
来自南京大学的赵鹏博士论文,入选2023年度“CCF博士学位论文激励计划”初评名单!
https://www.ccf.org.cn/Focus/2023-11-29/798503.shtml
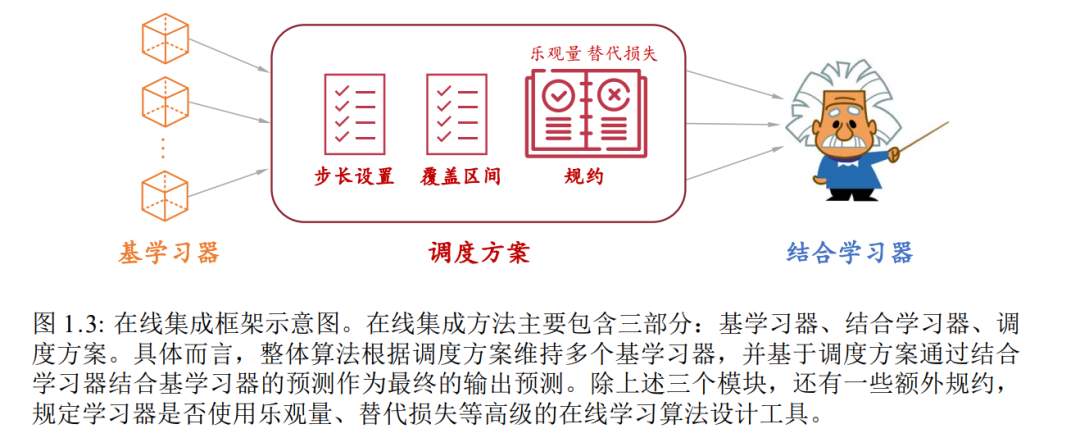
传统的机器学习方法通常假设学习环境静态不变,然而真实世界环境往往 动态变化。特别是在大数据时代,数据不断随时间累积得到,数据分布常常也 不断随时间变化。因此,如何建立对数据分布在线变化环境稳健的机器学习理 论与方法,成为机器学习研究的新挑战。本文提出“在线集成”这一学习框架,用以指导稳健在线学习的理论分析 与算法设计。针对在线学习的四种典型情况,本文在该框架下分别提出相应的 在线集成方法,不仅通过实验验证了性能,并理论证明提出方法在各自对应问 题上分别达到了(当前)理论上所能达到的最优动态遗憾保障,初步建立起稳 健在线学习的一般性解决框架。本文主要工作包括:
- 完全信息在线学习 对学习者可以获得每轮在线函数梯度信息的情况,本文 提出了一种新颖的在线集成方法,通过合理构建基学习器—结合学习器结 构以自适应重用历史梯度信息,总体方法能够有效应对数据分布变化,并 对不同问题实例具有问题相关的性能保障。理论证明了本文方法具有当前 最优的动态遗憾界,实验进一步验证了方法的有效性。
- 凸赌博机在线学习 对学习者无法获得每轮在线函数梯度信息,只能获得单 点/双点函数值信息的情况,本文通过构建替代损失函数以高效利用有限的 信息反馈,设计了一种能够应用到赌博机反馈场景的在线集成方法。本文 首次建立了凸赌博机在线学习问题的动态遗憾理论,该结果在双点反馈模 型已达到理论最优,实验进一步验证了方法的有效性。
- 带噪赌博机在线学习 对学习者无法获得每轮在线函数梯度信息,只能获得 带噪声污染的函数值信息的情况,本文考察线性损失函数,通过最小二乘 法估计未知参数并计算上置信界以选择每轮决策,通过周期性重启机制赋 予学习器处理环境动态变化的能力,并进一步设计双层赌博机的串行在线集成结构以自适应选取最优重启间隔。理论证明了本文方法具有当前最优 的动态遗憾界,实验进一步验证了方法的有效性。
- 决策控制在线学习 对决策控制在线学习这类存在状态转移,学习者决策会 影响未来在线函数梯度及函数值信息的情况,本文考察在线非随机控制设 定,通过分析问题性质将其转化为具有记忆的在线凸优化问题,并设计新 颖的正则化替代损失实现一种具有低转化损失的在线集成方法,从而有效 处理决策控制过程的记忆问题。本文首次建立了在线非随机控制问题的动 态策略遗憾理论,实验进一步验证了方法的有效性。
成为VIP会员查看完整内容
相关内容

Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日