在不确定性下进行的决策序列出现在各种环境中,包括交通、通信网络、金融、国防等。为序列决策问题找到最优决策策略的经典方法是动态规划;然而,由于维度诅咒和建模诅咒,它的用处有限,因此许多现实世界的应用需要另一种方法。在运筹学中,过去的 25 年中,使用近似动态规划 (ADP)(在许多学科中被称为强化学习)来解决这些类型的问题越来越受欢迎。通过这些努力,成功部署了 ADP 生成的卡车运输行业驾驶员调度、机车规划和管理以及制造中高价值备件管理的决策策略。在本文中,我们首次回顾了 ADP 在国防背景下的应用,特别关注那些为军事或文职领导层提供决策支持的应用。本文的主要贡献是双重的。首先,我们回顾了 18 个决策支持应用程序,涵盖了部队发展、生成和使用的范围,它们使用基于 ADP 的策略,并针对每个应用重点介绍了其 ADP 算法的设计、评估和取得的结果。其次,基于所确定的趋势和差距,我们讨论了与将 ADP 应用于国防决策支持问题相关的五个主题:所研究的问题类别;评估 ADP 生成策略的最佳实践;与当前实施的策略相比,设计渐进式策略与彻底改进策略的优势;情景变化时策略的稳健性,例如从高强度冲突到低强度冲突的转变;以及尚未在国防中研究的,可能从 ADP 中受益的顺序决策问题。
关键词:序列决策问题、马尔可夫决策过程、近似动态规划、强化学习、军事
1 引言
许多决策不是孤立地做出的;观察到以前不确定的新信息;鉴于这些新信息,将做出进一步的决策;更多新信息到来;等等。这些类型的决策被恰当地描述为顺序决策问题、不确定性下的顺序决策或多阶段决策问题,其特点是决策对未来获得的回报或产生的成本、未来决策的可行性以及在某些情况下的外生时间对决策的影响[1],[2],[3]。本质上,“今天的决策影响明天,明天的决策影响下一天”[2, p.1],如果不考虑决策之间的关系,那么所取得的结果可能既没有效率也没有效果。
自20世纪50年代以来,人们就知道这种顺序决策可以被建模为马尔科夫决策过程(MDP),它由五个部分组成:一组候选行动;选择行动后得到的奖励;做出决策的历时;状态,即选择行动、确定奖励和告知系统如何演变所需的信息;以及定义系统如何从一个状态过渡到下一个状态的过渡概率[4]。给定一个MDP,目标是找到一个决策策略--"一个规则(或函数),根据现有的信息确定一个决策"[3,p.221],也被称为应急规划、规划或战略[2,p.22]--作出的决策使得系统在给定的标准下表现最佳。寻找最优决策策略的经典方法是通过动态规划(DP)解决贝尔曼的最优方程[5]。在国防背景下,DP已被应用于确定各种连续决策问题的决策策略,包括舰队维护和修理[6]、基本训练安排[7]、研究和开发项目选择[8]、军事人员的去留决策[9]以及医疗后勤资产调度[10]。
尽管DP为解决顺序决策问题提供了一个巧妙的框架,但它在许多现实世界的应用中的作用有限,这一点早已得到认可。这是由于维度的诅咒[5]--"随着变量(或维度)数量的增加,问题的难度异常快速增长"[11]--以及建模的诅咒,即需要一个明确的模型来说明系统如何从一个状态过渡到下一个状态[12]。虽然今天的计算机可以解决有数百万个状态的顺序决策问题[13],但许多问题仍然太大,无法通过经典的DP方法有效解决。此外,通常的情况是,状态之间的过渡概率根本不知道。具有这些特征的顺序决策问题贯穿于整个国防领域,跨越了军力发展、生成和使用的范围。比如说:
-
在军力发展中,关于能力投资的决策可能多达数百项,通常在业务规划周期内的固定时间进行,并且每年重复。决策者必须考虑所选择的投资的短期和长期影响,以及未选择的投资,同时考虑到未来军事合同的不确定性,联盟和对手能力的变化,国防特定通胀,等等。
-
在军力组建中,决定招募多少名军人和军士,以满足各种军事职业的要求,同时尊重国家的授权力度,并考虑到各种不确定因素,包括每年的退休、晋升、自然减员等等;
-
在军力雇佣范围内,在大规模疏散行动中决策,如重大海难期间,将哪些人装上直升机,同时考虑到包括天气变化、个人健康、直升机故障等不确定因素。
由于这些挑战,在这些类型的问题中,通常不可能找到一个最优的决策策略,需要采用其他的方法,重点是找到一个好的或接近最优的策略。第一个方法是由Bellman和Dreyfus[14]提出的,在接下来的几十年里,包括运筹学、控制论和计算机科学在内的各个领域都发展了更多的方法,详细的讨论和相关的参考文献列表见Powell[15]。此外,数学规划领域,特别是随机规划,已经开发了复杂的算法来解决高维决策和状态向量的问题,这在现实世界的顺序决策问题中经常看到[16]。
在运筹学中,这些方法以各种名义被开发出来;尤其是神经动态规划、自适应动态规划和近似动态规划(ADP)。如图1所示,这些方法在过去的25年里越来越受欢迎,从1995年到2021年4月9日,共发表了2286篇文章,年发表率从一篇文章增长到每年近250篇。最近,ADP--"一种在模拟中做出智能决策的方法"[17,p.205],其中 "产生的策略不是最优的,所以研究的挑战是表明我们可以获得在不同情况下稳健的高质量决策策略"[18,p.3]--已经成为更常用的术语[3]。作者们最近也开始使用强化学习这个标签,最近出版的《强化学习和最优控制》一书[19]和即将出版的《强化学习和随机优化:随机决策的统一框架》一书[20]就是证明。值得注意的是,ADP生成的决策策略已经成功部署到工业领域,包括卡车行业的司机调度策略[21],[22],[23], 机车规划和管理[24],[25], 以及制造业内高价值备件的管理[26]。
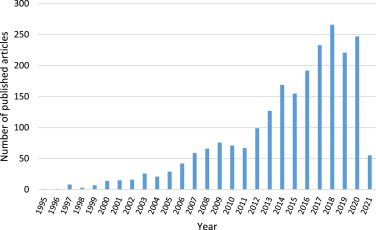
图1. 1995年至2021年4月9日期间每年发表的ADP相关文章的数量。
在这篇文章中,我们首次回顾了ADP在国防背景下的应用。特别是,我们专注于军事运筹学领域的同行评议文献;也就是 "应用定量分析技术为军事[或民事]决策提供信息"[27]。本文的主要贡献有两个方面。首先,我们回顾了18个决策支持应用,这些应用跨越了部队发展、生成和使用的范围,使用了基于ADP的策略,并为每个应用强调了其ADP算法是如何设计、评估和取得的结果。其次,基于所发现的趋势和差距,我们讨论了与将ADP应用于国防决策支持问题有关的五个主题:所研究的问题类别;评估ADP生成策略的最佳做法;与目前实行的策略相比,设计策略是渐进式的,而不是完全彻底的;随着情景的变化,策略的稳健性,如冲突中从高强度到低强度的转变;我们还建议提出国防内部可能受益于ADP生成策略的其他顺序决策问题。
本文的其余部分组织如下。第2节提供了相关的背景信息。第3节介绍了进行此次审查的方法。第4节和第5节是审查的主要内容。第4节回顾了18个已确定的ADP在国防领域的决策支持应用,第5节介绍了与在国防领域应用ADP相关的五个主题。最后,第6节给出了总结性意见。
4. 近似动态规划 (ADP)在军事作战研究中的应用
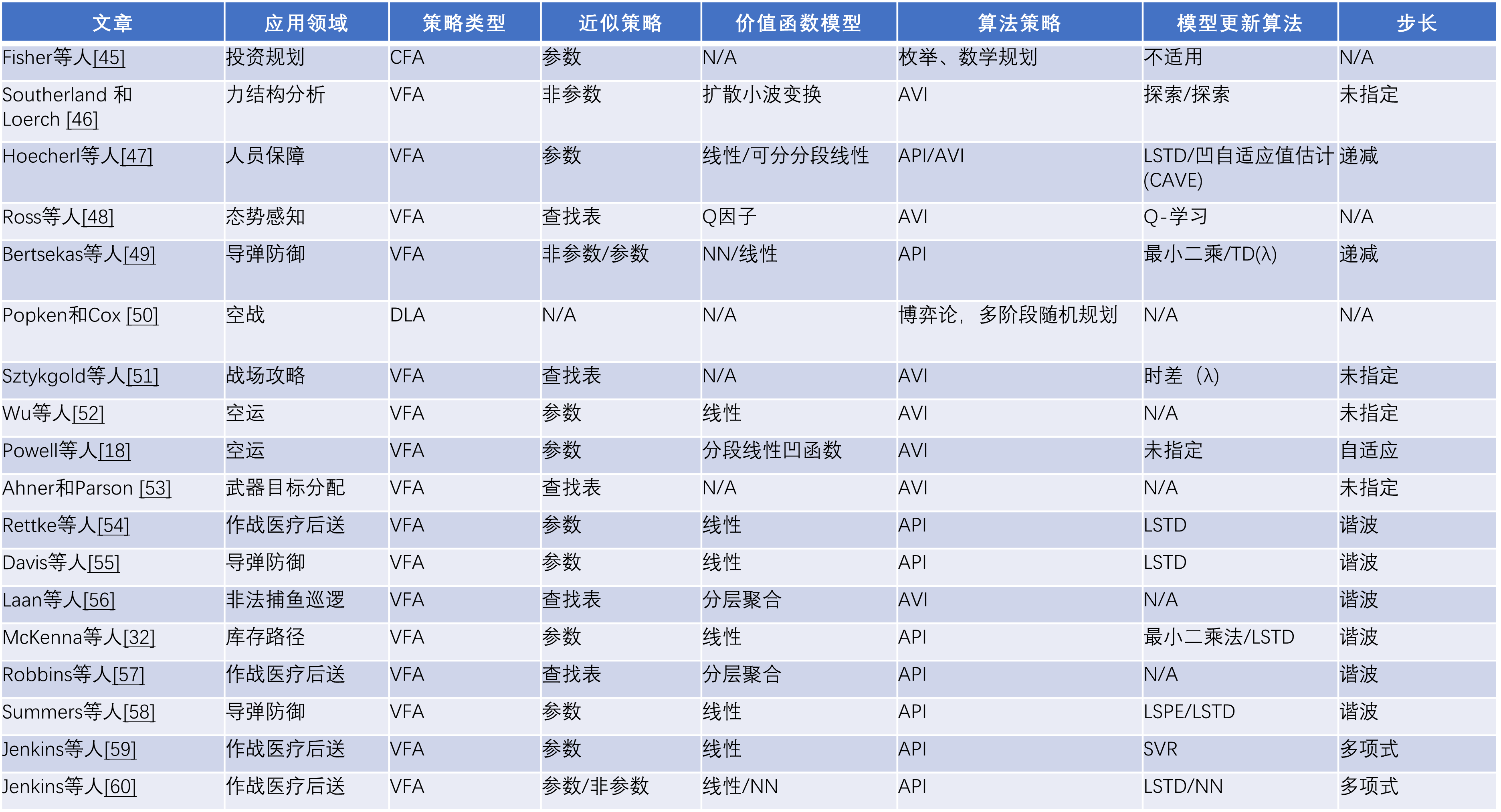
在本节中,我们介绍了通过上述文献搜索确定的18篇基于应用的文章的摘要。表2列出了每项研究,其应用领域,以及所实施的ADP策略和算法的特征。所列的特征主要集中在第2.3节中讨论的那些特征,即:
-
决策策略的类型--短视CFA、PFA、VFA、DLA或混合。
-
价值函数近似策略--查询表、参数化或非参数化。
-
价值函数模型--层次聚合、线性结构、NN等。
-
算法策略-狭义搜索、数学规划、随机规划、AVI、API。
-
更新价值函数模型参数的方法--时差学习、LSTD、LSPE、SVR,等等;
-
步长--常数、广义调和、多项式等。
对于所列出的一些文章,没有提供足够的信息来确定作者是如何处理某些特征的。在这种情况下,该特征被列为未说明。此外,有些文章中的某些特征并不适用。在这种情况下,该特征被列为不适用。下面给出了进一步的细节。研究报告分为三类--军力发展、军力组建、军力使用,然后按时间顺序排列。
表2. 1995-2021年期间ADP在军事作战研究中的应用。文章按横线分为三组:部队发展(上组)、军力组建(中组)和军力使用(下组)。