无需多视图!Google重磅升级NeRF:仅需一张平面图即可生成3D模型
![]()
新智元报道

新智元报道
【新智元导读】NeRF最大的弊端被攻克!
人类视觉中,有一个很重要的能力就是可以从二维图像中理解图像的三维形状。
理解三维几何对于了解物体和场景的物理和语义结构至关重要,但当下计算机的视觉仍然很难从二维照片中抽取出三维几何信息。
2020年,神经辐射场(NeRF)模型发布,仅根据二维图像即可生成三维模型,不过缺陷也很明显:模型需要同一个场景(scene)的多个视图(views)作为监督学习的输入。
如果多视角数据不足,模型就无法估计体积表征,生成的场景很容易崩溃成平面,这也是NeRF的主要瓶颈,因为真实场景中多视角数据很难获得。

曾有研究人员设计了一些不同的架构,通过结合NeRF和生成对抗网络(GANs),使用判别器来保证多视图的一致性,可以缓解对多视图训练数据的需求。
还有没有更激进的方法,只用单视图来生成三维模型?
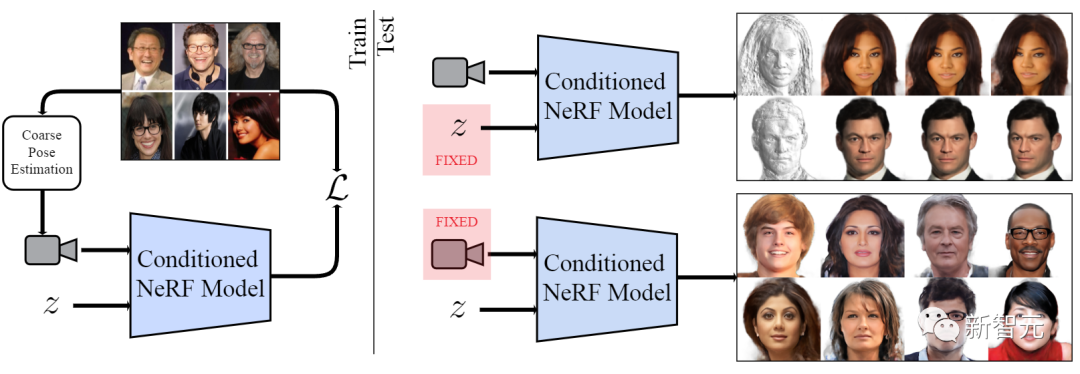
最近,来自英属哥伦比亚大学,西蒙菲莎大学和Google Research的研究人员发表在CVPR 2022上的一篇论文中提出了一个全新模型LOLNeRF,对于同一类物体来说,仅需单一视角即可训练NeRF模型,而无需对抗监督。一旦共享的生成模型训练完毕,模型即可提供近似的相机姿态(camera poses)。

论文链接:https://arxiv.org/abs/2111.09996
简而言之,NeRF不再需要多视图,并且相机也无需非常精确就可以达到令人信服的效果。

具体来说,LOLNeRF使用预测的二维landmarks将数据集中的所有图像大致对齐到一个典型的姿态,以此来确定应该从哪个视图渲染辐射场以再现原始图像。
对于生成模型部分,LOLNeRF采用了一个自解码器框架。为了提高通用性,研究人员又进一步训练两个模型,一个用于前景,即数据集中常见的物体类别;另一个用于背景,因为背景在整个数据中往往是不一致的,因此不太可能受到三维一致性偏差的影响。
值得注意的是,该方法不需要在训练时渲染整个图像,甚至不需要渲染patch。在自解码器的框架内,模型从数据集中重建图像,同时为每个图像找到最佳的潜表征。目标函数基于单个像素定义,因此可以用任意尺寸的图像进行训练,而不会在训练过程中增加内存使用量。
相比之下,现有的利用GANs的方法通过判别器监督像素间的关系,极大地限制了模型在图像分辨率的伸缩能力。
GLO+NeRF打破多视角需求
GLO+NeRF打破多视角需求
GANs过去一直是图像生成的标准模型,其成功可以归因为两点:
1、解决了困难的鞍点优化问题,可以解释为生成器和判别器之间的对抗博弈;
2、将生成器和判别器参数化为深度卷积神经网络。
2019年,研究人员提出Generative Latent Optimization(GLO),使用简单的重建损失来训练深度卷积生成器,可以合成视觉上吸引人的样本、在样本之间进行平均插值,并对噪声向量进行线性运算。
最重要的是:这些效果的实现都不需要对抗优化方案。

论文链接:https://arxiv.org/pdf/1707.05776.pdf
NeRF需要多视角数据不就是为了对抗性训练吗?
如果GLO无需对抗训练即可实现GAN,那二者结合起来,岂不就是不需要多视角的NeRF!
GLO是一种通用的方法,通过共同学习解码器神经网络和潜码表来学习重建一个数据集(如一组二维图像),该编码表也是解码器的输入。
每一个潜码都从数据集中重新创建了一个单一的元素(如图像)。由于潜伏代码的维度少于数据元素本身,网络需要对数据进行泛化,学习数据中的共同结构(如狗鼻子的一般形状)。
NeRF是一种非常善于从二维图像重建静态三维物体的技术。它用一个神经网络表示一个物体,为三维空间中的每个点输出颜色和密度。颜色和密度值是沿着射线积累的,二维图像中的每个像素都有一条射线。然后使用标准的计算机图形体积渲染将这些值结合起来,计算出最终的像素颜色。
重要的是,所有这些操作都是可微的,可以进行端到端的监督训练。通过强制要求每个渲染的像素(三维)与基准(二维)像素的颜色相匹配,神经网络可以创建一个从任何视角渲染的三维。
将NeRF与GLO结合起来,给每个物体分配一个潜码,与标准的NeRF输入相连接,使其有能力重建多个物体。
在GLO之后,研究人员在训练期间将这些潜码与网络权重共同优化以重建输入图像。
与需要同一物体的多个视图的标准NeRF不同,LOLNeRF只用一个物体的单个视图(但该类型物体的多个例子)来监督训练。
因为NeRF本身是三维的,所以模型可以从任意的视角来渲染物体。将NeRF与GLO结合起来,使其有能力从单一视图中学习跨实例的公有三维结构,同时仍然保留了重新创建数据集的特定实例的能力。
为了让NeRF正常运行,模型需要知道每张图像的确切摄像机位置,以及相对于物体的位置,但正常来说这个数据都是不可知的,除非在拍摄图像时具体测量过。
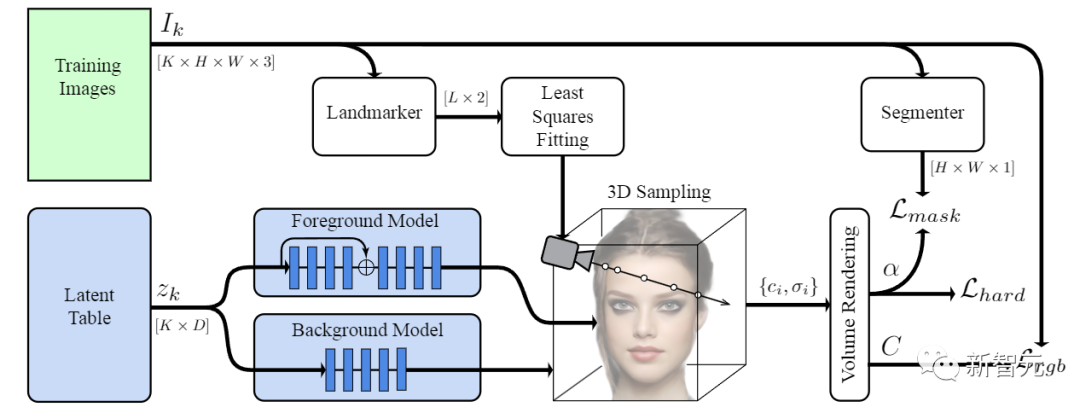
研究人员使用MediaPipe Face Mesh来从图像中提取五个landmark位置,这些二维预测的每一个点都对应于物体上的一个语义一致的点(例如,鼻尖或眼角)。
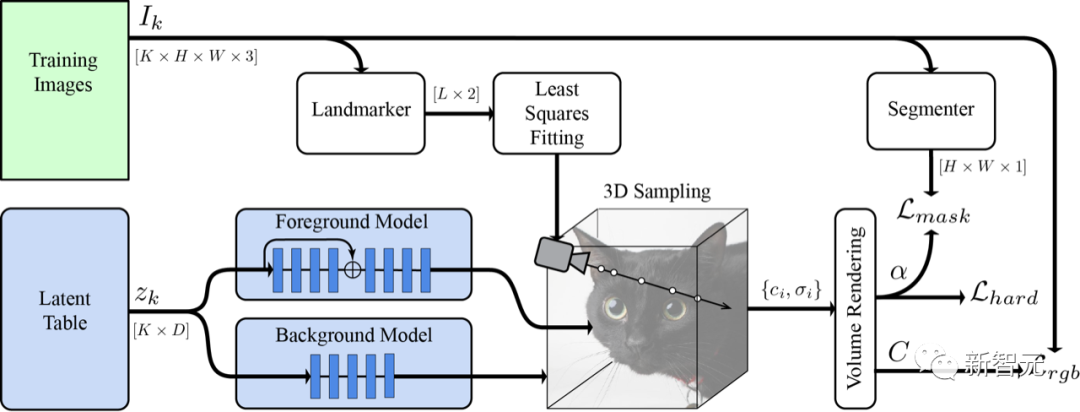
对于猫来说也是一样。
然后,我们可以为这些语义点推导出一组典型的三维位置,以及对每张图像的摄像机位置的估计,这样典型点在图像中的投影就会与二维landmark尽可能地一致。

标准的NeRF对于准确地再现图像是有效的,但在单视角情况下,往往会产生在off-axis观看时看起来很模糊的图像。
为了解决这个问题,模型中还引入了一个新的硬表面损失(hard surface loss),促使密度采用从外部到内部区域的尖锐过渡,减少模糊现象,实质上是告诉网络创建「固体」表面,而不是像云一样的半透明表面。
研究人员还通过将网络分割成独立的前景和背景网络获得了更好的结果,使用MediaPipe Selfie Segmenter的一个掩码和一个损失来监督这种分离,以促使网络specialization,可以使得前景网络只专注于感兴趣的对象,而不会被背景「分心」,从而可以提高生成质量。

在实验部分,先看一下模型在CelebA-HQ、FFHQ、AFHQ和SRN Cars数据集上训练后的可视化效果。

在量化比较部分,由于LOLNeRF是用图像重建metric来训练的,所以研究人员首先进行实验来评估训练数据集中的图像被重建的程度。
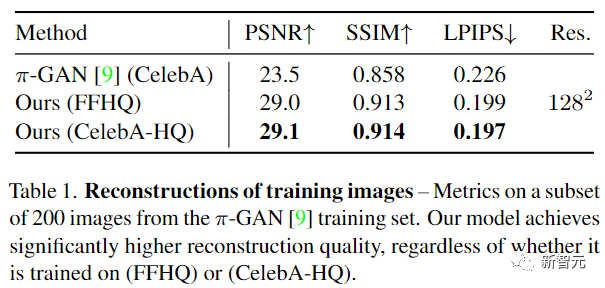
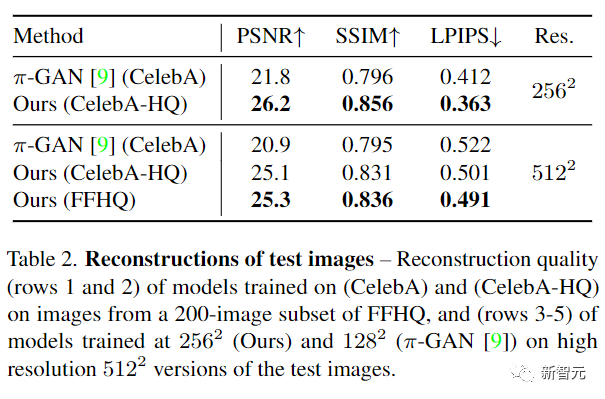
用峰值信噪比(PSNR)、结构相似度指数 峰值信噪比(PSNR)、结构相似性指数(SSIM)和学习感知图像块相似性(LPIPS)指标来比较后可以发现,LOLNeRF的指标都大幅领先。
研究人员还对图像拟合进行了一个更直接的比较,在一组训练期间未被网络看到的图像上进行测试。在从FFHQ数据集中抽取了200张图像后,使用在CelebA图像上训练的模型进行重建,在量化指标上仍然有优势。
为了评估模型学习到的三维结构的准确性,研究人员对合成的新视图(synthesized novel views)进行图像重建实验。通过对来自人类多视图行为图像(HUMBI)数据集的单帧进行图像拟合,并使用相同人物的其他ground truth视图的相机参数重建图像。
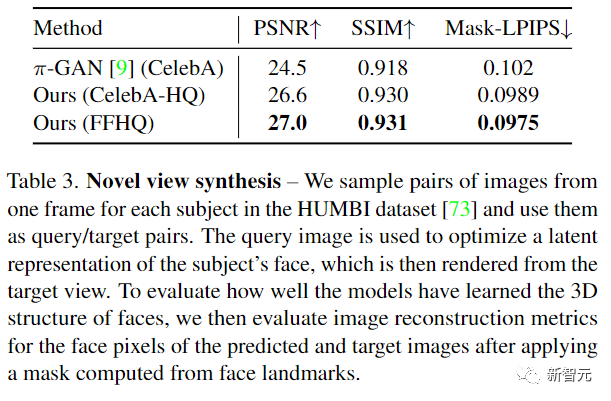
实验结果显示,对于比较模型π-GAN来说,LOLNeRF模型从新的视图中实现了明显更好的重建,也表明该方法确实比π-GAN学到了更好的三维形状空间,也就是说模型可以泛化到未见数据的形状空间,而不仅仅是从查询视图中再现查询图像。


