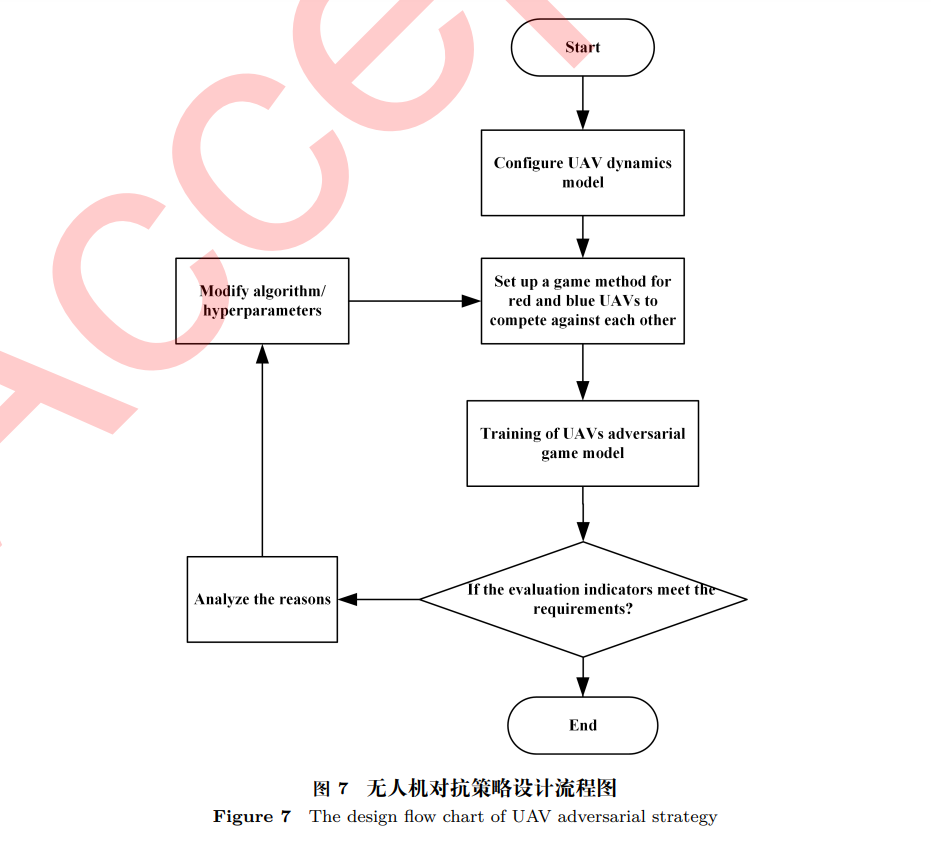
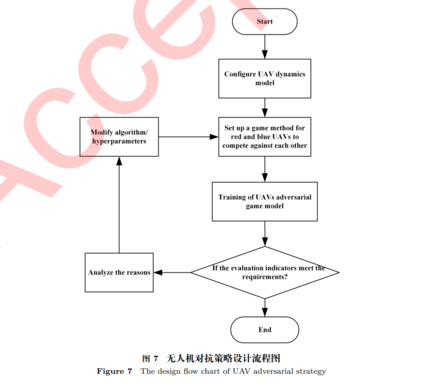
无人机在军事上的应用越来越广泛和深入,尤其是无人机集群在协同探测、全域打击、战术骗扰等作战任务中,发挥着越来越重要作用,可靠高效的无人机集群博弈方法是当前的研究热点。本文将反事实基线思想引入到无人机集群对抗博弈环境,提出面向多无人机场景的反事实多智能体策略梯度(Counterfactual multi-agent policy gradients, COMA)博弈方法;在具有连续无限状态、动作的无人机作战环境中,构建基于多智能体深度强化学习的无人机集群对抗博弈模型。利用多智能体粒子群环境(Multi-agent particle environment, MPE)对红蓝双方无人机集群进行非对称性对抗实验,实验结果表明COMA方法在平均累积奖励、平均命中率和平均胜率方面均优于目前流行的深度强化学习方法。最后,通过对COMA方法的收敛性和稳定性的深入分析,保证了COMA方法在无人机集群对抗博弈任务上的实用性和鲁棒性。
无人机 (Unmanned aerial vehicle, UAV) 集群是由若干配备多种任务载荷的低成本小型无人机 组成的无人化作战系统,通过自主学习共同完成特定复杂作战任务. 作为典型的多智能体系统,无 人机集群以难防御、强进攻、低成本、自主学习,使用灵活等优势深刻改变着现代战争模式 [1∼4].随着无人机智能化水平的提高和集群控制技术的飞速发展,无人机集群对抗自主决策方法将成为未 来无人机作战的关键技术. 解决无人机集群对抗自主决策问题的一种思路是利用进化方法,进化方法是一类受生物进化理 论启发而形成的计算方法,常用于解决优化、搜索和对抗等问题,其核心思想是通过模拟生物进化 的过程,找到问题的最优或次优解. John Kaneshige 等 [5] 使用人工免疫机制解决空战机动选择问 题,将敌机视为抗原,通过相对位置速度表征,将机动动作视为抗体,利用遗传算法和进化算法模 仿免疫系统对应抗原的自适应能力,这种机制使得智能体具有较强的记忆能力,能记录过往成功的 经验以在相似场景下快速响应. Duan 等 [6] 提出了一种基于捕食者-猎物粒子群优化 (Predator-prey particle swarm optimization,PP-PSO) 的博弈方法,将多无人机作战任务建模为双人博弈,并通过 PP-PSO 方法来解决. 周文卿等 [7] 针对多无人机协同飞抵作战空域完成作战任务的问题进行了建 模,利用蚁群算法和所提的多无人机控制算法进行仿真实验,实验表明该算法能有效提升无人机集 群空战获胜率. Isler 等 [8] 将随机策略与狮子追捕策略结合,研究了两个追踪者对一个高速运动逃 跑者的协同追捕算法,在简单连通多边形环境中验证了所提算法的有效性. Chen 等 [9] 利用模糊规 则对多无人机空战问题进行离散化,并采用粒子群优化方法求解纳什均衡,该方法解决了协同博弈 问题,模拟结果呈现了该方法的可行性和有效性. 然而,用进化方法解决博弈问题需要固定一个策 略并且和对手博弈多次,或者与对手的仿真模型进行大量模拟博弈. 尽管获胜频率作为该策略获胜 概率的无偏估计,可用于指导下一轮策略选择,然而每一次策略的调整都源于多次博弈. 仅有每一 轮比赛的最终结果会被纳入考虑,而博弈过程中的中间事件将被忽略. 如果对抗获胜,就会认为这 次对抗中所有的动作都有功劳,而与每一步具体动作有多关键无关. 这些功劳甚至会被分配给那些 从未出现的动作. 因此,进化方法在面对多智能体长时间持续性对抗任务时能力略显不足. 解决无人机集群对抗自主决策问题的另一种思路是利用强化学习方法 [10]. 强化学习是一种对 目标导向与决策问题进行理解并自动化处理的计算方法,它常用马尔可夫决策过程建立数学模型, 已在解决智能决策方面体现出不俗能力和良好发展态势,特别是在复杂动态博弈环境中. 强化学习 在智能体和环境交互的灵活性方面具备天然优势 [11]. 强化学习利用智能体与环境的直接交互来学 习,不需要可仿效的监督信号和对周围环境的完全建模,在解决持续性复杂决策任务时有较大优势. 多智能体强化学习是强化学习的一个分支,其研究多个智能体在共享环境中相互作用,并通过智能 体的学习来实现其目标. 无人机集群属于典型的多智能体系统,与单智能体强化学习相比,多智能 体强化学习的复杂度更高、更难以训练:一方面随着智能体数量的增加,相应的策略空间呈指数级 增加,其难度远超围棋等棋类游戏;另一方面随着异构智能体的加入,多智能体间需要更高效和可 靠的通信、协作和配合. 近年来,随着 AlphaGo [12]、AlphaGo Zero [13]、AlphaZero [14]、AlphaStar [15]、AlphaFold [16] 等深度强化学习 (Deep reinforcement learning, DRL) 方法的出现,深度强化学习已成为一个热门 的研究方向. Deepmind 提出了基于值方法的深度 Q 网络 (Deep Q-networks, DQN) [17],率先将 深度神经网络与 Q-Learning 相结合,为深度强化学习的发展奠定了坚实基础. 随后产生了许多基于 DQN 的变种,如 Dueling DQN [18]、Double DQN [19] 等,并获得了更好性能. 针对无人机集群博弈的复杂性和强化学习自身特点,一些学者应用强化学习对无人机集群博弈 进行了研究. Gong 等 [20] 针对多无人机协同空战问题,建立了多无人机空战环境. 提出了一种基于 网络化分散的部分可观测马尔可夫决策过程 (NDec-POMDP) 的空战协同策略框架,仿真结果验证了所提协同空战决策框架的可行性和有效性. 陈灿等 [21] 基于多智能体强化学习理论,建立多无人 机协同攻防演化模型,提出一种多无人机协同攻防自主决策方法,提高了多无人机攻防对抗的效能. Li 等 [22] 基于强化学习的演员-评论家框架,在无人机的演员网络中引入门循环单元,使得无人机 能根据历史决策信息做出合理决策,采用注意力机制来设计集中式的评论家网络,并在无人机集群 空战场景中对算法进行了验证. Zhang 等 [23] 提出了一种基于注意力机制的深度强化学习分布式方 法,该方法设计了可用于无人机协作短程作战任务的奖励函数,并采用 Unity3D 无人机仿真平台进 行了训练. 但是,在多智能体强化学习环境中,如果团队内部共同完成一个任务,则智能体会共享一个奖 励函数,从而带来多智能体的信用分配问题,即无法区分团队中某个智能体的策略对整个团队任务 的贡献. 如果不考虑信用分配问题,则可能导致智能体学到的策略是局部最优 [24]. 虽然可以为每 个智能体设计单独的奖励函数,但这些单独的奖励在合作环境中并不普遍存在,也不能鼓励单个智 能体为更大的团队利益牺牲,这将在很大程度上阻碍多智能体在挑战性任务中的学习效率. Foerster 等 [25] 提出了反事实多智能体策略梯度 (Counterfactual multi-agent policy gradient, COMA) 方法, 该方法利用反事实基线来减少估计方差,并解决了多智能体信用分配问题. 事实上,在无人机集群对抗博弈中,无人机集群内部往往需要协调和配合,以提高整体任务完 成率. 如何最大化无人机之间的协同,对信用进行合理分配,以获得最优的无人机行为策略,仍是当 前需要面对的主要挑战. 本文将 COMA 方法引入到具有无限连续状态和动作的无人机作战环境中, 基于无人机动力学和攻防态势,设计符合实际环境的击敌条件和奖励函数,构建基于多智能体深度 强化学习的无人机集群对抗博弈模型. 红蓝双方无人机采取不同的对抗博弈方法,利用多智能体粒 子群环境进行非对称性对抗实验,使用平均累积奖励、平均命中率和平均胜率作为评价指标. 结果 表明平均累积奖励能够收敛到纳什均衡,COMA 方法比其它流行的深度强化学习方法更具优越性, 对 COMA 方法收敛性和稳定性的验证分析保证了其在无人机集群对抗任务上的实用性和鲁棒性.