摘要—随着数据可用性的扩展,机器学习(ML)在学术界和工业界取得了显著的突破。然而,不平衡的数据分布在各种原始数据中普遍存在,并且通过偏倚决策过程严重影响了机器学习的性能。为了深入理解不平衡数据并促进相关研究和应用,本文系统分析了各种现实世界的数据格式,并将现有研究针对不同数据格式的工作归纳为四个主要类别:数据重平衡、特征表示、训练策略和集成学习。这一结构化分析帮助研究人员全面理解不平衡在不同数据格式中的广泛存在,从而为实现特定研究目标铺平了道路。我们还提供了相关开源库的概述,突出当前面临的挑战,并提出了旨在推动该关键研究领域未来进展的新见解。 关键词—机器学习、不平衡数据学习、深度学习。
I. 引言
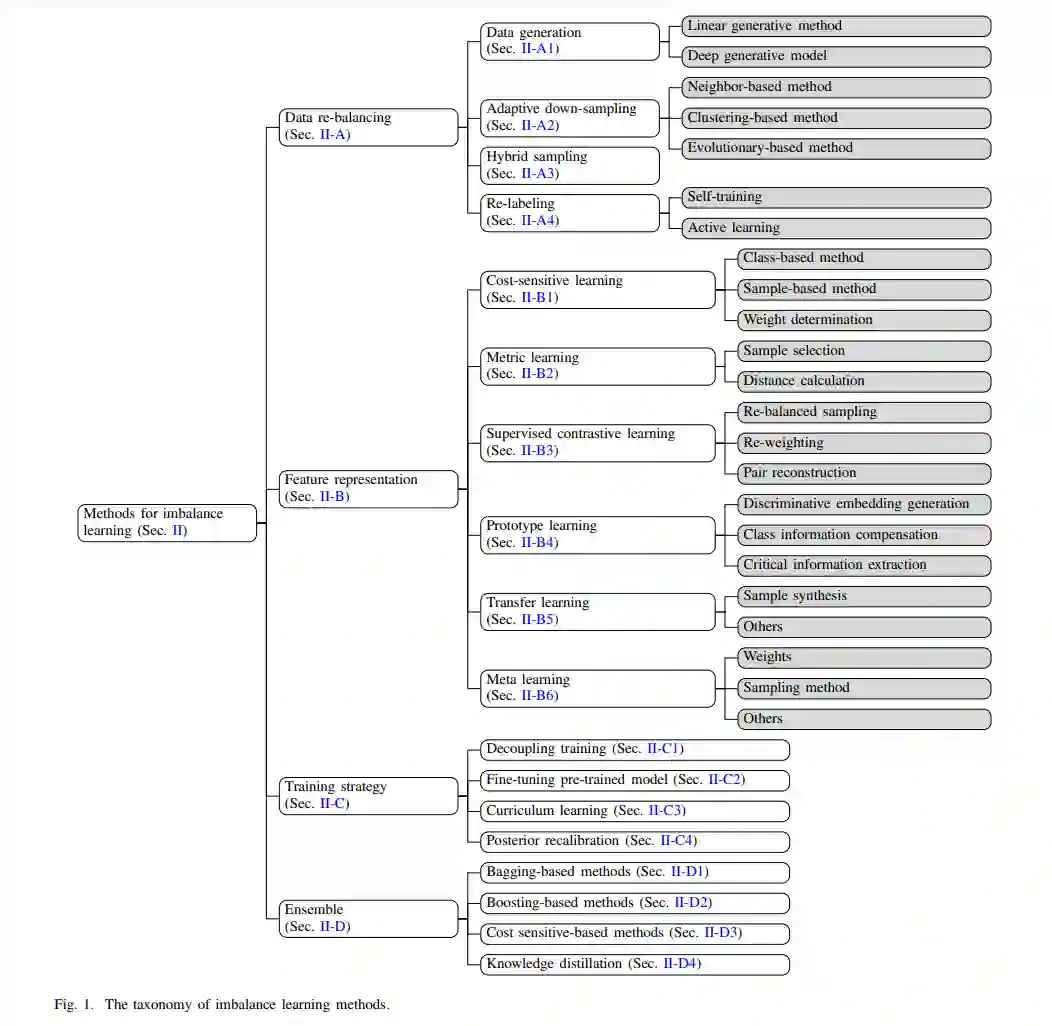
随着数据可用性的扩展,机器学习(ML)已成为学术界和工业界技术进步的前沿。这些机器学习模型被精心设计,以适应特定的数据分布,并随后应用于各种下游任务,从预测分析到自动决策系统。因此,机器学习模型的性能受到训练数据质量和分布的深刻影响。具有代表性、多样化且经过精心预处理的数据确保模型不仅准确,而且在不同的环境和挑战中具有鲁棒性和广泛的泛化能力。 然而,自然数据分布本质上复杂且经常存在缺陷。在这些挑战中,不平衡数据分布尤其突出,反映了各个领域普遍存在和自然产生的差异。例如,在金融领域,欺诈行为的实例相较于合法交易来说相对稀少,这使得模型难以准确地检测这些异常。在医疗领域,稀有疾病在医学数据集中可能被低估,这为开发稳健的诊断模型带来了重大挑战。在工业领域,质量控制系统常常需要识别稀有的产品缺陷,而这些缺陷可能会被大量合格产品所掩盖。这些情境不仅使机器学习模型的训练更加复杂,而且对系统的鲁棒性提出了更高要求。 通常,不平衡的数据分布显著影响机器学习模型的性能和实用性。这些模型通常在高资源组上表现良好,这些组的数据充足,但在低资源组上表现较差,后者的数据稀缺,导致数据分布的界限模糊。因此,尽管机器学习模型可能在整体上表现令人满意,但在这些低资源组中的有效性会显著降低。然而,这些低资源组往往在现实世界的应用中更为重要。例如,在医学诊断中,由于数据不足未能检测到稀有疾病,可能导致漏诊和不充分的患者护理。同样,在金融系统中,无法识别稀有的欺诈实例可能导致重大财务损失和安全性受损。机器学习模型忽视这些稀有但关键的实例,降低了自动决策系统在实际应用中的效用和安全性。 为应对这些挑战,机器学习领域已提出了一系列方法,我们将其组织为四个基本类别——数据重平衡、特征表示、训练策略和集成学习——每个类别都与机器学习过程中的关键环节相对应。数据重平衡技术对于调整数据分布以更好地进行表示至关重要,采用了如过采样少数类和欠采样多数类等方法。这一调整对于防止模型过度偏向多数类样本至关重要,符合机器学习中的数据准备阶段。特征表示策略增强了准确捕捉和表示与少数类样本相关信息的能力。这一改进在特征工程阶段至关重要,使得模型能够有效地从所有样本中学习并做出预测。先进的训练策略调整学习算法,以最小化其对多数类样本的内在偏见。这一训练阶段的关键调整确保了学习过程的包容性,平等地考虑所有样本。最后,集成方法通过组合多个模型,属于机器学习过程中的模型集成部分。这些方法利用多个算法的优势,以潜在地减少由不平衡数据引发的偏差,从而提高最终模型输出的鲁棒性和准确性。通过根据机器学习的基础过程对方法进行分类,这一分类不仅有助于全面的领域调查,还阐明了这些策略背后的动机,帮助实现特定目标。此调查还探讨了不平衡在不同数据格式中的表现,包括图像、文本和图形,突出了每种格式的差异、独特的挑战和所需的适应性。这一探索至关重要,因为它加深了对每种数据格式的理解,并有助于为复杂数据格式场景制定针对性的机器学习策略。 本调查的贡献总结如下:
- 我们提供了关于不平衡数据学习的全面文献综述,系统地概述了基于机器学习基础过程的方法。
- 我们对不平衡在各种数据格式中的表现进行了深入分析,包括图像、文本和图形,提供了每种格式特有的挑战和方法的详细探索。
- 我们突出了可用于解决不平衡数据问题的资源,并探讨了当前面临的挑战和未来的研究方向。这一讨论旨在帮助那些在应对不平衡问题时挣扎的研究人员,帮助他们有效和高效地开发策略。
本调查的结构安排如下:第二节对处理不平衡问题的方法进行了详细调查,并按我们的分类法进行组织;第三节广泛讨论了不平衡在各种数据格式中的表现;第四节对不平衡数据方法的评估指标进行了详细研究;第五节介绍了可用于学习不平衡数据的资源;最后,第六节总结了该领域的挑战与未来发展方向。