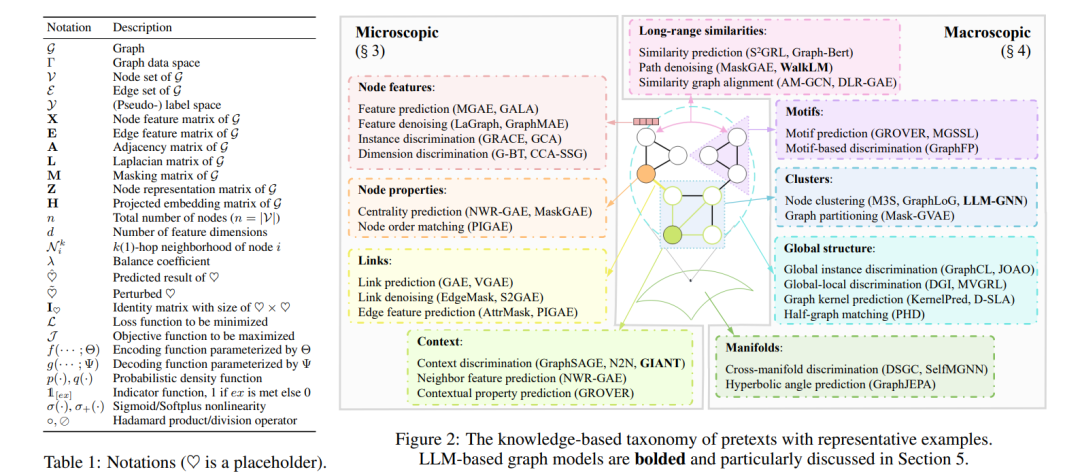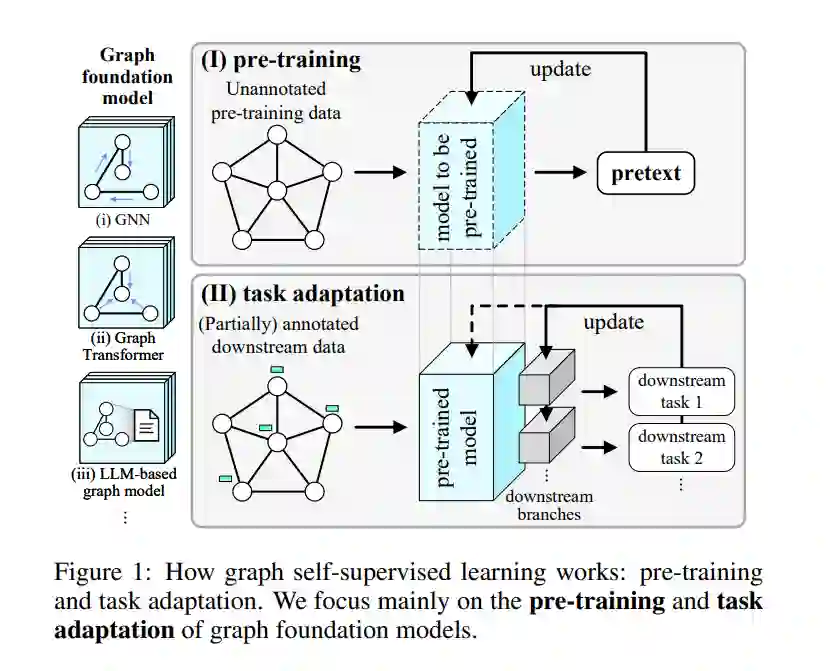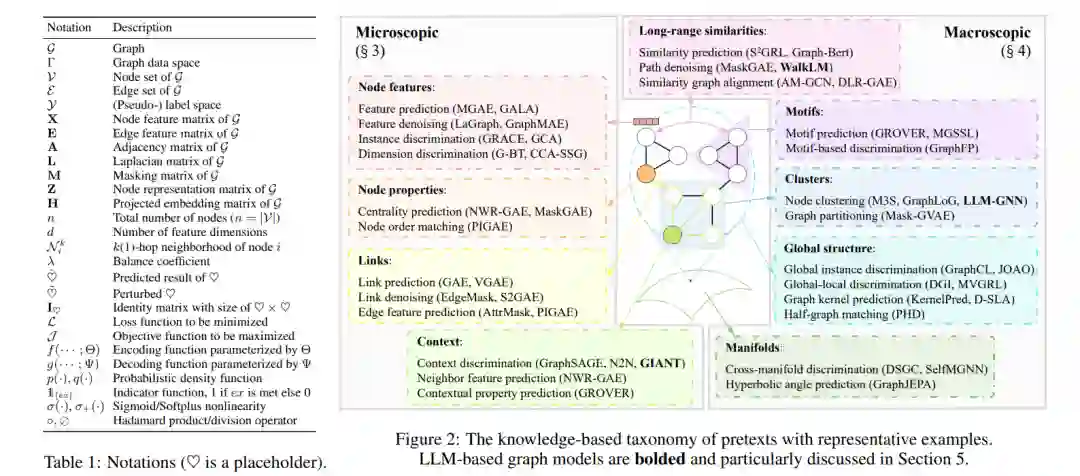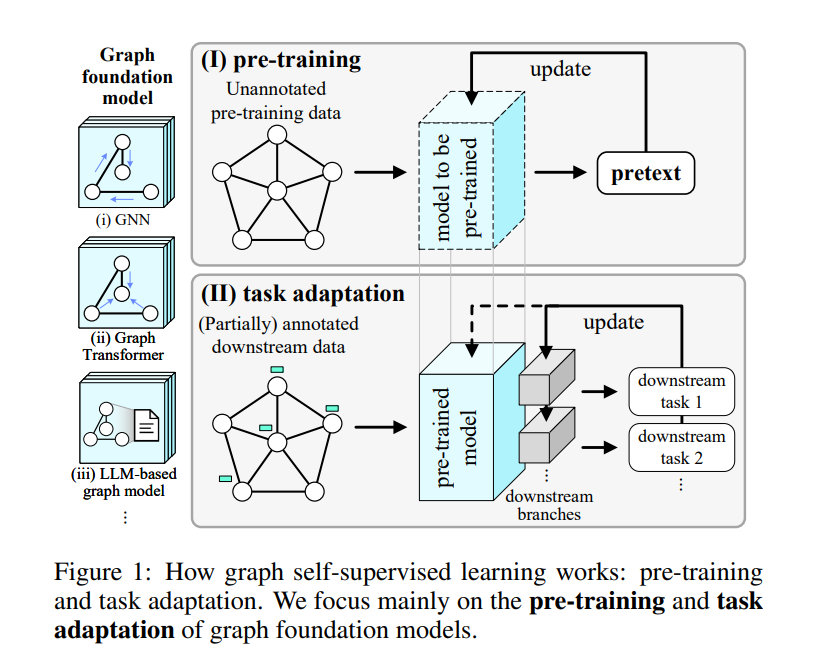
图在各种真实世界的应用中普遍存在,展示出多样化的知识模式[Zhang et al., 2022b]。随着时间的推移,挖掘图的技术已经从网络嵌入发展到图神经网络(GNNs)、图变换器以及更多最近的基于大型语言模型(LLM)的图模型,这些合称为图基础模型[Liu et al., 2023a]。图上的自监督学习(SSL)已经成为一种强大的方法,用于发现大量未标注数据中的潜在模式[Kipf and Welling, 2016; Velicković et al., 2019],如图1所示。为了实现更好的任务泛化性——图基础模型向各种下游任务泛化的关键能力,设计了各种类型的无监督预训练任务,也称为预文本,用于提取隐藏的监督信号以预训练图模型。之后,预训练模型适应于各种应用场景,如节点分类、链接预测和推荐[Wang et al., 2023c]。本文提出了一个全面的综述,关于图基础模型的自监督预训练策略。我们的贡献有两方面。(i) 全面性:据我们所知,这是第一个涵盖所有类型图基础模型的自监督预训练综述,包括GNNs、图变换器和基于LLM的图模型,使得可以进行统一分析以获得更深入的见解。现有的综述在这一领域仅限于一种类型的图模型,如GNNs[Xia et al., 2022c; Xie et al., 2022b; Liu et al., 2022b]或基于图的LLMs[Liu et al., 2023a; Jin et al., 2023],导致了一个不完整且分散的视角,忽略了GNNs和LLMs预训练之间的关系。(ii) 基于知识的视角:现有综述如[Xie et al., 2022b; Liu et al., 2022b; Liu et al., 2023a]广泛地将图SSL方法分类为“生成性(预测性)-对比性”。这种宽泛的分类不足以捕捉图的独特特性,图的结构和属性中嵌入了多样化的知识模式。例如,预测链接的任务需要了解节点之间的局部关系,而预测簇的任务需要了解整个图上节点的分布情况。为了更好地分析不同类型的图自监督预训练策略,我们提出了一个基于知识的分类法,将预训练任务根据所利用的知识类型进行分类,如图2所示:微观知识(第3节)关注于节点级属性和节点之间的局部关系,如链接和上下文子图;宏观知识(第4节)关注于对大部分或整个图产生影响的大规模模式,如长距离相似性和簇。这样的基于知识的分类法提供了一个统一的视角,不仅分析现有图模型的预训练策略,还有最新的基于LLM的图模型(第5节),并探索图基础模型自监督预训练的未来方向(第6节)。它为结合不同方法以创建更具泛化性和强大的图学习者提供了灵感。