

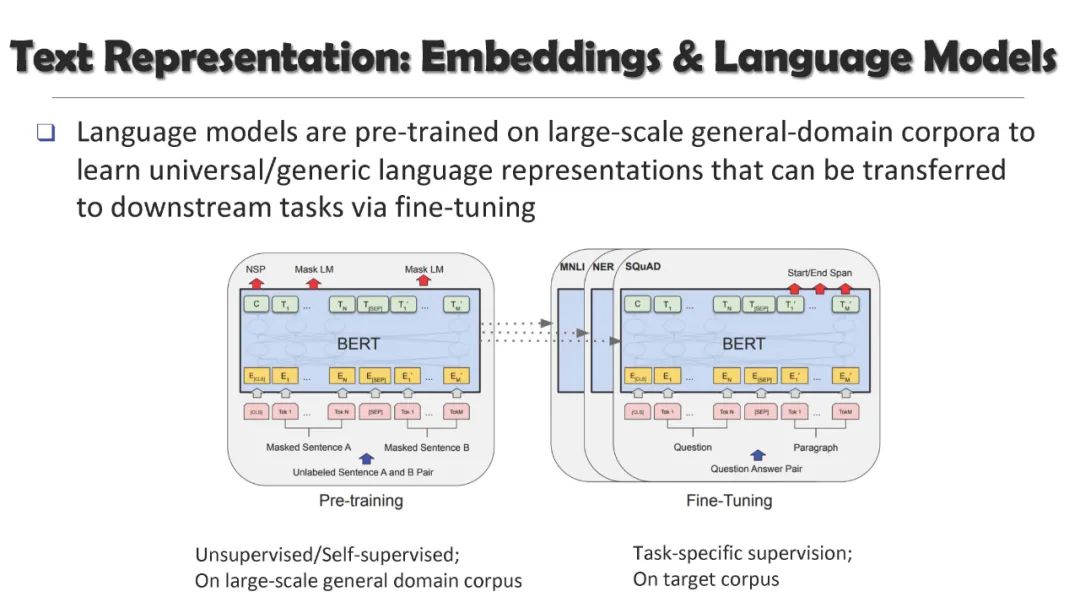
从与上下文无关的词嵌入到与上下文相关的语言模型,预训练的文本表示将文本挖掘带入了一个新的时代: 通过在大规模文本语料库上对神经模型进行预处理,然后将其适应于特定任务的数据,可以有效地将通用语言特征和知识转移到目标应用中,并在许多文本挖掘任务中取得了显著的性能。不幸的是,在这种突出的预训练微调范式中存在着一个巨大的挑战:大型的预训练语言模型(PLM)通常需要大量的训练数据来对下游任务进行稳定的微调,而大量的人工注释的获取成本很高。
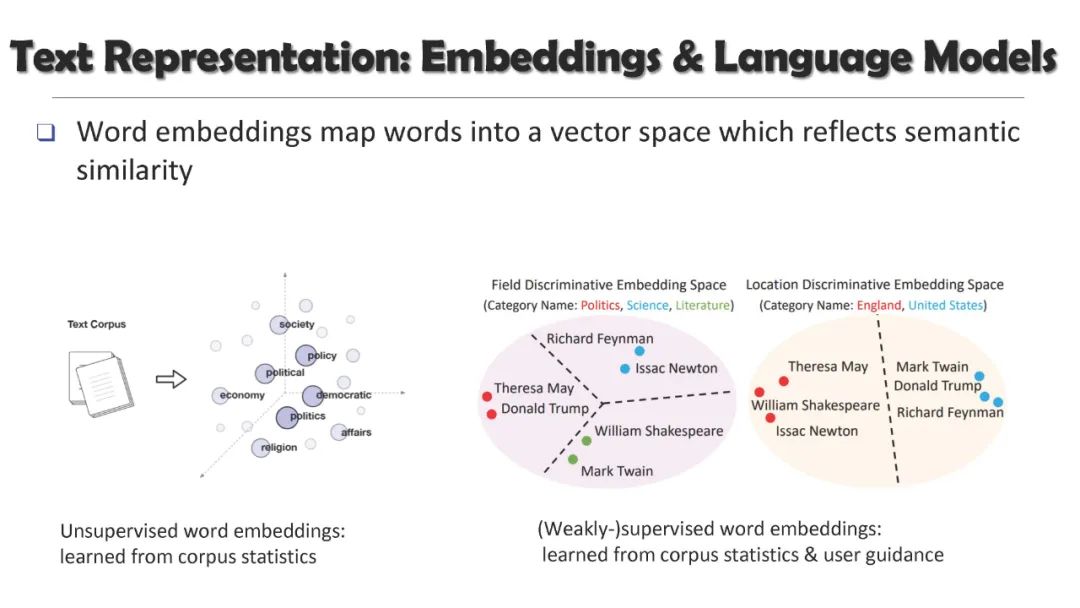
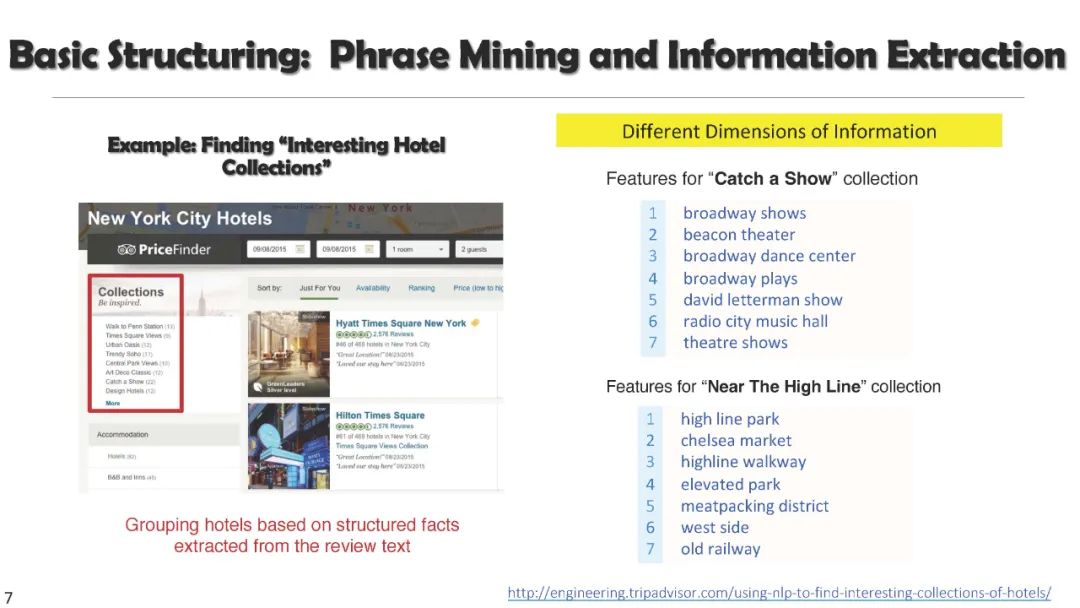
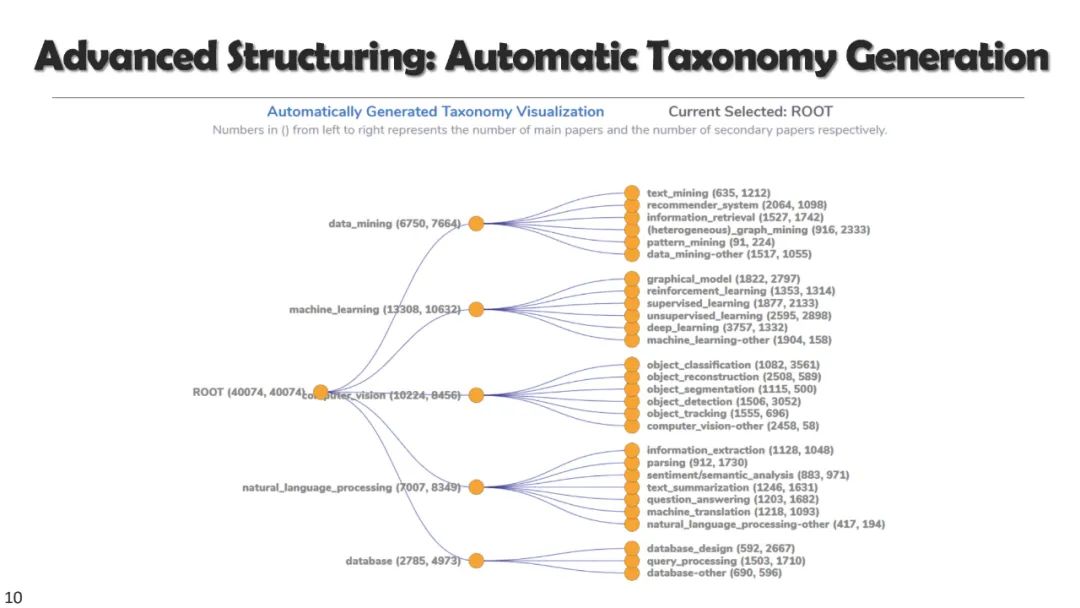
在本教程中,我们将介绍预训练文本表示的最新进展,以及它们在广泛的文本挖掘任务中的应用。我们专注于不需要大量人工标注的最小监督方法,包括**(1)作为下游任务基础的自监督文本嵌入和预训练语言模型,(2)用于基本文本挖掘应用的无监督和远程监督方法,(3)用于从大量文本语料库中发现主题的无监督和种子引导方法,以及(4)用于文本分类和高级文本挖掘任务的弱监督方法**。
介绍 第一部分: 科学信息提取与分析 第二部分: 科学信息搜索和证据挖掘 第三部分: 主题发现、文本分类和多维文本分析 摘要及未来方向





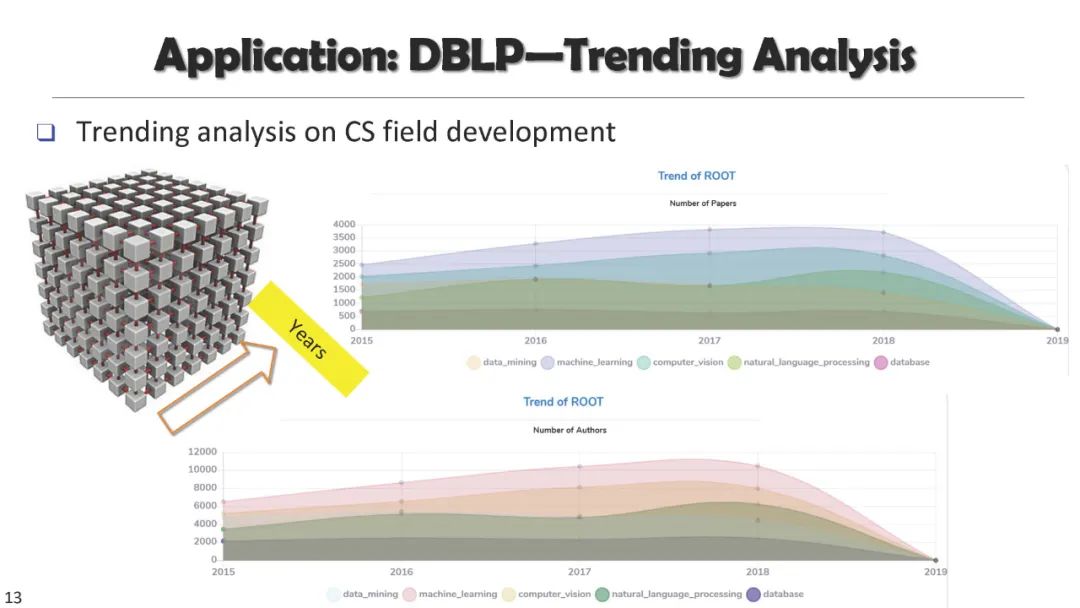
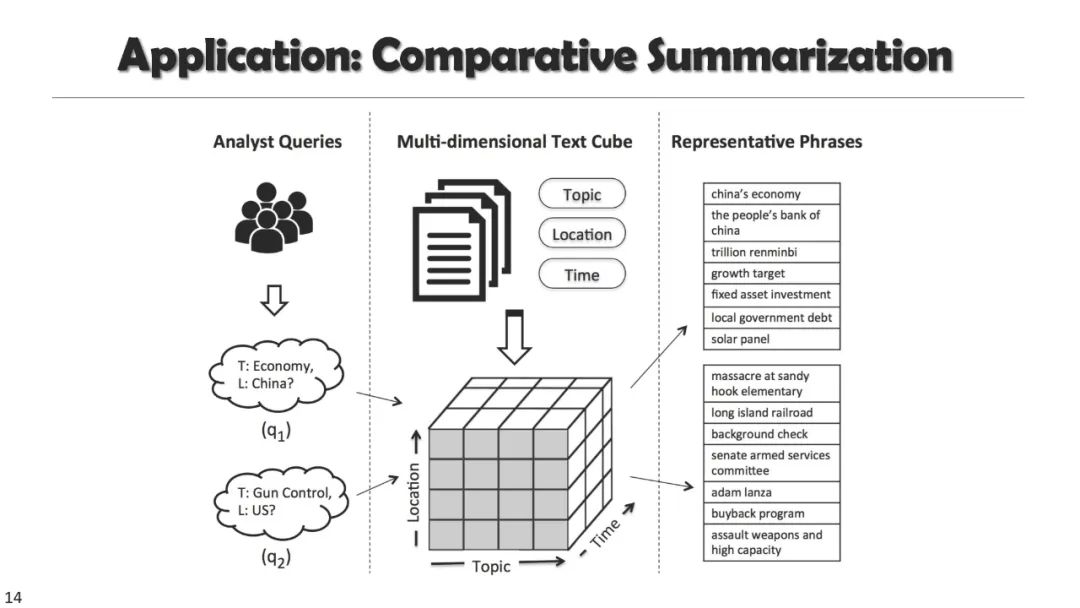

成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年10月3日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年10月3日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日