
AIGC是现在的热点,来自苏黎世联邦理工大学的Dario Pavllo的博士论文《结构化生成模型用于可控场景和3D内容合成》系统针对GAN/NeRF等结构化生成模型做生成进行阐述,值得关注!

Pavllo, Dario 是数据分析实验室的博士生,研究围绕深度学习和图像理解展开。在加入ETH之前,我获得了EPFL的计算机科学硕士学位,并在Menlo Park的Facebook AI Research实习,在那里我进行了计算机视觉的研究。


在这篇论文中,我们首先关注控制生成对抗网络(GANs)用于复杂场景合成的研究问题。我们发现,尽管现有的方法在一些简单的领域如面部或中心对象上展现了一定程度的控制能力,但对于由多个对象组成的复杂场景来说,它们的表现并不理想。因此,我们提出了一种弱监督方法,生成的图像由稀疏的场景布局(即草图)描述,并且可以通过文本描述或属性来细化各个对象的风格。然后,我们展示了这种范式可以有效地用于生成复杂的图像,而不会因控制而牺牲真实性。
接下来,我们解决上述的视图一致性问题。在可微渲染方面的最新进展的指引下,我们介绍了一种卷积网格生成范式,可以用GANs生成带有纹理的3D网格。这个模型可以自然地使用3D表示进行推理,因此可以用来生成计算机图形应用的3D内容。我们还展示了我们的3D生成器可以使用标准技术进行控制,这些技术也可以应用于2D GANs,并成功地将我们的模型调整到类别标签、属性和文本描述上。我们然后发现,3D内容生成的方法通常需要地面真实的姿势,限制了它们适用于这些可用的简单数据集。因此,我们提出了一种后续方法来放宽这个要求,在ImageNet的更大类别集上展示我们的方法。
最后,我们从关于神经辐射场(NeRF)的文献中汲取灵感,并将这种最近提出的表示融入到我们的3D生成建模工作中。我们展示了这些模型如何用于解决一系列下游任务,如单视图3D重建。为此,我们提出了一种桥接NeRFs和GANs的方法,从单个2D图像重建物体的3D形状、外观和姿势。我们的方法采用了一种自助GAN反演策略,其中编码器产生了解决方案的第一猜测,然后通过反演预训练的3D生成器进行优化以进行细化。
引言
近年来,由于生成模型能够快速生成新的内容——在许多情况下,这些内容与人类或自然产生的内容几乎无法区分(图1.1),所以它们得到了相当多的关注。这为广泛的应用开辟了新的途径,包括语音合成[Che+21a; Oor+16]、图像合成[Kar+20b; Ram+22; Rom+22; Sah+22]、3D对象的生成[Cha+22; Pav+20b; Poo+22]、物理系统的真实模拟[Rav+21],以及智能对话系统的创建[Bro+20; Ouy+22]。当这些模型得到足够大的数据集时,它们能够捕捉数据中存在的复杂模式,并随后用于生成类似于训练样本的新数据。最近提出的生成技术的一个主要优点是它们需要的人类注释最少,允许它们在花费很小努力的情况下,对从互联网上抓取的大量数据集进行训练[Gao+20; Sch+21]。
在生成建模领域,已经出现了各种子领域,每个子领域都专注于独特的领域,如文本、音频和视觉。在这篇论文中,我们特别关注视觉领域,这个领域近来受到了大量的研究关注,这要归功于能生成近乎真实的图像的模型。举几个例子,像StyleGAN [KLA19; Kar+20b]、Stable Diffusion [Rom+22]、DALL-E [Ram+22; Ram+21]和Imagen [Sah+22]这样的神经架构可以用来创建人和产品的真实渲染图、文章的图形和艺术内容。然而,生成模型在计算机视觉中的应用远不止于图像合成。其他例子包括图像超分辨率(从低分辨率图像创建高分辨率图像)、图像修复(修复或替换图像中缺失的部分)和风格转换。
从图像理解的角度看,生成模型是非常强大的工具,因为它们必须捕捉自然图像中出现的约束才能产生真实的结果。这些约束可能是空间的(物体的姿态和位置的连贯性)、语义的(船不在草地上航行)和风格的(自然出现的狗不能是紫色的)。然而,对于实际的内容创建应用,可能需要偏离这些约束。例如,艺术家可能想要指定他们想在图像中看到什么,物体应该在空间上位于何处,以及它们应该有什么“风格”(如颜色、纹理)。此外,对于特定的插图,他们可能想要指定在自然图像的分布中不会出现的配置(例如,宇航员骑马)。虽然最近的生成技术在合成图像的真实性方面取得了巨大的进步,但这些模型提供的结构、语义和风格控制的水平却落后了。许多提供一定程度控制的方法集中在描述中心对象的单域数据集上,而它们无法准确地建模由多个对象组成的复杂场景。
受到这些观察的启发,我们在这篇论文中首先要解决的研究问题是,我们如何使生成模型更具可控性,特别是对复杂场景的控制。文献中找到的一种可行的折中方案是将模型条件化为一个语义分割图 [Iso+17; Par+19b; Wan+18],但遗憾的是,这种方法在操作或从头开始创建时并不实用,并且也没有提供风格控制的接口。显然,弱条件化(如通过标签或单个文本提示描述图像)与丰富的条件化(如完全的分割图)之间存在一种权衡,弱条件化使任务对人类来说更容易,但对机器来说更困难——可能导致场景不连贯或结果不理想,而丰富的条件化则限制了输出并有助于学习任务,但对想要生成或操作图像的用户来说需要禁止性的努力。这篇论文的一个主要目标是探索通过结构化表示(如描述场景中物体位置的文本描述和草图)对这些生成模型进行条件化(即控制)的方法,并设计一个既保留高生成质量又保持适当控制水平的可行框架(第2章)。这些模型取得的鼓舞人心的结果引导我们提出了另一个研究问题:除了真实性和可控性之外,还有什么其他重要的方面使生成模型有用?虽然上述技术在生成静态内容方面表现出色,但一些应用如动画、电子游戏和广告需要更具结构化的表示。例如,在计算机图形学中,人们通常希望处理同一对象的多个视图,同时保持其在不同视图中的身份,也就是说,强制将姿势和外观解耦。这个问题可以通过设计能够原生地合成3D表示的生成模型在根本上解决。
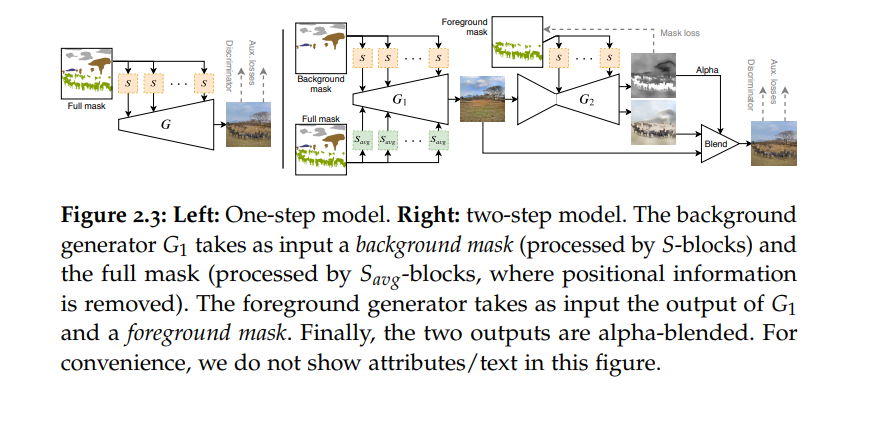
我们将这篇论文的第二部分献给这个主题,并提出一种使用2D数据集监督来生成纹理3D网格的方法(第3章,第4章)。我们展示了,就像在2D案例中一样,这些模型可以成功地通过生成对抗网络(GANs)进行训练,并可以通过文本提示或其他在2D GAN文献中常用的条件化技术进行控制。
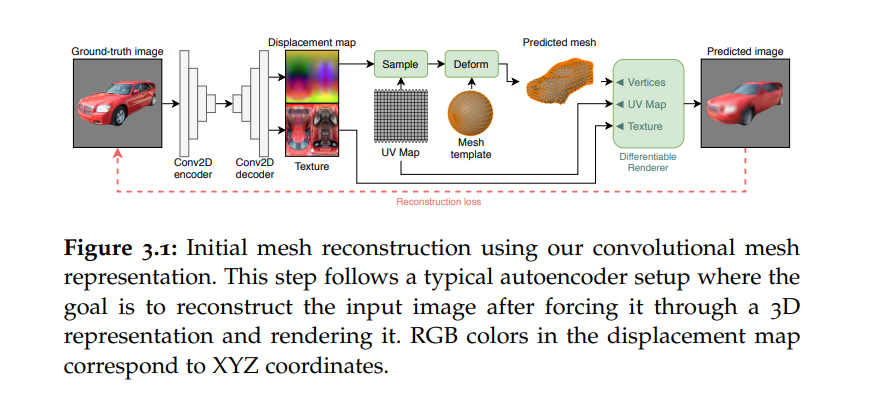
最后,我们从最近关于基于神经辐射场(NeRF)的最新表示的文献中得到启发,并展示了3D生成器如何在3D计算机视觉的额外下游任务中发挥作用,如单视图3D重建(第5章)。





