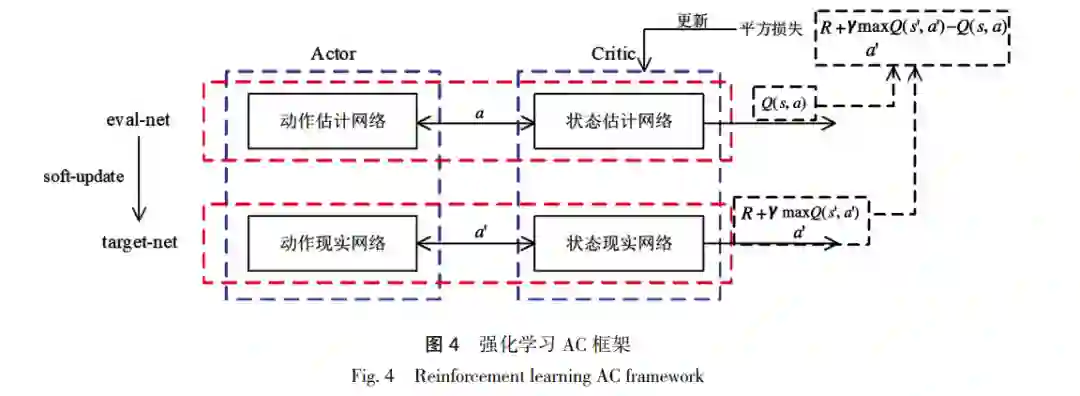
智能博弈对抗领域已成为当前研究的热门领域之一。侧重在兵棋推演系统的体系构建和模块设计,分 析了兵棋推演系统的建模要素,包括兵棋要素、兵棋规则及智能接口设计,构建了智能兵棋推演系统的整体架构。通 过 A3C 强化学习智能算法对系统设计进行可行性验证。其中,改进了强化学习训练过程的奖励设置,明确智能兵棋 环境的状态输入、算法驱动过程及动作输出过程,通过自主实现的智能兵棋推演系统,验证了所提的系统理论与工 作。该工作为基于强化学习的智能博弈系统的设计与实现提供了可行路径,并为以后基于强化学习的智能博弈对抗 研究提供了基础平台。
近年来人工智能技术突飞猛进,尤其在智能 博弈对抗领域取得了一系列的关键进展。2016 年,AlphaGo 与李胜石进行了一场万众瞩目的围棋 大战,最终人工智能 AlphaGo 以 4∶1 的结果完胜人类,一时间掀起了社会上的广泛热议,推动了人 工智能技术的又一次发展浪潮[ 1-2]。随后,AlphaGo 的研制团队 DeepMind 趁热打铁,在《星际争霸》游 戏上进一步取得明显突破,研制成功 AlphaStar[3]。 中国腾讯 AI Lab 利用深度强化学习技术,在《王 者荣耀》游戏虚拟环境中构建“觉悟 AI”,开发高 扩展、低耦合的强化训练系统,使得“觉悟 AI”能 够具有进攻、诱导、防御、欺骗和技能连续释放的 能力[ 4]。 智能博弈系统虽然取得了显著成就,但是依然 有很多问题亟待进一步研究。虽然人工智能的概念 早在 1956 年就被提出,但是由于计算机性能的不 足以及理论基础的缺失,人工智能还远远没有达到 可以挑战人类思维的地步[5]。随着对于智能化研究 的逐渐深入,各种算法的实现以及在围棋上 AlphaGo 的出现[6-7],对智能博弈系统进行智能化研究已 经是一种趋势。智能辅助决策是制约智能博弈系统 升级换代的瓶颈问题,是一个不容忽视甚至是需要 争分夺秒去解决的问题。由于智能博弈系统特点, 深度学习和强化学习的算法效果依然有很大的提 升空间。这里以最经典的博弈系统“兵棋推演”为 例,简述基于强化学习的智能博弈系统的构建思路 及仿真验证。 本研究设计的算法模型为设计适用于复杂环 境的智能兵棋系统提供了思路:建立智能兵棋系统 通用的体系架构,并针对每个模块进行功能解释。 针对智能兵棋系统的核心模块,建立智能决策算法 模型,通过典型实验环境来验证建模思路。其中,智 能决策模型以 A3C 算法为代表的强化学习驱动,进 而从原理和实践上,验证了智能决策算法模型在智 能兵棋推演系统的可行性。