

自动生成高质量的真实三维场景对于虚拟现实、机器人仿真等应用具有重要意义。本文提出NeuralField-LDM,一种能够合成复杂3D场景的生成模型。利用了已成功用于高效高质量2D内容创建的潜扩散模型。首先训练一个场景自动编码器,将一组图像和姿态对表示为一个神经场,表示为密度和特征体素网格,可以投影来产生场景的新视图。为了进一步压缩这种表示,训练了一个潜自编码器,将体素网格映射到一组潜表示。然后对隐层进行分层扩散模型的拟合,完成场景生成流程。与现有的最先进的场景生成模型相比,取得了很大的改进。展示了NeuralField-LDM如何用于各种3D内容创建应用,包括有条件的场景生成、场景修复和场景风格操纵。
https://www.zhuanzhi.ai/paper/3b981fab6cbf3eacc2846efadf3f9aec
人们对用于虚拟现实、游戏设计、数字孪生创作等的3D现实场景建模越来越感兴趣。然而,手工设计3D世界是一个具有挑战性和耗时的过程,需要3D建模专业知识和艺术天赋。最近,我们已经看到通过3D生成模型成功地自动化3D内容创建,该模型输出单个对象资产[17,53,85]。尽管向前迈出了一大步,但自动化生成真实世界场景仍然是一个重要的开放问题,并将打开许多应用程序,从可扩展地生成用于训练AI智能体的各种环境(例如自动车辆)到设计现实的开放世界视频游戏。本文提出NeuralField-LDM (NFLDM),一种能够合成复杂真实世界3D场景的生成模型,向这一目标迈出了一步。NF-LDM在一组姿势相机图像和深度测量数据上进行训练,这些图像和深度测量数据比明确的地面真实3D数据更容易获得,提供了一种可扩展的3D场景合成方法。
最近的方法[3,7,9]解决了生成3D场景的相同问题,尽管是在不那么复杂的数据上。在[7,9]中,使用对抗性训练将潜分布映射到一组场景,而在GAUDI [3]中,去噪扩散模型适合使用自解码器学习的一组场景潜。这些模型都有一个固有的弱点,即试图将整个场景捕捉到单个向量中,从而形成神经辐射场。在实践中,我们发现这限制了适应复杂场景分布的能力。最近,扩散模型已经成为一种非常强大的生成模型,能够生成高质量的图像、点云和视频[20,27,45,55,60,85,91]。然而,由于任务的性质,图像数据必须映射到一个共享的3D场景,而没有显式的地面真值3D表示,直接拟合扩散模型到数据的方法是不可行的。在NeuralField-LDM中,学习使用三级管道对场景进行建模。首先,学习一个自动编码器,将场景编码为神经场,表示为密度和特征体素网格。受图像[60]潜扩散模型成功的启发,学会对场景体素在潜空间中的分布进行建模,以将生成能力集中在场景的核心部分,而不是体素自动编码器捕获的无关细节。潜自编码器将场景体素分解为3D粗、2D细和1D全局潜。然后,在三潜表示上训练分层扩散模型以生成新的3D场景。我们将展示NF-LDM如何支持场景编辑、鸟瞰图条件生成和风格适应等应用。最后,我们演示了如何使用分数蒸馏[53]来优化生成的神经场的质量,使我们能够利用从最先进的图像扩散模型中学习到的表示,这些模型已经暴露在数量级更多的数据中。我们的贡献如下: 1)提出NF-LDM,一种分层扩散模型,能生成复杂的开放世界3D场景,并在四个具有挑战性的数据集上取得了最先进的场景生成结果。2)将NF-LDM扩展到语义鸟瞰图条件场景生成、风格修改和3D场景编辑。NeuralField-LDM:分层潜在扩散模型
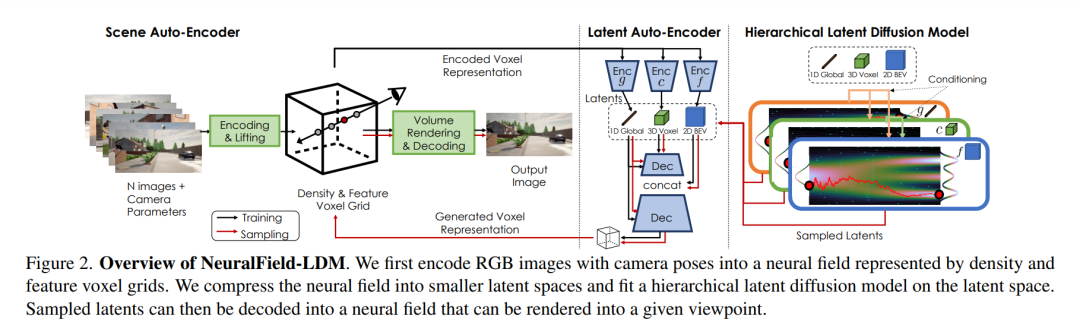
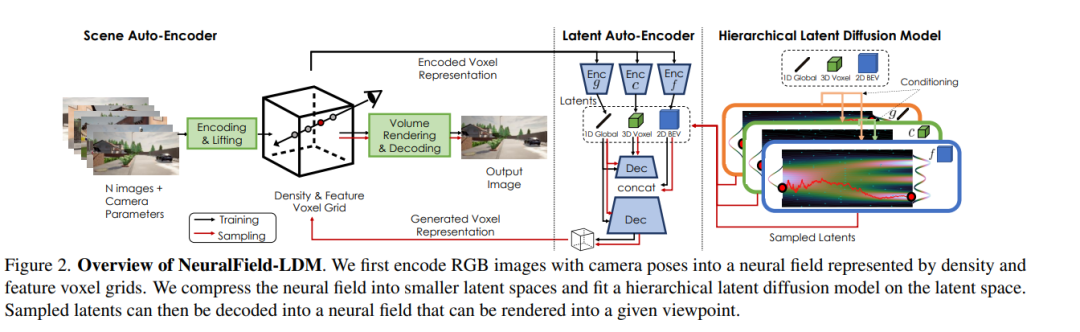
本文的目标是训练一个生成模型,以合成可以渲染到任何视角的3D场景。我们假设访问数据集{(i, κ, ρ)}1..N由N个RGB图像i和它们的相机姿势k组成,以及深度测量ρ,该深度测量ρ可以是稀疏的(例如Lidar点)或稠密的。生成模型必须仅通过从传感器观察中学习,学会对数据集的纹理和几何分布进行3D建模,这是一个非常重要的问题。过去的工作通常用生成对抗网络(GAN)框架来解决这个问题[7,9,66,67]。它们产生一个中间的3D表示,并使用体绘制对给定的视点进行图像渲染[29,49]。然后判别器损失确保3D表示从任何视点产生有效的图像。然而,GANs具有臭名昭著的训练不稳定性和模式丢弃行为[1,18,40]。去噪扩散模型23最近作为GANs的替代方案出现,避免了上述缺点[60,63,64]。然而,DDMs明确地对数据似然性进行建模,并被训练以重建训练数据。因此,它们被用于有限的场景[85,90],因为地面真实3D数据难以大规模提供。为解决生成具有纹理和几何形状的整个场景的挑战性问题,从潜扩散模型(LDM)[60]中获得灵感,首先构建训练数据的中间潜分布,然后在潜分布上拟合扩散模型。在3.1节中,提出了一个场景自动编码器,将RGB图像集编码为由密度和特征体素网格组成的神经场表示。为了准确捕捉场景,体素网格的空间维度需要远远大于当前最先进的LDMs所能建模的大小。在第3.2节中,我们展示了如何进一步压缩并将显式体素网格分解为压缩的潜表示,以促进学习数据分布。最后,第3.3节介绍了一个潜在扩散模型,该模型以分层的方式对潜在分布进行建模。图12显示了所提出方法的概述,我们将其命名为NeuralField-LDM (NF-LDM)。我们在补充中提供训练和额外的架构细节。
三维场景生成
我们展示了来自AVD(真实驾驶)和Carla[1]数据集的合成样本。对于AVD,我们首先得到一个具有合理几何和纹理的粗体素表示,然后用论文第3.4节中描述的后优化步骤进一步优化它。利用分数蒸馏采样(SDS)[2],设计了负面指导来改善场景质量。
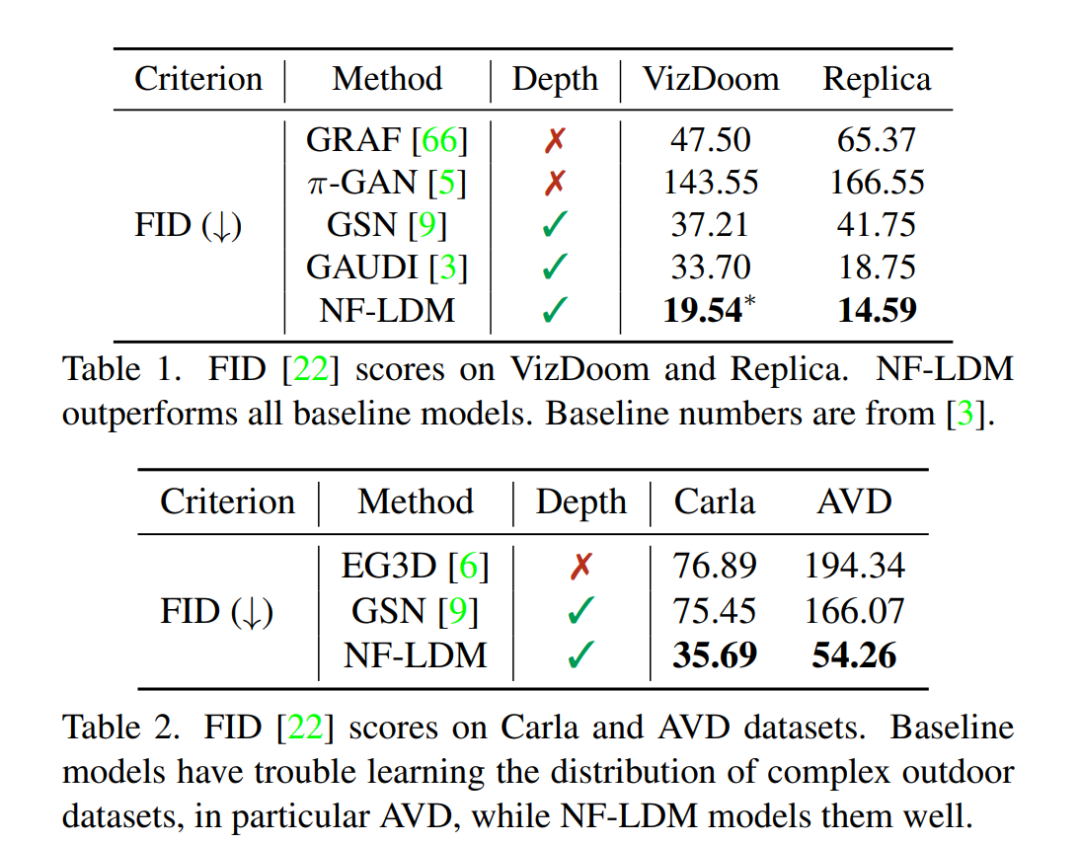
无条件生成通过将NF-LDM与基线模型进行比较,评估了NF-LDM的无条件生成性能。除非特别说明,否则所有结果都没有优化后步骤(第3.4节)。表1显示了在VizDoom和Replica上的结果。GRAF[66]和πGAN[5]在训练中没有利用真实深度,它们在对单个物体进行建模方面取得了成功,但它们比其他利用深度信息对场景进行建模的方法表现出更差的性能。GAUDI [3]是一种基于自解码器的扩散模型。他们的自动解码器优化一个小的逐场景潜函数来重建其匹配的场景。GAUDI 的优点是学习生成模型很简单,因为它只需要对作为对应场景的关键的小维潜在分布进行建模。相反,NF-LDM是在显式3D神经场分解的潜神经上进行训练的。因此,GAUDI 将更多的建模能力放在了自动解码器部分,NF-LDM将更多的建模能力放在了生成模型部分。将比GAUDI 的改进归功于表达性分层LDM,可以更好地建模场景的细节。在VizDoom中,只存在一个场景,每个序列包含数百个步骤,覆盖场景中的大片区域,我们的体素不够大,无法进行编码。因此,我们将每个VizDoom轨迹分块为50步长。

图6. 生成的场景:前三行是来自Carla的样本,后三行是来自AVD的样本。
表2显示了复杂户外数据集:Carla和AVD的结果。并与EG3D[6]和GSN[9]进行比较。两者都是基于GAN的3D生成模型,但GSN利用了ground truth深度测量。请注意,我们没有包括GAUDI [3],因为代码不可用。NF-LDM取得了最好的性能,而两种基线模型都难以对真实户外数据集(AVD)进行建模。图6为不同模型的样本对比。由于数据集由帧序列组成,我们可以将其视为视频,并进一步使用Frechet的视频距离(FVD)[77]进行评估,以比较数据集和采样序列的分布。这可以通过移动摄像机的渲染序列的自然程度来量化样本的3D结构。对于EG3D和GSN,我们从数据集中随机采样一个轨迹,对于NFLDM,我们从全局潜扩散模型中采样一个轨迹。从表3可以看出,NF-LDM取得了最好的效果。根据经验观察,GSN有时会产生略有不一致的渲染,这可能是由于其FVD分数低于EG3D。还通过在密度体素上运行marching-cubes[43]来可视化NF-LDM样本的几何形状。图7显示了我们的样本产生了一个粗糙但真实的几何图形。
有条件的合成。NF-LDM可以利用额外的调节信号进行可控产生。本文考虑了鸟瞰图(BEV)分割图,但该模型可以扩展到其他调节变量。使用交叉注意力层[60],已被证明对条件合成是有效的。图28显示了NF-LDM忠实地遵循给定的BEV图,以及如何对图进行编辑以实现可控合成。

场景编辑。图像扩散模型可以用于图像修复,无需对任务进行显式训练[60,72]。利用这一特性,通过对3D粗潜c中的一个区域进行重采样来编辑3D中的场景。在每个去噪步骤中,对要保持的区域进行噪声处理,并与被采样的区域连接起来,并将其传递给扩散模型。我们使用重建指导[27]来更好地协调采样和保留的区域。在我们得到一个新的c后,还以c为条件重新采样精细潜函数。图11显示了NF-LDM在场景编辑中的结果。

Post-Optimization。图10显示了后优化(第3.4节)如何在保留3D结构的同时提高NF-LDM初始样本的质量。除了提高质量之外,我们还可以通过使用所需的属性对图像上的LDM进行调节,来修改场景属性,例如一天中的时间和天气。基于sds的风格修改对于具有所需属性的干净图像数据集,并且相当接近我们数据集的领域(例如AVD的街道图像)的更改是有效的。在补充中,还提供了方向性剪辑损失[16]的实验结果,以快速微调给定文本提示的场景解码器。

局限性。NF-LDM的分层结构和三级管道允许我们实现高质量的生成和重建,但它会降低训练时间和采样速度。在这项工作中,神经场表示基于密集的体素网格,当扩散模型变得更大时,体渲染和学习扩散模型变得昂贵。因此,探索交替稀疏表示是一个有希望的未来方向。所提出方法需要多视图图像,这限制了数据的可用性,因此在过拟合的生成建模中存在普遍的问题。例如,我们发现AVD的输出样本多样性有限,因为数据集本身记录在有限的场景中。
结论
本文提出了NeuralField-LDM (NF-LDM),一种用于复杂3D环境的生成模型。NF-LDM首先将输入图像编码为3D神经场表示,并进一步压缩为更抽象的潜在空间,从而构建一个具有表现力的潜在分布。所提出的分层LDM适用于潜空间,在3D场景生成方面实现了最先进的性能。NF-LDM实现了一系列不同的应用,包括可控的场景生成和场景编辑。未来的方向包括探索更有效的稀疏体素表示,在更大规模的真实世界数据上进行训练,以及学习持续扩展生成的场景。

