptFormer方法使用包含两个全连接层的子网络作为适配器,两个全连接层均包含一个线性激活。由于适配器的隐层维度可以任意指定,使用小的隐层维度即可达到较高的参数效率。AdaptFormer将适配器与视觉Transformer中的前馈神经网络块进行并联,因此遍布模型的浅层与深层。AdaptFormer在预训练模型的基础上增加了额外的结构,因此也会增大模型计算量。
LoRA则使用了一种不同的适配器策略。LoRA在 AdaptFormer的基础上去掉了非线性激活函数,同时将适配器与预训练模型的权重矩阵进行并联。在这种适配器插入方式下,测试时可将适配器与预训练模型的权重矩阵如下所示直接相融合: W=W+AB 从而在推理中不引入额外计算量。此外,LoRA也可以看作是用两个低秩矩阵A和B的乘积对预训练权重矩阵的增量进行拟合。
对于参数高效微调方法而言,如何在保持模型性能的基础上,尽量减少训练参数量是首要的目标。在对完全微调和适配器微调后可训练参数的损失曲面进行可视化后,研究人员发现适配器微调的局部极小值远比完全微调的局部极小值平坦。这也意味着适配器对扰动具有较强的鲁棒性,也就是具有较高的冗余度。因此,可以运用多种技术对适配器进行压缩,从而达到更高的参数微调效率。
为此,Compacter对适配器的权重矩阵进行低秩重参数化,在微调过程中只训练重参数因子。对于每个适配器中的权重W,Compacter将其重参数化为
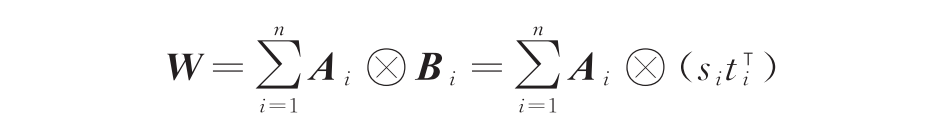
其中Ai为所有适配器共享。在这种重参数化策略下,适配器的空间复杂度由O(Lrd)压缩到了O(L(r+d)),其中L、r、d分别为模型层数,适配器隐层维度和特征维度。
LoRA可以看作是对每个权重矩阵的增量进行低秩分解,而FacT方法则将整个预训练模型的权重增量视为一个整体,将其张量化为一个三维的张量。随后,FacT采用Tensor-Train和Tucker两种技术对权重张量进行重参数化分解,重参数化方法分别为
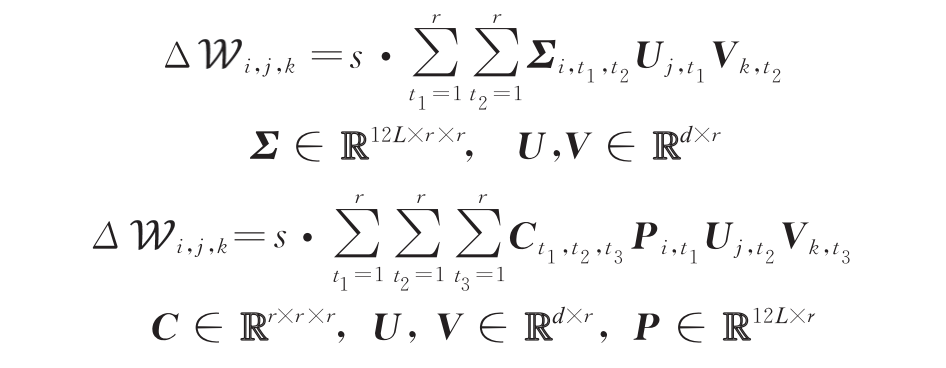
其中,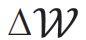
Bi-AdaptFormer和Bi-LoRA方法则对适配器进行了低比特量化。这两个方法结合量化感知训练,在前向传播中量化适配器权重,反向传播时近似量化操作的梯度,训练低比特的适配器。实验表明只用1 bit量化的适配器就足以达到很好的效果,此时适配器中的每个参数的值域只有两个取值。
上述研究工作表明,通过减少适配器中的秩冗余和精度冗余,可以进一步提升基于适配器的参数高效微调方法的效率和效果。
3 视觉参数高效微调的应用
参数高效微调除了直接使用在预训练模型和下游任务上,还可以和其他领域方法相结合以实现更强大的功能。
联邦学习旨在使用分布式的训练方法来保护数据隐私。其基本训练过程如下所述。服务器将训练模型分发给多个数据所有者的客户端,客户端在本地使用私有数据进行微调。每隔一段时间,客户端需要将模型参数发送回服务器,由服务器对所有客户端的模型参数进行聚合,再将聚合后的模型参数分发回客户端,更新客户端本地模型。在这一训练范式下,需要客户端和服务器进行频繁的模型参数传输,当模型参数量较大时,传输的长延迟会显著拖延训练的效率。FiT通过在联邦学习中引入参数高效微调方法,使得每次模型传输只需要传输更新的少量参数,极大地提高了训练效率。
在其他场景下,模型的所有者出于保护自己模型版权和先进性的考虑,可能不愿意将预训练模型开源。作为替代方案,模型所有者可能会公开一个在线的接口,用户上传图片,服务器返回输出。在这种情况下,预训练模型成为了一个黑盒,无法被直接微调。而同时,用户出于数据安全和隐私考虑,也不愿意把数据提交给模型所有者,由模型所有者去微调。
针对以上问题,BlackVIP借助参数高效微调方法,给出了解决方案。BlackVIP使用一个轻量的提示生成器生成图片对应的提示,将提示叠加到图片上输入黑盒模型接口,并根据返回的输出计算损失。BlackVIP再根据损失使用零阶优化方法 SPSA估计提示生成器参数的梯度,即随机采样 Δ,梯度估计为
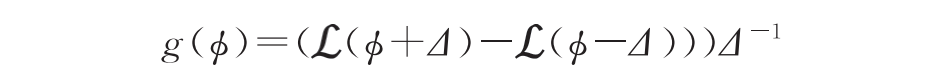
用于更新提示生成器,从而达到微调黑盒模型的能力。
此外,在手机等运行内存受限的边缘设备中,训练模型往往是难以实现的,TinyTL则借助参数高效微调方法缩减了训练模型时运行内存的需求。TinyTL在预训练的卷积模型的主干网络中,只微调bias参数。因为bias的梯度为1,因此不需要储存中间特征。此外,TinyTL还使用了与卷积块并联的适配器来增强模型表现,其中适配器的输入为预训练模型中间层特征的下采样。此时训练适配器所需储存的特征图被压缩成小的下采样特征图,从而减少了运行内存开销。
4 结束语
参数高效微调方法旨在冻结大部分(或所有)预训练参数,微调少部分参数的条件下,实现性能上保持与全参数微调相当。其优势在于模型储存和传输高效、优化过程高效、训练内存高效。目前,参数高效微调已经成为计算机视觉领域新的训练范式,在点云分类、视频分类、扩散模型、通用分割模型、视觉 - 语言多模态模型等方面都展现出优异的能力。然而,由于参数高效微调是建立在非常大的预训练模型之上,其推理的延迟和运行内存开销仍高于完全微调。在未来,参数高效微调将结合更多模型轻量化推理技术,从训练和储存高效发展至推理高效。此外,随着参数高效微调的普及,面向参数高效微调的模型架构和预训练方式也具有很好的发展潜力。
(参考文献略)

节世博
北京大学博士研究生。主要研究方向为预训练大模型微调与推理、多模态预训练大模型及其应用。

邓志鸿
CAAI教育工作委员会副主任,北京大学教授。主要研究方向为深度学习、自然语言理解、预训练大模型及其应用。
选自《中国人工智能学会通讯》 2024年第14卷第1期 科研新范式:All-in-One下的基础模型专题