
来自清华大学的董胤蓬博士论文,入选2022年度“CCF优秀博士学位论文奖”初评名单! https://www.ccf.org.cn/Focus/2022-12-08/781244.shtml
以深度学习为代表的人工智能技术在计算机视觉、语音识别等众多领域均取 得了显著进展,规模化应用已现曙光。但现有深度学习模型存在鲁棒性不足的问 题,很容易被攻击者恶意构造的对抗样本欺骗,产生错误的预测结果。深度学习 鲁棒性的不足已被证实会对一些与安全密切相关的领域带来威胁。同时,这一问 题也阻碍了深度学习的进一步发展。
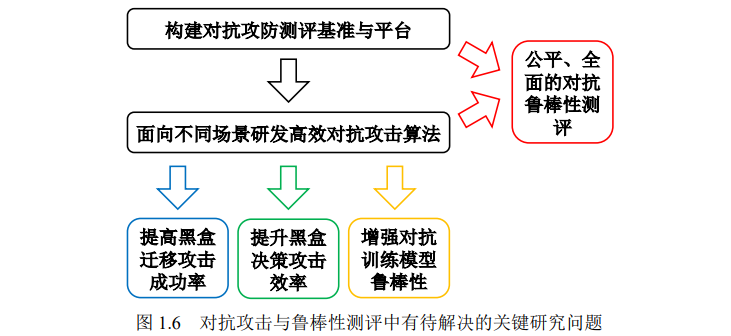
对抗攻击与鲁棒性测评作为深度学习鲁棒性 研究中的重要方向,旨在面向不同场景高效地生成对抗样本并针对深度学习模型 的鲁棒性进行全面的测评。此方面研究有助于发现深度学习模型的脆弱性,比较 不同模型的鲁棒性,以及发展更加鲁棒的深度学习模型。对抗攻击与鲁棒性测评方面的研究仍然存在一些亟待解决的问题。第一,现 有对抗攻击方法在无法获取模型结构和参数信息的黑盒场景下攻击成功率与效率 较低,阻碍了模型脆弱性机理的分析。第二,现有对抗攻击方法生成对抗样本的 多样性不足,限制了基于这些对抗样本训练所得模型的鲁棒性。第三,目前对抗 鲁棒性测评的研究工作较为欠缺,研究者难以有效评估不同深度学习模型的鲁棒 性以及对抗攻防算法的有效性。为解决上述关键问题,本文构建对抗攻防测评基 准与平台,并面向不同场景研发高效对抗攻击算法。
主要创新点概括如下:
- 针对黑盒迁移攻击成功率较低的问题,提出动量迭代法与平移不变对抗攻击 方法,分别通过引入动量项以及对一组经过平移变换的图片生成对抗样本, 大幅提高黑盒迁移攻击成功率,为理解深度学习模型的脆弱性机理及发现模 型的安全漏洞奠定了理论和方法基础。
- 针对黑盒决策攻击效率较低的问题,面向人脸识别场景,提出进化攻击方法, 通过建模搜索方向的局部几何结构和降低搜索空间的维度有效提升黑盒决 策攻击的效率,为挖掘人脸识别模型的安全漏洞奠定了理论和方法基础。
- 针对对抗训练模型鲁棒性不足的问题,提出对抗分布训练,利用对抗分布刻 画原始样本周围多样化的对抗样本,并通过三种对抗攻击方式参数化建模对 抗分布,为构建更加鲁棒的深度学习模型奠定了理论和方法基础。
- 针对对抗鲁棒性测评较为欠缺的问题,面向图像分类任务构建对抗鲁棒性测 评基准,采用鲁棒性曲线针对多个典型的对抗攻防算法进行公平、全面的鲁 棒性测评,为今后对抗攻防模型及算法的开发奠定了测评基础。
成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯