

摘要
机器学习,特别是深度学习,在过去的几十年中经历了研究兴趣和实际应用的爆炸式增长。深度学习方法似乎已成为许多领域的首选方法,超过了使用更传统的机器学习方法。这种转变也与基于领域知识的特征工程的转变相吻合。相反,常见的深度学习理念是通过表达模型和大型数据集的组合来学习相关特征。
有些人将这种范式转变解释为领域知识的消亡。我认为领域知识仍然广泛用于深度学习系统,甚至至关重要,但是领域知识的使用地点和方式已经发生了变化。为了支持这一论点,我展示了三个最近在不同领域中的深度学习应用程序,每个应用程序都严重依赖于领域知识。基于这三个应用程序,我讨论了如何将领域知识有效地整合到新的深度学习系统中的策略。
引言
领域知识是与特定问题、系统或主题相关的知识。与领域知识相对应的是一般知识,它与问题无关,或者至少适用于多个问题。在机器学习应用的上下文中,领域知识来自应用而不是机器学习文献。
领域知识对于许多机器学习应用很有用,因为它可以用来在模型遇到数据之前产生强烈的偏差。强烈的偏差可以通过多种方式改进模型,包括减少达到预期性能所需的数据量。这种数据效率的提高对于许多应用都非常有用,因为收集训练数据可能既困难又昂贵。监督学习是最常见的机器学习形式之一,它加剧了对数据效率的需求,因为它需要构建一组标签来伴随训练数据。人工注释器是训练标签的最常见来源,尽管某些应用可能能够使用特定于问题的元数据自动创建标签
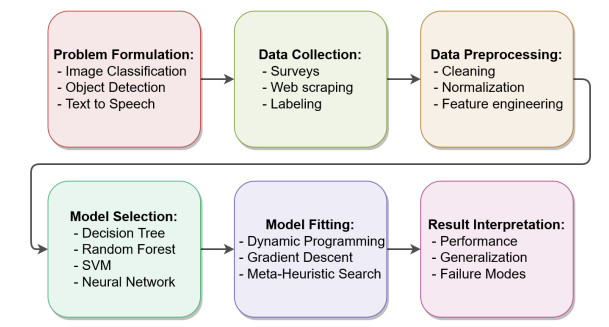
图 1.1:典型机器学习应用的开发流程,分为六个步骤。
一个典型的机器学习应用的开发流程大致包括六个步骤:问题制定、数据收集、数据预处理、模型选择、模型拟合、结果解释。在问题制定过程中,必须选择一个问题并将其形式化。问题提出后,必须收集相关的训练数据,如果要使用监督学习,则必须构建标签。一旦收集了训练数据,就需要对其进行处理,以便将其馈送到机器学习模型中。当数据已经被正确地清理和编码后,就需要选择一个合适的模型。选择候选模型后,它会适合训练数据。最后,评估程序允许模型的性能,评估期间产生的任何结果都需要解释。图 1.1 总结了这个管道。
在传统的机器学习管道中,领域知识在问题制定、数据收集、数据预处理、模型选择和结果解释过程中极为重要 [162,5,267]。领域知识在问题制定中起着重要作用,它会影响要调查的问题,并作为机器学习社区的重要过滤器。此外,领域知识通常会塑造所考虑的问题形式,因此如果成功,应用可以与现有工具和基础架构进行交互。有效的数据收集需要领域知识来识别应该收集的特征。
问题制定和数据收集至关重要,因为它们为任何成功的机器学习应用提供了基础,但机器学习研究社区近年来更多地关注管道的剩余步骤。特别是,数据预处理步骤受到了很多关注,通常在特征工程的框架下[141、61、270、129]。
模型选择可以包括直接使用现有模型、修改或扩展现有模型,或者开发全新的模型。然而,大多数应用由于高开发成本而避免创建新的模型类型,而是选择直接使用或修改现有的最先进模型。
模型拟合往往受领域知识的影响较小,因为它主要由模型内生的机制驱动。结果解释几乎完全由模型性能评估组成,目的是了解性能的不同方面,例如泛化属性和故障模式。领域知识对于为性能评估提供特定领域的框架特别有用,这使领域专家更容易理解新应用的有效性[173]。此外,许多应用很难使用通用性能指标进行评估,因此特定领域的指标可以为模型性能提供相对和绝对的参考框架。
使用深度学习构建的新应用倾向于在数据预处理上花费更少的资源,而是使用更大的数据集和更具表现力的模型组合,这些模型可以有效地学习如何从数据中提取显着特征 [141, 117]。通过学习从相对原始的数据中提取相关特征,只要有足够的标记训练示例可用,深度学习方法就可以更容易地应用于新数据集。深度学习领域极大地扩展了迁移学习的有效性和易用性,这涉及在大型且相当通用的数据集上训练模型,然后在较小的特定问题数据集上进行微调。深度学习社区将重点放在为数据类别(向量、序列、图像、视频等)而不是特定数据集构建模型上。
领域知识的作用减弱一直是机器学习社区中一些人关注的一个原因。深度学习在很大程度上无需领域知识就能发挥作用的能力导致了研究的激增,这些研究包括“算法性能之间的盲目比较,而这些算法的性能几乎没有揭示领域特征的影响”[133]。在没有领域知识的情况下依赖深度学习可能会导致应用性能不佳,因为这些应用的数据收集成本很高,导致数据集较小,可能没有足够的样本来训练有效的特征提取器。
尽管有些人担心,但其他人仍在继续研究如何在深度学习应用中最好地使用领域知识 [246, 172, 207, 264, 265, 260]。似乎已经达成共识,领域知识的重要性随着可用训练数据量的减少而增加。当应用程序涉及新数据源或问题形式时,领域知识也很重要,在这种情况下,它可以减少识别或构建有效初始特征集所需的探索性分析量。
在接下来的章节中,我将介绍三个最近的深度学习应用,作为研究领域知识使用的这些变化的背景。第一个应用是壳层识别的卷积方法 (CASI),它来自天体物理学领域,天文学家有兴趣在望远镜捕获的大量成像数据中自动检测感兴趣的结构。第二个应用,抗微生物肽生成对抗网络 (AMPGAN),来自分子生物化学领域,化学家对开发具有特定特性的肽感兴趣。第三个也是最后一个应用,基于智能体的市场微观结构模拟,来自金融市场建模领域,建模者希望开发能够更好地为政策和系统设计提供信息的基于智能体的金融市场。
这些应用来自不同的领域,但至少有两个共同特点:使用深度学习来解决具有挑战性的现实问题,以及对领域知识的依赖。通过了解这些应用如何以及在何处利用领域知识,我们可以更好地了解未来应用的有效策略。尽管这一覆盖范围还远未完成,但它提供的证据表明,领域知识对于问题制定、数据收集、模型选择和结果解释仍然至关重要。
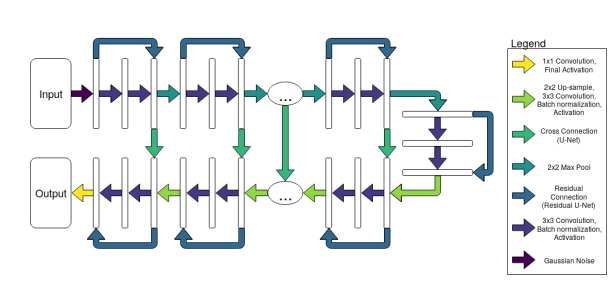
(示例1:天文物理学领域)图 2.1:我们的 Residual U-Net 架构的流程图样式描述,它将具有尺寸(图像数量、图像高度、图像宽度、图像通道数)的 4D 图像堆栈映射到 4D 图像堆栈(图像数量、图像高度、图像宽度、输出通道数)。在天文学数据的背景下,所讨论的“图像”可能是观测数据量的切片,而高度/宽度实际上是观测数据的高度和宽度(以像素/体素为单位)。在这项工作中,我们只使用单个输入图像通道(体素中的气体密度,体素中的CO强度等),但是,可以使用多个输入图像通道为网络提供多种数据。网络的前半部分使用下采样操作来压缩输入特征并构建更高级别的表示,而网络的后半部分使用上采样操作来重构抽象表示。交叉连接允许来自下采样路径的信息在上采样路径中使用,导致映射受益于粗粒度和细粒度特征的组合。椭圆内的省略号表示架构的深度是可变的,并且可以由用户修改。
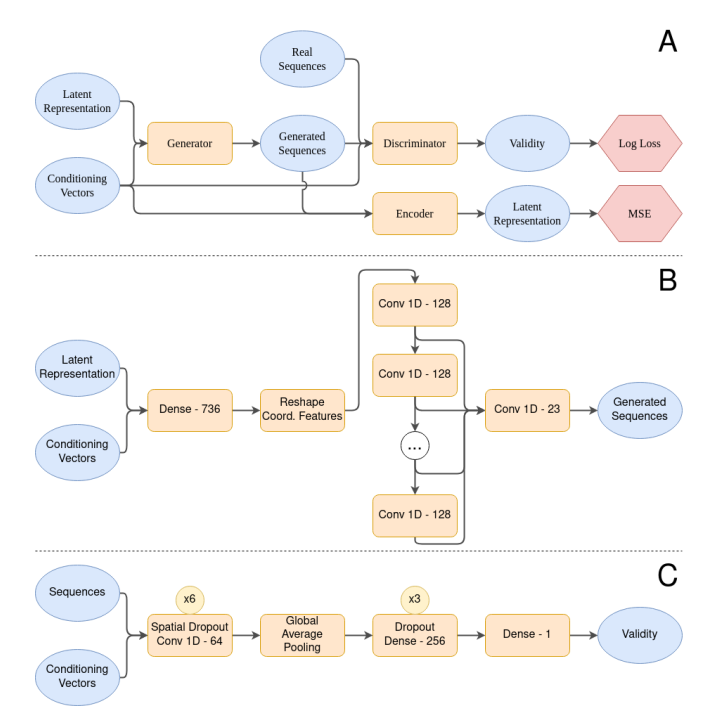
(示例2:生物医学领域)图 3.3.2:A) AMPGAN v2 宏架构。 AMPGAN v2 是一个 BiCGAN,由三个网络组成:生成器、鉴别器和编码器。鉴别器预测是否生成样本,并使用对数损失进行更新。生成器合成样本,并更新以最大化判别器的损失。编码器将序列映射到生成器的潜在空间,并使用均方误差 (MSE) 进行训练。 B) 生成器架构细节。我们在中央堆栈中使用 6 个卷积层,每个卷积层的内核大小为 3,具有指数膨胀率。所有密集层和卷积层之后都是泄漏的 ReLU 激活,除了最后的卷积层,它具有双曲正切激活。最终卷积的内核大小为 1。 C) 鉴别器架构细节。卷积使用 4 的过滤器大小和 2 的步幅。Dropout 和 Spatial Dropout 的所有应用都使用 25% 的丢弃率。所有密集层和卷积层之后都跟着一个泄漏的 ReLU 激活,除了最后一个密集层,它有一个 sigmoid 激活。条件向量被平铺并与特征/通道维度上的序列连接。编码器使用相同的架构,在最后一层具有不同的输出维度,对应于所选的潜在空间维度和线性激活函数。
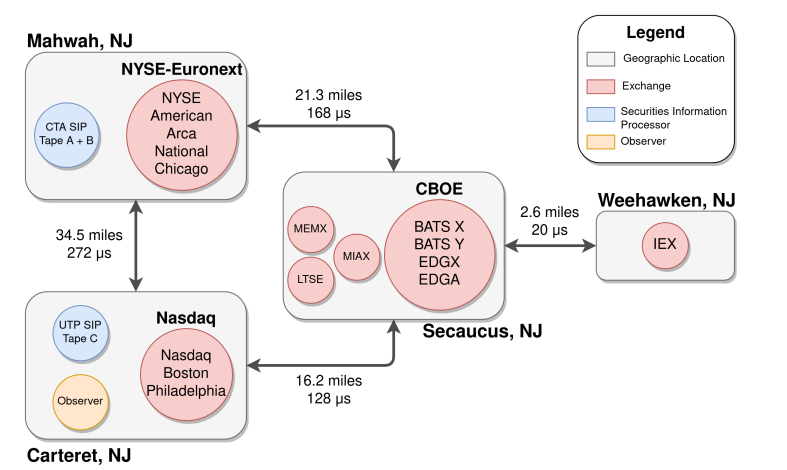
(示例3:金融领域)图 4.4.1:ABMMS 默认配置的可视化摘要。 Tivnan 等人采用了拓扑和传播延迟。四个数据中心分布在新泽西州北部。 16 个交易所和 2 个 SIPS 的选择是基于我们对 2021 年初 NMS 的理解。除非另有说明,否则交易者随机分布在四个数据中心。 ABMMS 的每个配置都有一个位于 Carteret 节点的观察器,用于从模拟中导出数据以进行分析。

