【CIKM2019论文】韩家炜团队HyperMine:富文本异构信息网络探索上位词
【导读】富文本的异构信息网络(HIN)现在无处不在,上位词,通常指is-a关系或者subclass-of关系,其作为知识图谱的核心,并且有广泛的应用。现存的方法或利用文本模式来提取上下位词对,或学习术语的分布表示。这些方法依赖于文本库的统计数据,当语料库中的信息不足以满足所有条件时,它们的有效性就会受到阻碍。因此,本文提出富文本的异构信息网络来探索上位词,这样可以获取高质量的文本信息。
本文提出了一个名为 HyperMine的新框架,该框架利用多粒度文本,将文本和网络信息合并,整个过程无需人力。
动机
富文本HIN可以保存所有信息,例如:使用维基百科作为原始数据,这样会丢弃其他结构化信息(如超链接和类型);
输入语料库很小时,因为统计数据少(如共现率和匹配文本模式的机率少),现存的方法无法正常工作。如果链接了该语料库中的文档,可以使用富文本HIN进行建模,然后导出高质量信息,从某种程度上增加了上位发现方法的适用性;
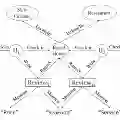
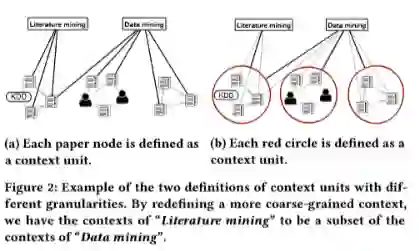
一般的上位词太笼统,文本内容太细,就会出现文本定义不适用于上位词发现,HyperMine通过将”context“重新定义为一组语义相关论文,从而代替单个文章。如figure2中两组图,前者为DIH方法,后者为HyperMine提出的方法:
贡献
提出富文本异构信息网络来获取上位词;
确定了文本粒度对 distributional inclusion hypothesis (DIH)的影响,并提出利用多粒度文本:同时将文本和网络数据信号合并到文本HIN中;
进行多次试验,验证在文本粒度建模的实用性以及在上位词探索中利用HIN信号的有用性。实验中还提出一个案例,该案例表明HyperMine的先进性与实用性。
符号与问题说明
异构信息网络
该网络由一个有向图G构成,G=(V, E))。节点V的映射关系为:φ:V→ T,边E的映射关系为:ψ:E → R。当|T|>1或者|R|>1时,网络称之为异构信息网络(HIN),如果一个HIN中的一部分节点与共同构成语料D的文本信息相关联,则将它称之为富文本的HIN。
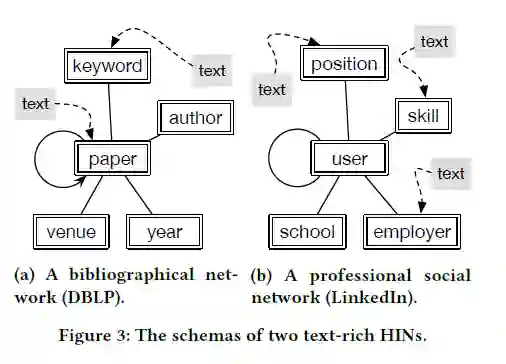
给定HINs的类型,网络模型G=(T,R)用于获取HIN中节点类型和边缘类型的元信息。Figure 3a中说明了DBLP网络的模式,其中论文节点可能有来自内容的其他文本信息,而关键字节点可能与维基百科的描述相关。相似的,Figure 3b中的社交网络包括5个节点类型,这些节点包括技能,雇主和职位等。
目标节点类型和词汇
目标节点T的类型与文本术语相对应,这里把所有术语设置为目标词汇。
在异构目录网络中,DBLP,目标节点类型可以视为关键词,在异构专业社交网络中,LinkedIn,目标节点类型视为技能。
DIH测量中的文本
基于给定的文本C,目标词汇中的每一个术语都有一个相关的分布,术语t与文本单元c∈C,它们的相似度定义为r_c(t)。
另外,定义一个子域,与术语t相关的文本的子域C^(t)={c∈C|r_c(t)≠0}。起初的测量基于DIH:如果t1是t2的上位词,那么 C^(t1)应该包含C ^(t2),下图为DIH的测量,WeedsPrec:
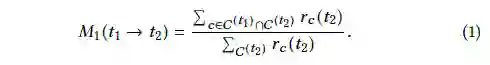
WeedsPrec分数越高,就表明t1是t2的上位词的可能性越大。传统的从语料库中探索上位词的方法,C被定义为同时术语t出现的词的集合。
问题说明
给定一个富文本HIN G=(V,E),目标节点类型T对应目标词汇,HIN的目的是为了找到一系列具有高分数的上位词对。
探索文本粒度
此部分将来说明我们的观察:不同的上位词对对应不同粒度的文本。
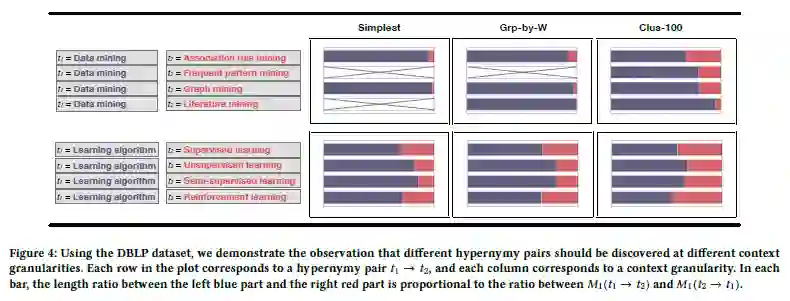
Figure 4中左边每行对应一个上位词对t1 →t2,右边对应3个不同粒度:Simplest,,Grp-by-W和 Clus-100,Simplest有最好的粒度,Clus-100为最粗糙的粒度。右边表中的长度条蓝色表示的t1是t2的上位词的概率,红色表示的t2是t1的上位词的概率。表中没有可视化的是因为M1为0。
从上述表格中可以看出右边最后一列(Clus-100)的结果并不是最好的,比如,”强化学习“与”学习算法“,Clus-100没有很明确判断出哪个是上位词, 在Simplest中就可以很清晰的看到它们之间的关系。导致这样的原因,我们认为是:上位词的普遍性与文本粒度结合在一起,因此,应该在多个粒度中来分析上位关系。
最后,利用HIN作为输入,通过Figure 4中文本粒度解决Figure 2a的DIH问题更容易,这是因为,在HIN中,可以使用explicit network结构(如按照特定节点类型分组或更复杂的结构)来定义语义文本单元。另外,也可以使用网络聚类的方法,通过改变簇的数量,在多个粒度范围内得出文本单元。
Hypermine 框架
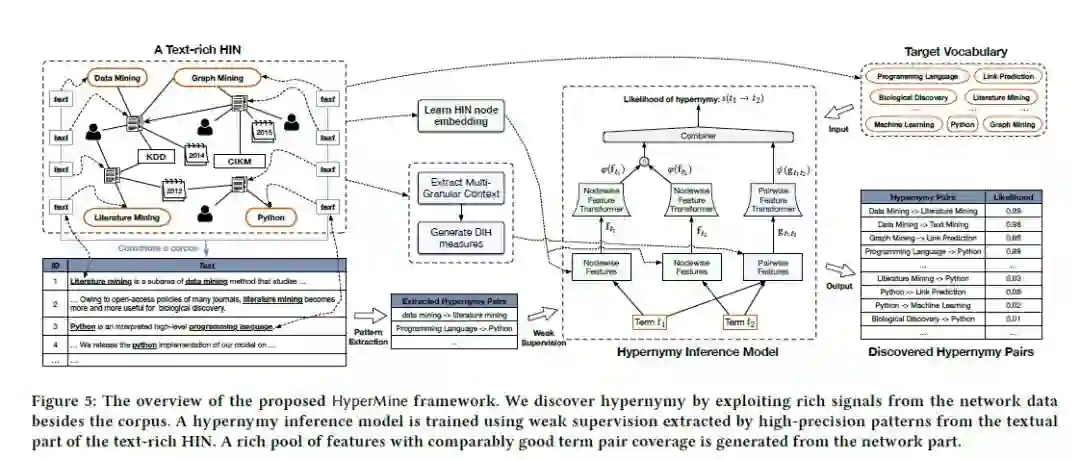
这个模型推测t1与成为t2上位词的可能性,利用高精度模式来获取上位词对,然后用HIN对信息编码并生成多粒度特征。这些特征可以提高召回率。尤其,使用HIN嵌入将网络信号编码为节点特征,并使用DIH在文本粒度上将网络信号编码为成对特征。

弱监督
从富文本的HIN语料库D中获取上下位词对采用弱监督,这种方法已经被证明具有不错的精度,因此我们使用此方法提取列表词对列表S。
节点特征生成
嵌入算法通常就是学习一个嵌入的映射关系f:V→R^d,将节点映射为d维的向量表示。本实验中,用现存的方法来进行嵌入生成特征fv,术语类型,用ft来表示。
特征对生成
对于每个特征对(t1,t2),采用DIH测量中的一个来生成特征,接下来介绍使用不同方法定义的不同粒度的DIH测量方法。
M1(WeedsPrec):
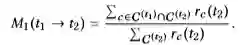
M2(invCL):这种方法不但计算了t1是t2上位词的可能性而且计算了t1不是t2上位词的可能性:
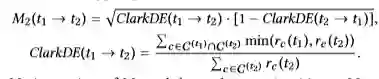
M3是M2的变形:
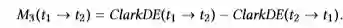
M4是一个对称分布测量,用它来测量术语对的相关性:
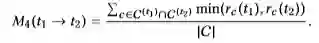
定义HIN的文本的一个简单方法就是把连接到目标类型的节点定义为一个文本单元,用这种方法定义的文本称为Simplest文本。接下来介绍两种方法来定义文本:
通过网络结构定义:HINs中有很多网络结构节点类型,边的类型,元路径以及元图结构,可以设计方法将Simplest文本单元组合成新的文本单元,本篇论文中采用Grp-by-type来将所有文本连接到一个明确类型的节点上。比如说:在DBLP上,一个文本单元就表示有相同作者的所有论文的集合。只要t与原始单元中的至少一个相关,就认为术语t与Grp-by-type中的语义单元相关。
通过网络聚类:采用传统的K均值聚类算法,只要术语t与某聚类中原始单元中的至少一个术语相关,就认为其语义相关。
给定一个术语对(t1,t2),使用HIN测量计算它们的分数,因此特征对g_t1t2的维度就等于DIH测量的数量乘以文本类型的数量。这个研究中,主要关注于HIN信号的研究和文本粒度的使用。
上位词推理模型
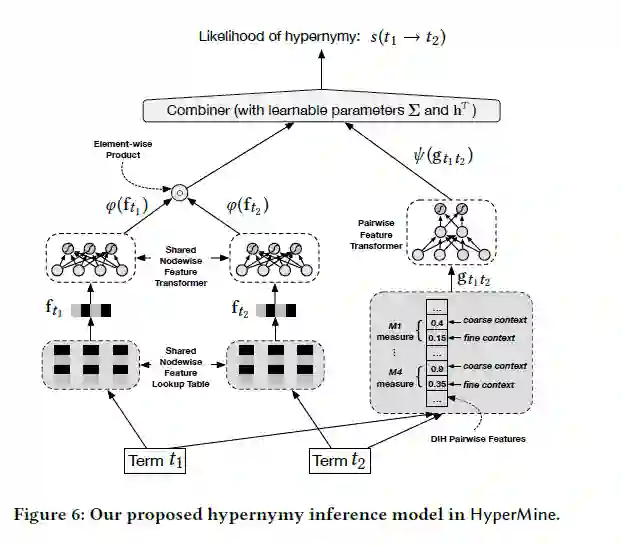
如上图,上位词推理模型主要包括3个组件,分别是:
节点特征转换器 φ,将原始节点特征f作为输入并将其转换为新的嵌入特征;
特征对转换器ψ,基于DIH特征对,并采用2层隐藏层的全连接网络,隐藏层的神经元个数分别为N与N/2,这个转换器可以获得不同文档中的特征对的交互;
整合器:将φ与ψ整合并计算分数:
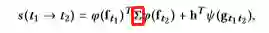
红框表示对角矩阵,h为向量。
为了学习Σ和h中的参数,我们期望上位对的得分高于非下位对。因此,损失函数表示如下:
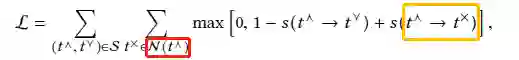
红框表示的是negative术语(t^×)的集合,黄色框不属于S集。
实验
数据集
DBLP:具有5个节点类型:作者(A),论文(P),关键词(W),会场(V)和年份(Y)以及5个边类型:论文的作者身份,关键字用法,发表地点和发表年份,以及论文到另一篇论文的引文关系。
LInkedIn:具有5个节点类型:用户、技能、雇主、学校、职位以及5个边类型:具有技能的用户、工作、上学、担任工作职位、与其他用户建立联系的用户。
方法对比
Hearst patterns:一种传统的上位词探索方法。
LAKI:是一种文档表示方法,该方法首先在最简单的上下文中基于词嵌入(即节点特征)和DIH度量来学习关键字层次结构,然后将文档分配给该层次结构。由于LAKI还同时包含了成对和节点特征,因此我们将其框架与我们的进行比较,以表明我们的上位词推理模型的更高表达能力。
Poincaré Embedding:可以将有向无环图嵌入到双曲空间中,然后使用节点嵌入来预测无环图的更多上位对。
LexNET:依赖路径与分布来预测上位词
HyperMine-wo-CG:HyperMine的简化版,它不对文本粒度进行建模,而是基于文本特征导出DIH测量。
评估指标与参数设置
使用两个精度指标与四个排序指标,精度K为聚类值,其中K∈ {100, 1000},计算方法是将排名最高的K个positive对的对数除以K。四个排序指标分别为:宏观平均倒数排名(MaMARR)、微平均倒数排名(MiMARR)、宏观平均最大倒数排名(MaMLRR)、微平均最大倒数排名(MiMLRR)。
数据集DBLP,使用Grp-by-A, Grp-by-V, Grp-by-W;数据集LinkedIn,使用Grp-by-P, Grp-by-S, Grp-by-U。聚类K分别设置为100与1000。总共有6个不同的文档,乘以4个不同的DIH测量得到24个成对特征。
对于两个数据集,使用HEER学习128维HIN节点嵌入,在弱监督数据集上使用5倍交叉验证对所有方法的超参数进行调整,对于HyperMine的上位词推理模型,其中的一个隐藏层具有256个size作为节点特征转换器。负采样率L=10,φ(·)中的dropout为0.7,ψ (·)中为0.1。
定量分析
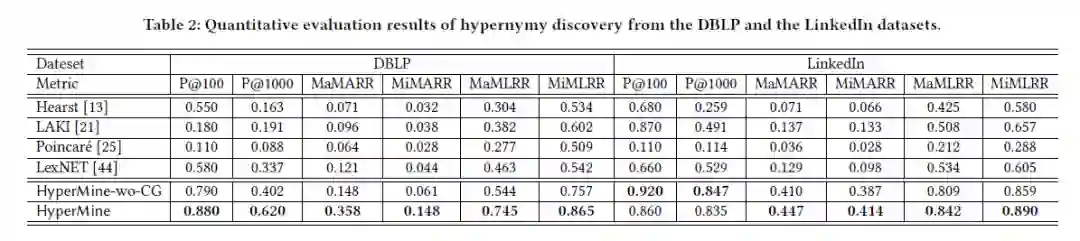

总体而言,HyperMine的方法在两个数据集中所有指标下均大幅度超越了所有基线,而LinkedIn数据集中的P @ 100仅一个例外。HyperMine模型在DBLP中明显优于HyperMine-wo-CG,并且与LinkedIn数据集中的HyperMine-wo-CG相比具有竞争优势。值得注意的是,LexNET在所有基准中都比较出色。但是,它的性能仍然明显不如HyperMine和HyperMine-wo-CG,这证明了在上位词探索中引入网络信号的好处。同样,仅以语料库作为输入,Hearst性能远不及LexNET,相比之下,k取100,LexNET与Hearst类似,而取1000时,明显好一些,这就证实了Hearst倾向于有限的术语对。之所以选择Poincaré作为基线,是因为它代表了一系列与上位相关的研究,并且以图形或网络作为输入。实验结果表示,Poincaré的效果最差,这可能是因为该算法并非旨在从数据中发现上位词,此外,LAKI的性能通常也比其他两种基于HyperMine的模型差,但LinkedIn在K取100时例外。
相同的粒度在不同的数据集中可能具有不同的重要性。在DBLP数据集中,HyperMine明显优于HyperMine-wo-CG,这证明了利用多个粒度的效用。但是,HyperMine和HyperMine-wo-CG之间在LinkedIn数据集中有不同的结果。我们认为这是因为LinkedIn中最简单的文本信息太多,因为每个用户平均链接的技能要比每篇论文链接的关键字多。因此,从其他上下文粒度引入更多功能可能不会显着提高性能。实际上,低质量的噪声特征甚至可能削弱排名靠前的信号对,从而导致精度降低,尤其是在k较小的情况下。这也解释了LAKI在LinkedIn中的更好性能,因为LAKI实际上在最简单的上下文中使用了DIH度量。
同时利用多个粒度中的成对特征可以引入性能提升。在Figure 7中,我们使用DBLP数据集上每个基于网络的DIH功能绘制了评估结果。将Figure 7与Table 2进行比较,可以看出,与每个单个特征相比,使用多粒度特征可以提高性能。这一发现证实了我们先前的观察,即从不同的粒度可以揭示不同的上位词对。
即使在同一数据集中,没有粒度总是最好的。从Figure 7中每个功能的性能可以看出,在所有DIH基本指标下,粒度并不是最好的。例如,当与M1,M2和M3结合使用时,Clus-10000的性能最佳,而在M4的情况下,最简单是最好的。同样,虽然最简单是M4的最佳选择,但与M1和M2结合使用时,甚至比Grp-by-A还要差。
总结
本文我们提出从富文本的HIN中探索上位词,除语料库之外还可以从网络数据中获取信息,实验中我们确定了DIH在不同粒度中的重要性,然后提出HyperMine框架,该框架利用多粒度以及网络和文本信息来解决上位词探索问题。实验证明了HyperMine的有效性以及不同粒度的实用性。