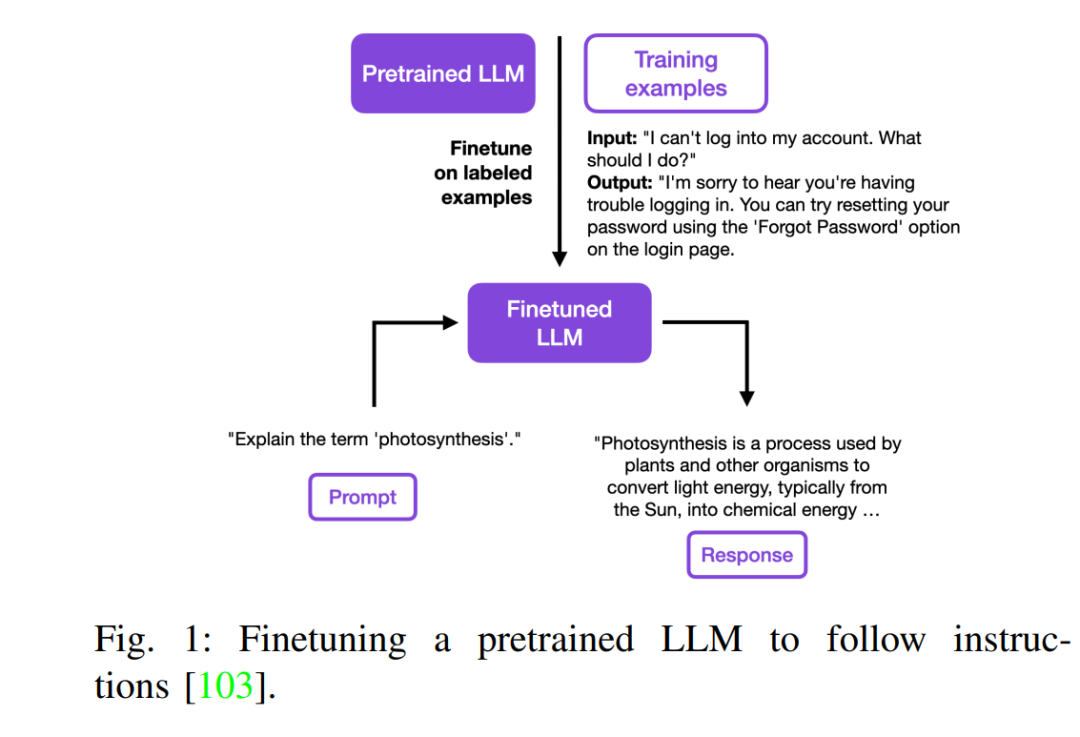
摘要 —— 随着ChatGPT的兴起,大型模型的使用显著增加,迅速在整个行业中脱颖而出,并在互联网上广泛传播。本文是对大型模型微调方法的全面综述。本文研究了最新的技术进展以及在诸如任务适应性微调、领域适应性微调、小样本学习、知识蒸馏、多任务学习、高效参数微调和动态微调等方面应用先进方法。 索引术语 —— 大型语言模型(LLMs)、任务适应性微调、领域适应性微调、小样本学习、知识蒸馏、多任务学习、高效参数微调、动态微调 I. 引言 变换器(Transformer)模型的出现标志着自然语言处理(NLP)领域的一个重要里程碑。变换器架构最初是为了解决循环神经网络(RNNs [143])和卷积神经网络(CNNs [55])在处理长距离依赖关系中的局限而设计的,该架构由Vaswani等人在2017年引入[126],彻底改变了我们处理语言理解和生成任务的方式。 变换器架构背景:变换器模型源于对比传统模型更有效处理序列数据的需求。其独特的架构,不依赖递归和卷积,利用注意力机制来抽取输入与输出之间的全局依赖关系,显著提高了处理效率和模型性能。 编码器[19]、解码器[95] [96] [13]以及编解码器[100]架构:变换器架构主要由其编码器和解码器组成。编码器处理输入序列,创建每个词的丰富上下文表征。相比之下,解码器通常在语言翻译任务中生成输出序列,使用编码信息。 两者的区别在于它们的角色:编码器是输入的上下文感知处理器,而解码器基于编码输入生成预测。编解码器架构常用于序列到序列的任务,结合这两个组件,便于处理复杂任务,如机器翻译,编码器处理源语言,解码器生成目标语言。 大型模型中的微调兴起:微调大型语言模型的概念源于将这些模型从训练于庞大、多样的数据集适应到特定任务或领域的挑战。微调调整模型的权重,针对特定任务,增强其从广泛语言模式到特定应用需求的泛化能力。随着模型规模和复杂性的增长,这种方法变得越来越重要,需要更精细的适应技术来充分发挥其潜力。 本文的结构旨在提供关于微调大型语言模型的方法论和进展的全面概览。后续部分的组织如下: 文献回顾:审视语言模型的发展,突出变换器架构的关键发展和基础概念。 理论基础:深入探讨变换器模型的理论基础,包括注意力机制、编码器和解码器的机制。 微调策略:讨论各种微调方法,如任务特定、领域特定的适应和高级技术,如小样本学习和动态微调。 挑战与未来方向:识别微调方法中的当前挑战,并探索这一迅速发展领域的潜在未来研究方向。 本文介绍了基于变换器架构的大型语言模型的范式,并提供了常用的大模型微调方法的详细概述。文章以一个比较实验结束,聚焦于六个文本分类数据集上的模型大小和LoRA微调范式。实验代码已在GitHub上提供。