【KDD2019知识图谱教程】从海量文本中挖掘和构建异构信息网络,UIUC232页ppt
第25届ACM SIGKDD知识发现与数据挖掘大会于 2019 年 8 月 4 日- 8 日在美国阿拉斯加州安克雷奇市举行。一年一度的KDD大会是最重要的跨学科会议,汇聚了数据科学、数据挖掘、知识发现、大规模数据分析和大数据等领域的研究人员和实践者。今天小编整理了关于数据挖掘方面的内容---从文本中构建和挖掘异构信息网络,本文提供了一个全面的综述,总结了在这个方向最近的研究和发展。

T17: Constructing and Mining Heterogeneous Information Networks from Massive Text
Jingbo Shang, Jiaming Shen, Liyuan Liu, Jiawei Han
Computer Science Department, University of Illinois at Urbana-Champaign
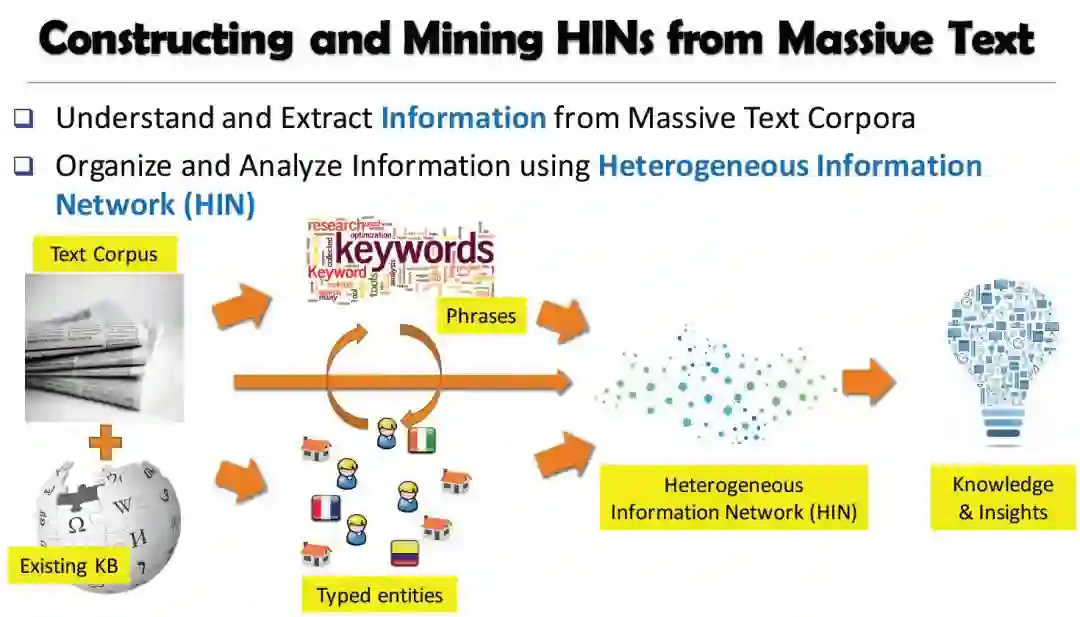
现实世界中的数据主要以非结构化文本的形式存在。数据挖掘研究的一个重大挑战是开发有效的、可伸缩的方法,将非结构化文本转换为结构化知识。基于我们的愿景,将这些文本转换为结构化的异构信息网络是非常有益的,可以根据用户的需求生成可操作的知识。
在本教程中,我们将全面概述这方面的最新研究和发展。首先,我们介绍了一系列从大规模、领域特定的文本语料库构建异构信息网络的有效方法。然后,我们讨论了基于用户需求挖掘这种文本丰富网络的方法。具体来说,我们关注的是可伸缩的、有效的、弱监督的、与语言无关的方法,这些方法可以处理各种文本。我们还将在实际数据集(包括新闻文章、科学出版物和产品评论)上进一步演示如何构建信息网络,以及如何帮助进一步的探索性分析。
1. 动机:为什么要从大量文本中构建和挖掘异构信息网络?
2. 大量文本网络构建的综述
3. 关于构建网络应用探索的综述
1. 为什么短语挖掘以及如何定义高质量的短语?
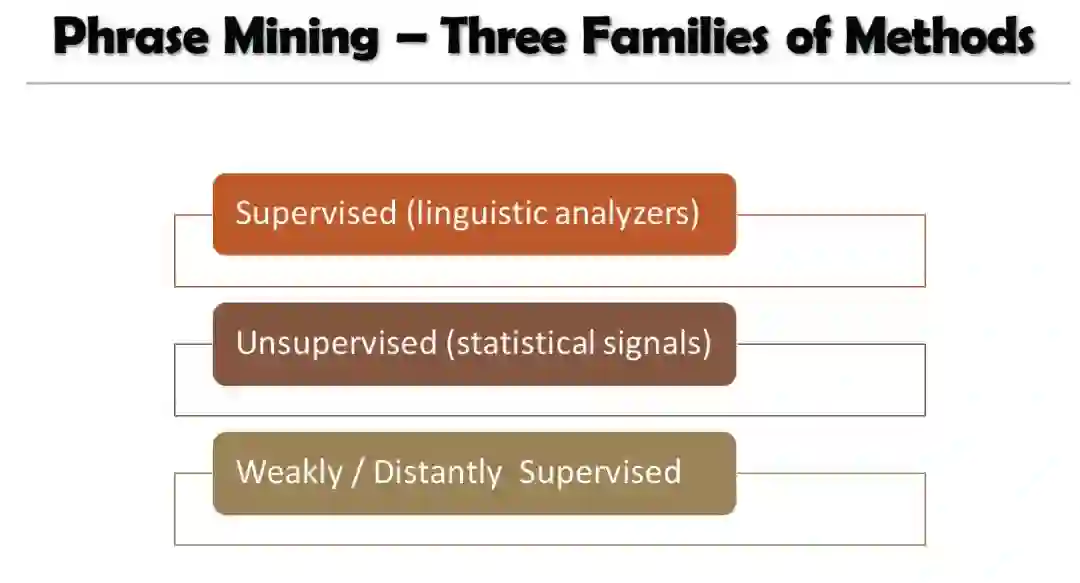
2. 监督方法
2.1. 名词短语分块方法
2.2. 基于解析的方法
2.3. 如何在语料库级别对实体进行排序?
3. 无监督方法
3.1. 基于原始频率的方法
3.2. 基于协调的方法
3.3. 基于主题模型的方法
3.4. 对比方法
4. 弱/远程监督方法
4.1. 短语分词及其变体
4.2. 如何利用远程监督?
5. 系统演示和软件介绍
5.1. 一种多语言短语挖掘系统,它将AutoPhrase,SegPhrase和TopMine集成在一起,支持多种语言的短语挖掘(例如,英语,西班牙语,中文,阿拉伯语和日语)。
1. 什么是命名实体识别(NER)?
2. 传统的监督方法
2.1. CorNLL03共享任务
2.2. 序列标注框架
2.3. 条件随机场
2.4 手工制作的特征
3. 现代端到端神经模型
3.1. 双向LSTM模型
3.2. 语言模型和语境化表示
3.3. Raw-to-end模型
4. 远程监督的模型
4.1. 实体输入的数据编程
4.2. 学习特定领域的词典
5. 基于元模式的信息提取
5.1. 元模式挖掘
5.2. 元模式增强的NER
6. 系统演示和软件
6.1 命名实体识别推理Python包:LightNER。该模块可帮助用户以高效便捷的方式轻松地将预训练的NER模型应用于他们自己的语料库。
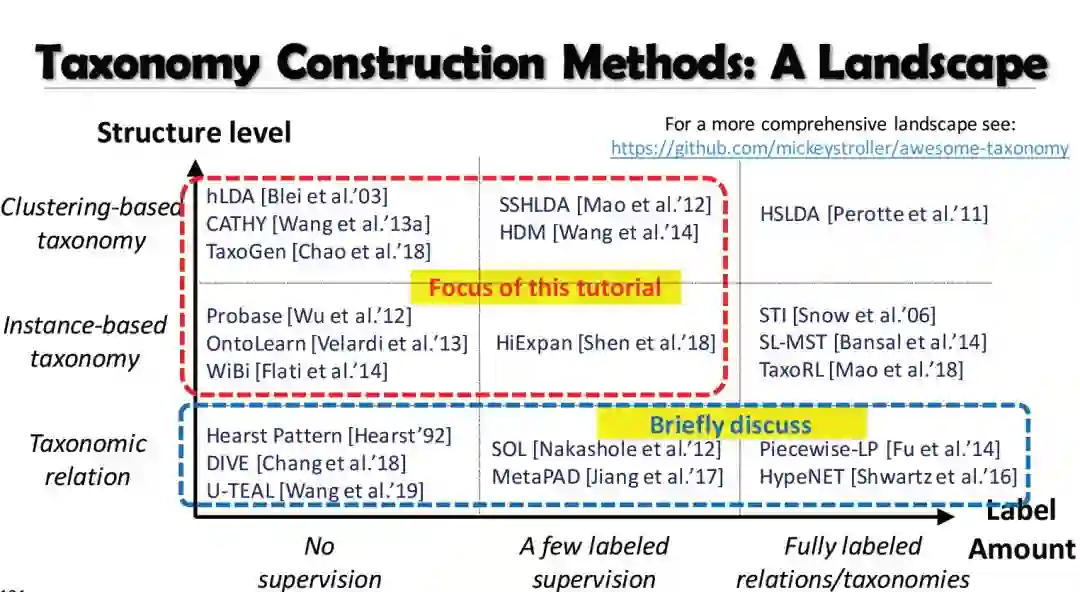
1. 分类学基础
1.1. 分类法定义
1.2. 分类应用
1.3. 分类构建方法
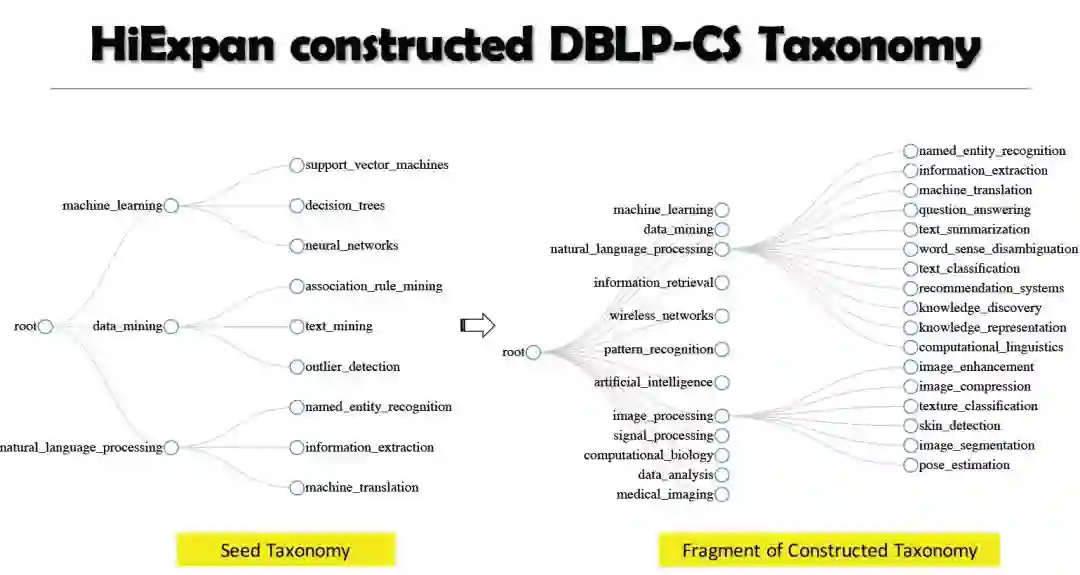
2. 基于实例的分类构建
2.1. 使用的方法综述
2.2. 基于模式的方法
2.3. 监督方法
2.4. 弱监督方法
3. 基于聚类的分类构建
3.1. 分层主题建模
3.2. 一般图模型方法
3.3. 分层聚类
1. 基本分析系统演示
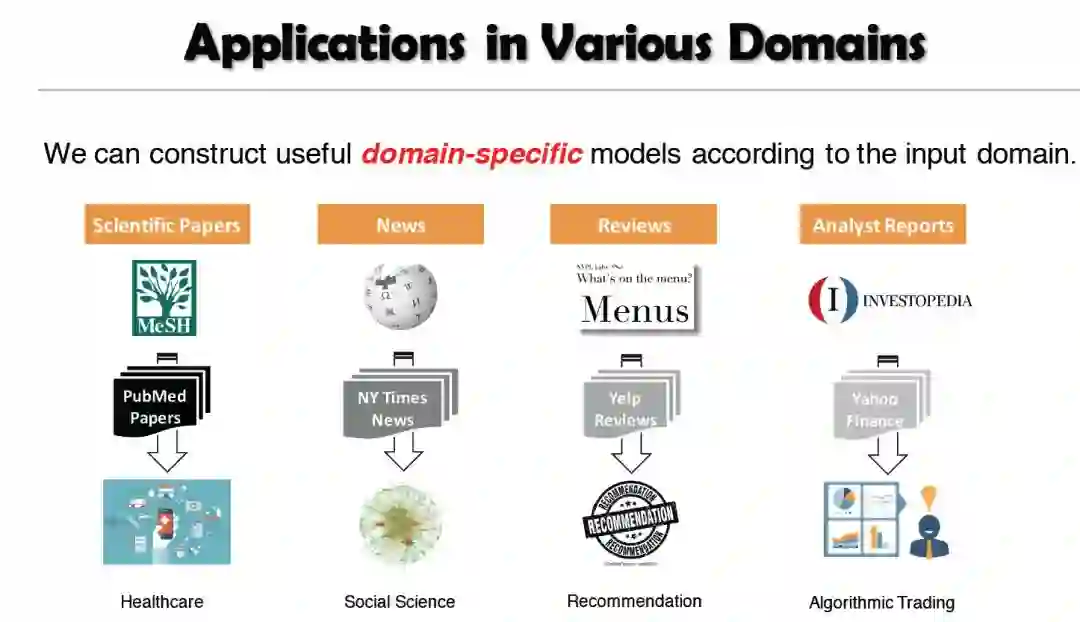
1.1. AutoNet系统:它从PubMed论文(标题和摘要)构建了一个巨大的结构化网络,并支持在线构建(新文档)和智能探索(搜索)。
2. 概要
2.1. 基于图的总结
2.2. 聚类和排序的总结
3. 元路径引导探索
3.1. 基于元路径的相似性
3.2. 元路径引导节点嵌入
4. 链接预测
4.1. 任务引导节点嵌入
4.2. 构建网络中的链接增强
1. 摘要
1.1. 原理与技术
1.2. 优势和局限
2. 挑战和未来的研究方向
3. 与观众的互动
3.1 如何根据您的文本数据和应用需求构建和挖掘异构信息网络?
报告人简介

Jingbo Shang,伊利诺伊州厄巴纳 - 香槟分校大学计算机科学系在读博士。他的研究重点是从大量的文本语料库中挖掘和构建结构化知识,同时尽量减少人力。他的研究得到了多个著名奖项的认可,包括Yelp数据集挑战大奖(2015年),结构化数据和数据库管理Google博士奖学金(2017-2019)。尚先生在重大会议上(SIGMOD'17,WWW'17,SIGKDD'17和SIGKDD'18)提供教程方面拥有丰富的经验。

Jiaming Shen ,伊利诺伊州厄巴纳 - 香槟分校大学计算机科学系在读博士。他的研究重点是将大量非结构化文本库转换为结构化知识,以便更好地检索,探索和分析特定领域的语料库。他是2016年Brian Totty研究生奖学金的获得者。

Liyuan Liu,伊利诺伊州厄巴纳 - 香槟分校大学计算机科学系在读博士。他的研究兴趣主要在于数据驱动的文本挖掘,包括语言建模的语境化表示,弱监督和异构监督。

Jiawei Han是伊利诺伊大学计算机科学系的教授。他一直在研究数据挖掘,信息网络分析和数据库系统,有600多种出版物。他创办了ACM TKDD学报并任主编。他已获得ACM SIGKDD创新奖(2004年),IEEE计算机学会技术成就奖(2005年),IEEE计算机学会W. Wallace McDowell奖(2009年),以及UIUC的Daniel C. Drucker杰出教师奖(2011年)。他是ACM的研究员和IEEE的研究员。他目前是美国陆军研究实验室网络科学 - 协作技术联盟(NS-CTA)计划支持的信息网络学术研究中心(INARC)主任。他的合著教科书“数据挖掘:概念与技术”(Morgan Kaufmann)已在全球范围内采用。
原文链接:
https://shangjingbo1226.github.io/2019-04-22-kdd-tutorial/
请关注专知公众号(点击上方蓝色专知关注)
后台回复“HIN” 就可以获取教程下载链接~






-END-
专 · 知
专知,专业可信的人工智能知识分发!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程