

1 引言
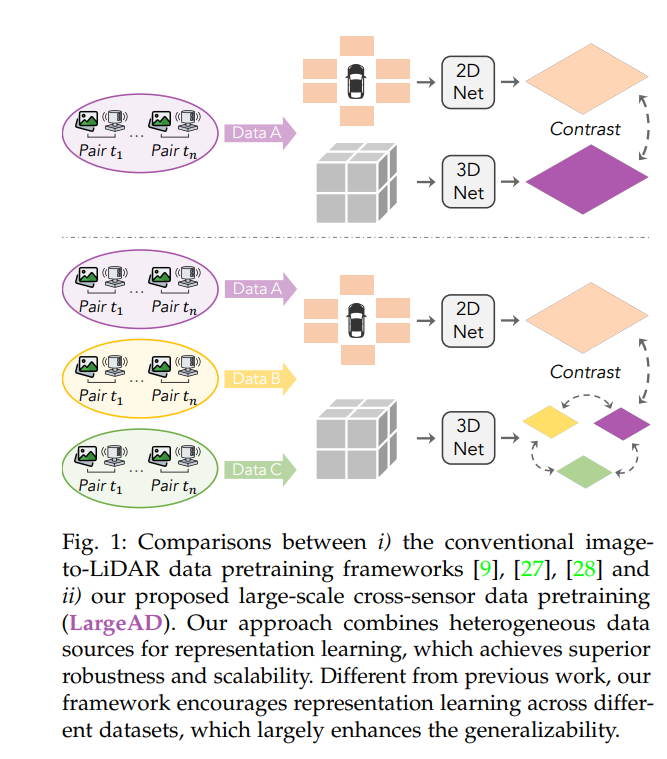
大型语言模型(LLMs)[1]–[5] 的出现彻底改变了自然语言处理领域,同时也为计算机视觉领域的类似突破铺平了道路,例如视觉基础模型(VFMs)中的 SAM [6]、X-Decoder [7] 和 SEEM [8]。这些模型在从2D图像中提取丰富的像素级语义方面展现了卓越的能力。然而,将这些进展扩展到3D领域仍是一个未被充分探索的前沿。随着自动驾驶应用越来越依赖来自LiDAR传感器的3D数据,将VFMs在2D视觉中的成功迁移到3D场景理解中变得愈发重要 [9], [10]。LiDAR点云的精确分割和检测对于安全的自动驾驶和高级驾驶辅助系统至关重要 [11]–[15]。传统的LiDAR点云模型通常依赖于大规模标注数据集,而这些数据集的创建成本高昂且耗时 [16], [17]。为了缓解这一挑战,研究探索了半监督 [18], [19] 和弱监督 [17], [20] 方法。然而,这些方法的泛化能力有限,尤其是在面对多样化的传感器配置时,例如不同的LiDAR光束数量、摄像头位置、采样率以及潜在的传感器损坏 [11], [21]–[25]。这一限制对现实世界的可扩展性提出了重大挑战。为此,我们提出了 LargeAD,这是一个新颖且可扩展的3D场景理解框架,利用跨多种传感器的大规模数据预训练。我们的方法基于跨模态表示学习的最新进展 [6], [7], [26],将VFMs引入3D领域以解决几个关键目标:i) 利用原始点云作为输入,避免对昂贵标签的依赖;ii) 从驾驶场景中提取空间和时间线索以进行鲁棒的表示学习;iii) 确保对预训练数据之外的下游数据集的泛化能力。通过提取VFMs中编码的语义知识,我们的方法促进了复杂3D点云的自监督学习,特别是在自动驾驶领域。我们框架的一个核心创新是利用VFMs从摄像头图像中生成语义丰富的超像素,然后将其与LiDAR数据对齐以构建高质量的对比样本(见图1)。这些语义超像素提供了增强的2D-3D对应关系,捕捉了对象级的一致性,减少了对比学习中常见的过分割和“自冲突”错误 [9]。这种对齐显著提升了下游任务的性能,包括3D目标检测和分割。此外,所提出的框架还引入了多项创新。首先,一种VFM辅助的对比学习策略将超像素和超点对齐到统一的嵌入空间中,解决了图像和LiDAR特征之间的跨模态差异。其次,超点时间一致性机制增强了点云表示在时间上的鲁棒性,缓解了LiDAR和摄像头传感器之间不完全同步带来的误差。最后,我们的多源数据预训练策略利用多样化的LiDAR数据集构建了一个能够适应不同传感器配置的通用模型,进一步提升了可扩展性。如图2所示,与最先进的方法(如 SLidR [27] 和 ST-SLidR [28])相比,我们的框架引入了显著改进:i) 使用语义丰富的超像素解决对比学习中的“自冲突”问题;ii) 创建高质量的对比样本,从而实现了更快且更稳定的收敛;iii) 由于更高效的超像素生成过程,减少了计算开销。总之,本文的主要贡献如下: * 我们提出了 LargeAD,这是一个可扩展、一致且通用的框架,专为车载传感器捕获的大规模数据预训练而设计,解决了多样化LiDAR配置的挑战并提升了表示学习能力。 * 据我们所知,这是首次全面探索跨多个大规模驾驶数据集的预训练研究,利用跨数据集知识增强模型对不同传感器设置和驾驶环境的泛化能力。 * 我们的框架包含多项关键创新:i) 基于VFM的超像素生成以丰富语义表示;ii) VFM辅助的对比学习以对齐2D-3D特征;iii) 超点时间一致性以稳定点云表示在时间上的表现;iv) 多源数据预训练以确保跨领域的鲁棒性。 * 我们的方法在11个多样化点云数据集上的线性探测和微调任务中均展现了显著的性能优势,优于现有最先进方法,展示了其在现实应用中的适应性和高效性。
本文的其余部分组织如下。第2节回顾了自动驾驶数据感知与预训练以及多数据集利用的相关文献。第3节详细介绍了图像到LiDAR对比学习的基础知识。第4节阐述了所提出的大规模跨传感器预训练框架的技术方法。第5节展示了我们方法的实验验证结果。最后,第6节总结了本文并讨论了未来的研究方向。
