
作者: 沈碧寒 今天介绍中国科学院上海营养与健康所李虹团队在Briefings in Bioinformatics上发表的一篇论文,该文对深度学习药敏预测算法进行了综合评测。文章系统地评估了深度学习方法在预测癌细胞系和患者药物反应方面的性能,为用户根据自身需求和数据特点选择恰当的预测模型提供指导,同时为构建新的计算模型指引方向。

背景
癌症个体化治疗的关键是根据肿瘤的分子特征选择合适的治疗方法。由于临床药物基因组学数据集难于获取,研究人员往往用临床前模型特别是肿瘤细胞系代替肿瘤患者进行给药实验。目前常见的高通量药物基因组数据库包括CCLE、GDSC和CTRP,研究人员基于此开发了多种药敏预测算法。深度学习因为其灵活性,拟合能力,而被越来越多的应用于药敏预测领域。文章首先将几种代表性的药敏预测深度学习算法用于癌症细胞系数据构建模型,然后系统地比较了这些算法在总体和单药水平的性能排序结果,最后评估其预测癌症患者用药效果时的迁移性能。
模型介绍
根据建模时对数据集的划分方式,可将药敏预测框架分为两类:单药模型(SDL)和多药模型(MDL),如图1所示。
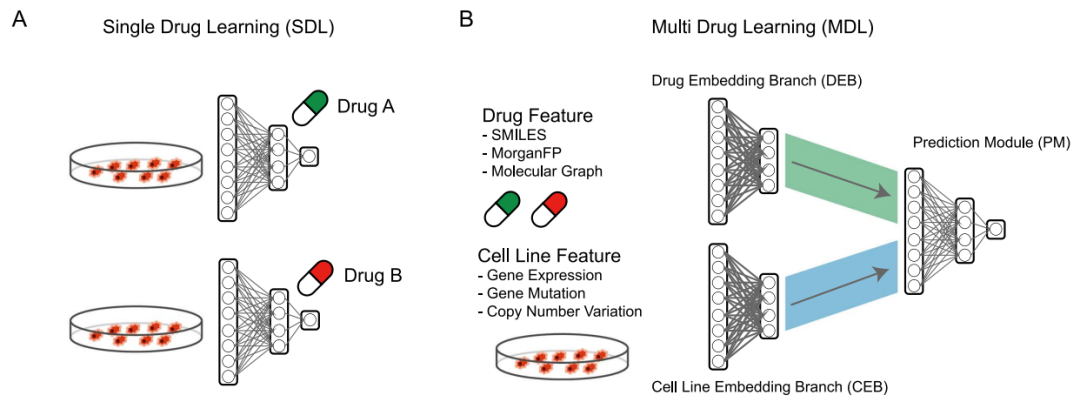
图1. 药敏预测模型典型框架
SDL框架分别为每个药物建立一个模型,深度学习方法,例如DNN、AE、VAE,可以更好地捕获细胞系与药物反应之间的非线性关系。
MDL框架可以同时处理细胞系和药物的信息,达到整合不同药物筛药实验结果,扩充数据量的目的。MDL模型一般由三部分构成:细胞系嵌入分支(CEB)、药物嵌入分支(DEB)和预测模块(PM)。对于CEB而言,常使用的方法有DNN、AE以及CNN,另外有研究人员尝试使用VNN和GNN将先验生物学知识引入到模型当中。而用于DEB的方法,往往是由药物特征的表现形式决定的:分子指纹和描述符一般用DNN、CNN处理,SMILES式使用CNN,分子结构图则使用GNN。PM需要利用CEB和DEB的互补性对信息进行整合,常见的方式是后整合。
文中选择了具有代表性的深度学习药敏预测方法,包括3种SDL方法和3种MDL方法,其简要介绍如表1所示。
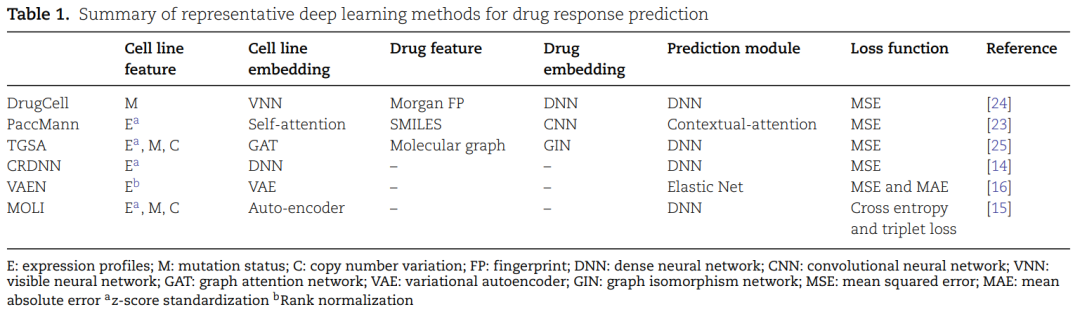
表1. 药敏预测代表性方法简介
结果
总体预测性能 评估在GDSC数据集上进行,其包括966个细胞系的转录组和基因组数据以及282个药物在这些细胞系上的药物响应值(IC50值)。通过交叉验证获得每一折作为测试集时的预测结果,然后计算在两类共九个指标上的评价结果。RMSE家族:RMSE,L_RMSE,R_RMSE,LR_RMSE,值越小表示预测越准确;相关性家族:PCC,SCC,NDCG,PC/NWPC,ROC_AUC,值越高表示预测越准确。
在所有药物上的总体评价结果如图2所示。DrugCell,TGSA,CRDNN,VAEN在各个指标上都获得了不错的表现。相比于SDL模型,MDL因为在不同药物间共享参数,运算时间更少。
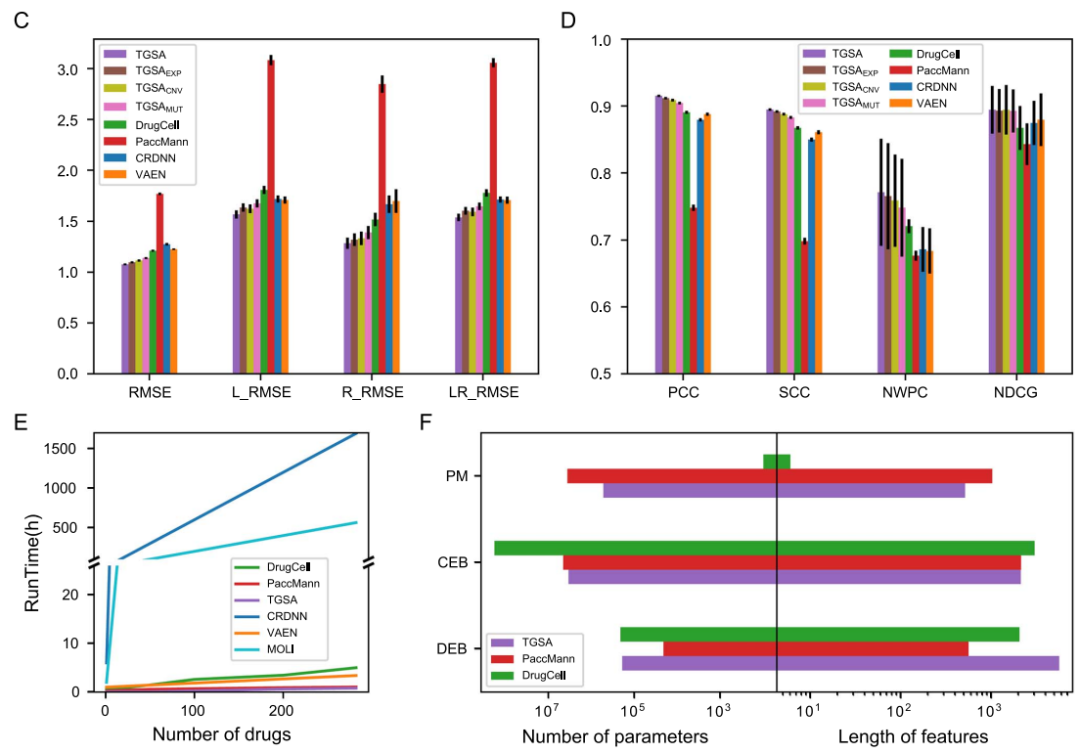
图2. 基于细胞系数据评估各种算法在所有药物上的总体结果
细胞系和药物的相对重要性 药物响应值IC50是由细胞系和药物共同决定,各种药物IC50分布的差异要显著大于细胞系IC50分布的差异(图3A)。根据方差分解结果,细胞系仅能解释IC50方差的5.9%,药物则解释了73.6%(图3B)。消融实验的结果也显示,DEB对模型预测准确性贡献更大(图3C-G)。
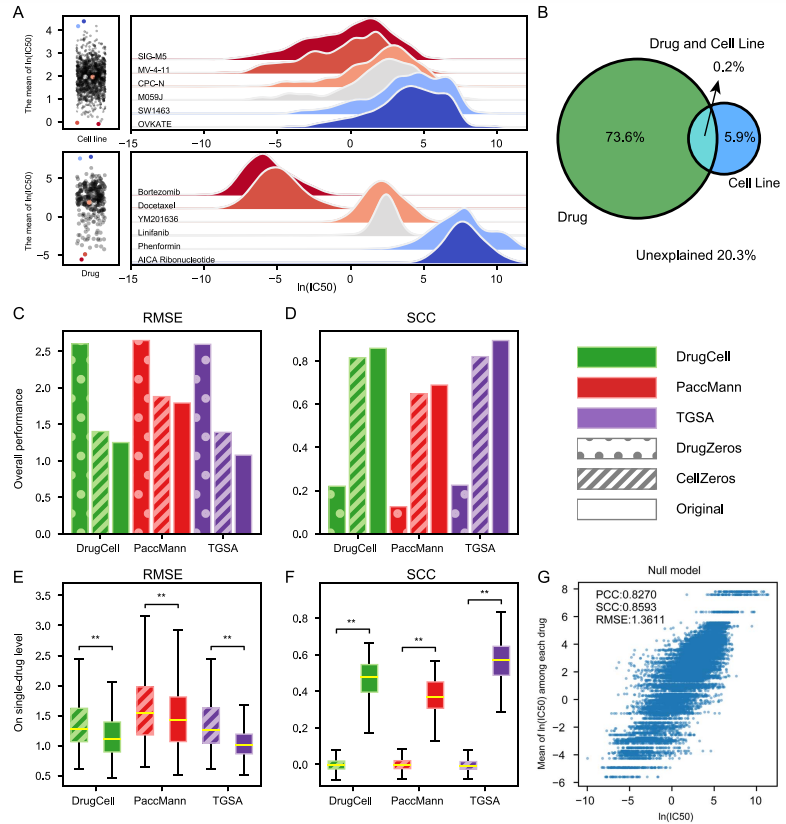
图3. 细胞系特征和药物特征对药物响应值的相对重要性
单个药物水平预测性能评估 进一步地,文章评估了以上算法预测每个药物的准确性。如图4所示,DrugCell、TGSA、CRDNN、VAEN依旧表现良好。最优模型TGSA在单个药物水平的RMSE范围为0.5~2.66,SCC范围为0.18~0.83。
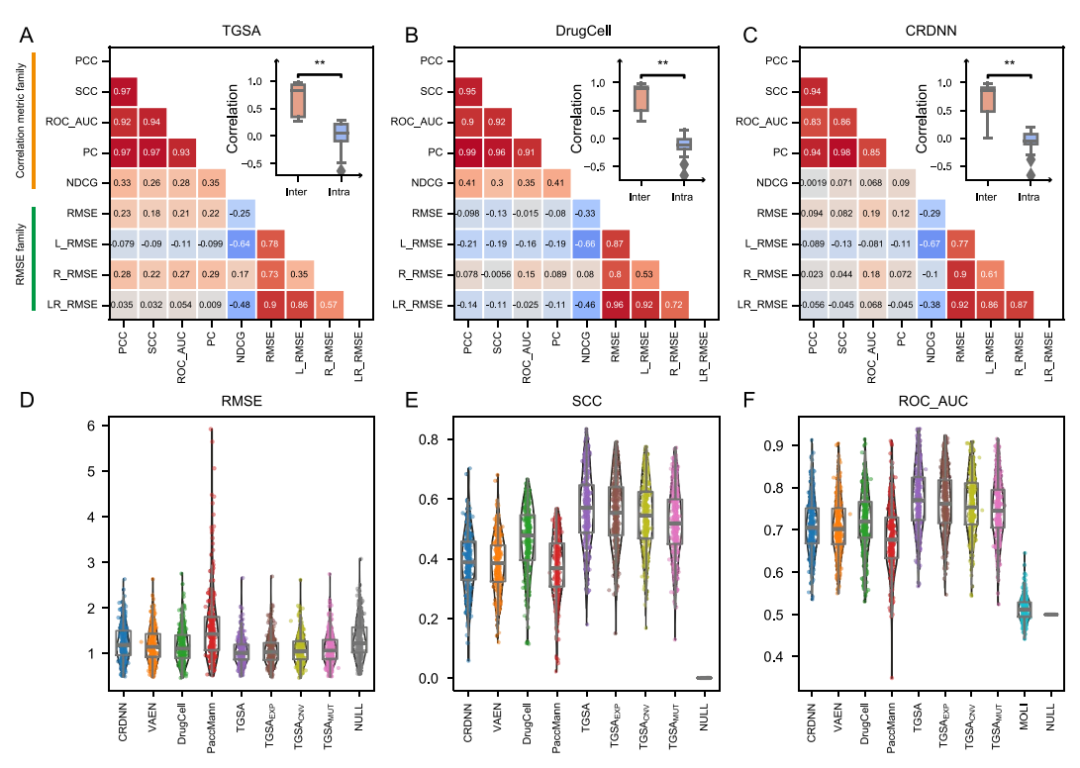
图4. 基于细胞系数据评估各种算法对每个药物的预测能力
药物的可预测性 不同药物的可预测性存在差异,于是作者根据单个药物水平的预测值和真实IC50的秩相关系数(SCC)对药物进行聚类,得到一组各种算法都能预测正确的药物(P)和各种算法预测准确率都低的一组药物(U)。通过比较这两组药物的统计学指标,作者发现如果该药物的IC50分布方差大、双峰分布趋势明显、和所有药物整体分布的一致性强,那么它的IC50值将更容易被正确预测。另外,药物靶向通路的富集分析显示,药物作用机制也是影响药敏预测的因素之一(图5)。
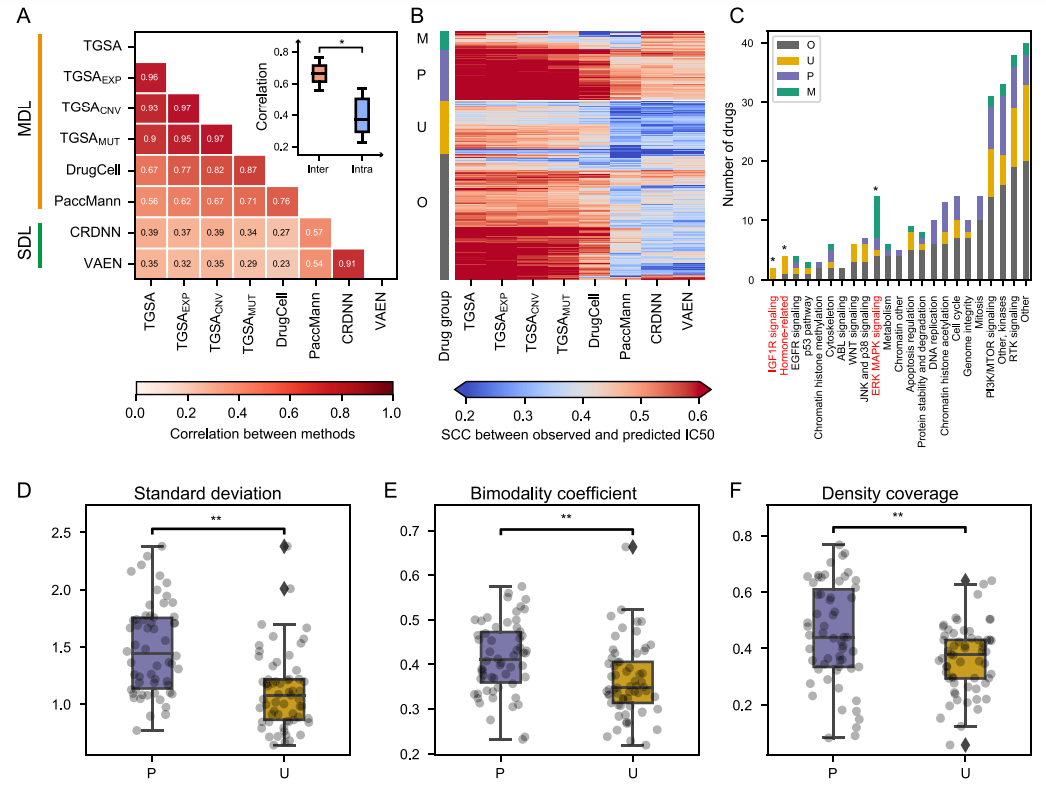
图5. 药物可预测性及其影响因素
患者数据上的可迁移性 为了研究基于细胞系数据建立的药敏预测模型能否适用于肿瘤患者,作者将以上模型用于TCGA中有药效评价的患者。由于细胞系和患者的差异,各种模型迁移到患者时,准确性都有一定程度的下降(图6A-B)。但是CRDNN和TGSA仍然可以在部分药物上对有效和无效患者进行区分。作者也讨论了整合多种类型癌症数据构建的泛癌模型和针对某种类型癌症建立的特异性模型之间的差异,对于有些药物而言(例如Temozolomide),单种癌症上建模的性能要优于泛癌(图6D)。
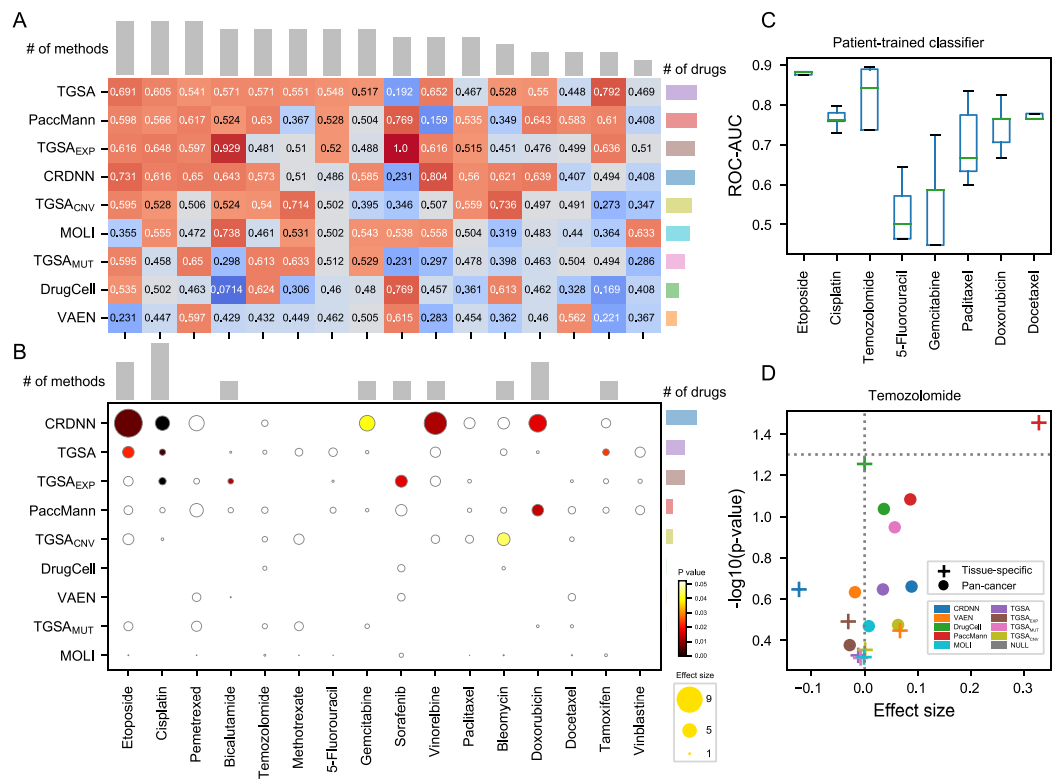
图6. 患者数据评价结果
总结与展望
综合以上评测结果,各种癌症药敏预测算法在计算效率、准确性和迁移能力方面的表现如表2所示,用户可根据自身需求和数据特点选择恰当的预测算法。

表2. 综合评测结果
最后作者也总结了现有癌症药敏预测算法的瓶颈及对未来发展方向的思考:
药物响应值在不同药物之间的方差更大,PM需要平衡来自CEB和DEB的信息强度,才能捕捉细胞系间的细微差异。 多模态数据整合中的中间整合方式有希望解决这一问题。 1. DrugCell和TGSA都采用了图嵌入的方式表征细胞系,并取得了优越的性能。 两个方法中所用的图的拓扑结构是固定的,如果采用结构变化的图来表征细胞系,可能进一步提高模型准确率。 1. 在患者数据上的泛化性能有很大的提升空间,迁移学习技术可能会提供更好的解决方案。 1. 单细胞测序技术使探索细胞亚群的药物响应成为可能。 在未来,可能会在新的计算框架(例如多实例学习)下利用单细胞测序数据进行药物反应预测。
参考资料 Shen, B.#, Feng, F.#, Li, K., Lin, P., Ma, L., & Li, H.* (2022). A systematic assessment of deep learning methods for drug response prediction: from in vitro to clinical applications. Briefings in bioinformatics. https://doi.org/10.1093/bib/bbac605

