https://www.ccf.org.cn/Focus/2022-12-08/781244.shtml
近年来,深度学习在许多应用领域取得了巨大成功。随着深度学习模型规模 的不断增大,单一计算设备已远远无法满足深度学习模型训练的算力需求。为了 提供强大的算力,利用数据中心内的海量服务器进行分布式深度学习训练已经非 常普遍。然而,为了保证分布式训练结果与单机训练结果的一致性,分布式深度 学习训练系统的不同节点间需要频繁地同步模型参数。许多研究工作和本文的研 究都发现,参数同步所带来的网络通信开销已经成为限制分布式深度学习训练系 统性能的重要因素。
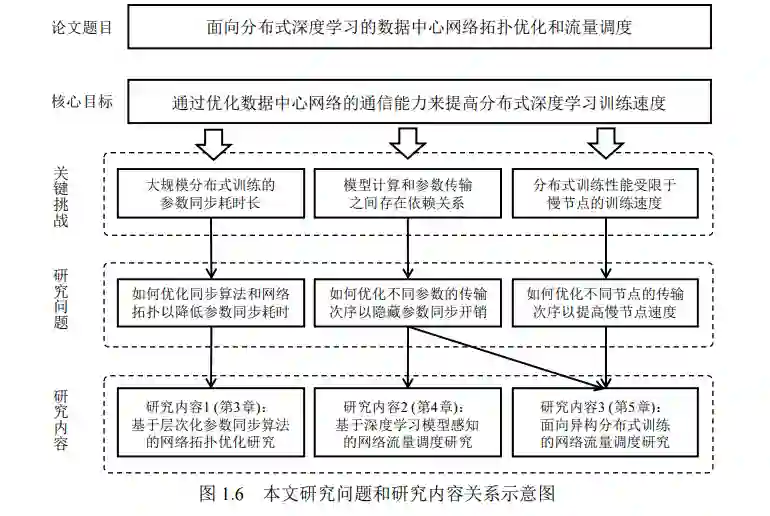
本文通过对参数同步的通信现状进行分析,归纳出分布式深度学习训练面临 的三项主要挑战:(1)大规模分布式训练的参数同步耗时长;(2)模型计算和参 数传输之间存在依赖关系;(3)分布式训练性能受限于慢节点的训练速度。针对 上述挑战,本文从网络拓扑优化和流量调度等方面入手,优化数据中心在支持分 布式深度学习训练时的网络通信性能。本文的主要研究内容和贡献总结如下:
(1)提出了层次化参数同步算法 HiPS,并研究了多种参数同步算法和网络拓 扑组合对参数同步速度的影响。传统的扁平化参数同步算法往往存在带宽竞争或 通信时延累积问题。通过分层同步,HiPS 算法可以在减少参数同步流量的同时避 免上述问题。本文还基于参数同步算法的通信特点对网络拓扑进行了优化。理论 分析和仿真测试均发现,由于服务器带宽更高、负载均衡性能更优并且高效支持 RoCE 协议,HiPS+BCube 组合可以显著降低参数同步耗时。
(2)提出了基于深度学习模型感知的网络流量调度方案 Geryon。现有深度学 习框架在传输多层参数时未考虑其消耗顺序,导致模型计算难以和参数同步重叠。 为了实现全网规模参数传输调度,Geryon 根据模型计算顺序为参数同步流量分配 优先级,并借助全网配置的严格优先级调度策略保证较早被消耗的参数更快到达 接收端。对于多种深度学习模型,Geryon 均取得了显著的端到端训练性能提升。
(3)提出了面向异构分布式训练的网络流量调度方案 CEFS。现有深度学习框 架在向多个计算节点传输参数时未考虑其计算性能,因此慢节点不得不与其他节 点同时开始计算。CEFS 在参数传输调度的基础上,还优先调度慢节点的参数同步 流量,以使其更早地触发前向计算,从而缓解慢节点对分布式系统的阻塞。实验 结果表明,CEFS 可大幅提高慢节点的计算速度,并显著提升端到端训练性能。