矩阵分解就能击败深度学习!MIT发布时序数据库tspDB:用SQL做机器学习
![]()
新智元报道

新智元报道
编辑:LRS
【新智元导读】时间序列预测问题通常比普通机器学习更棘手,不仅需要维持一个增量数据库,还需要实时预测的性能。最近MIT的研究人员发布了一个可以通过SQL创建机器学习模型的数据库,不用再发愁时序数据管理了!
人类从历史中学到的唯一教训,就是人类无法从历史中学到任何教训。
「但机器可以学到。」 ——沃兹基硕德

无论是预测明天的天气,预测未来的股票价格,识别合适的机会,还是估计病人的患病风险,都可能对时间序列数据进行解释,数据的收集则是在一段时间内对观察结果的记录。
但使用时间序列数据进行预测通常需要多个数据预处理的步骤,并且需要用到复杂的机器学习算法,对于非专业人士来说,了解这些算法的原理和使用场景是一件不容易的事。

最近,来自麻省理工学院的研究人员开发了一个强大的系统工具tspDB方便用户处理时序数据,能够在现有的时间序列数据库之上直接整合预测功能。系统包含了很多复杂的模型,即使非专家也能在几秒钟之内完成一次预测。在执行预测未来值和填补缺失数据点这两项任务时,新系统比最先进的深度学习方法更准确、更高效。论文发表在ACM SIGMETRICS会议上。

tspDB性能提升的主要原因是它采用了一种新颖的时间序列预测算法,这种算法在对多变量时间序列数据进行预测时特别有效。多变量指的是数据有一个以上的时间依赖变量,例如在天气数据库中,温度、露点和云量的当前值都依赖于其各自的过去值。
该算法还可以估计多变量时间序列的波动性,以便为用户提供模型预测准确度的confidence
作者表示,即使时间序列数据变得越来越复杂,这个算法也能有效地捕捉到时间序列结构。
文章作者Anish Agarwal博士毕业于麻省理工,主要研究兴趣包括因果推理和机器学习的相互作用;高维统计;数据经济学。2022年1月作为博士后研究员加入加州大学伯克利分校的西蒙斯研究所。

处理时序数据的正确姿势
处理时序数据的正确姿势
目前机器学习工作流程的一个主要瓶颈是数据处理太耗费时间,并且中间流程也很容易出错。开发人员需要从数据存储或数据库中先获取数据,然后应用机器学习算法进行训练和预测,这个过程中需要大量的人工来做数据处理。

现在这种情况越来越严重了,因为机器学习需要吞进去的数据越来越多,更不好管理了。尤其是在实时预测领域,特别是在各种时间序列的应用场景中,比如金融和实时控制更需要好好管理数据。
要是能直接在数据库上进行预测,不就省了取数据这步了吗?
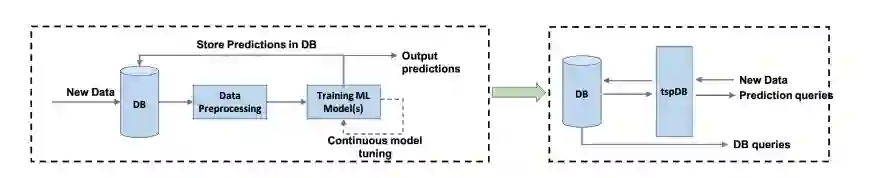
但这种在数据库上的预测集成系统不仅需要提供一个直观的预测查询界面,防止重复数据工程;同时还需要确保准确率可以达到sota,支持增量的模型更新,比较短的训练时间和较低的预测延迟。
tspDB就是直接与PostgreSQL集成,内部原生支持多个机器学习算法,例如广义线性模型、随机森林、神经网络,在训练模型的时候也可以在数据库里调节超参数。
和其他数据库不同的是,tspDB的一个重要出发点「终端用户」如何与系统对接来获得预测值。
为了让机器学习的接口更通用,tspDB采用了一种不同的方法:把机器学习模型从用户中抽象出来,争取只用一个单一的界面来响应标准的数据库查询和预测查询,也就是都用SQL来查询。
在tspDB中,预测性查询的形式与标准SELECT查询相同。预测性查询和普通查询的区别就是一个是模型预测,另一个是检索。
比如数据库里只有100条数据,想预测第101天的值,就用PREDICT关键词,WHERE day = 101即可;而WHERE day = 10时就会被解析第10天的股票价格的估算值/去噪值,所以PREDICT还可以用于预测缺失值。

为了实现PREDICT查询,用户需要利用现有的多元时间序列数据先建立一个预测模型。CREATE的关键字可以用于在tspDB中建立预测模型,输入的特征也可以是多个数据列。
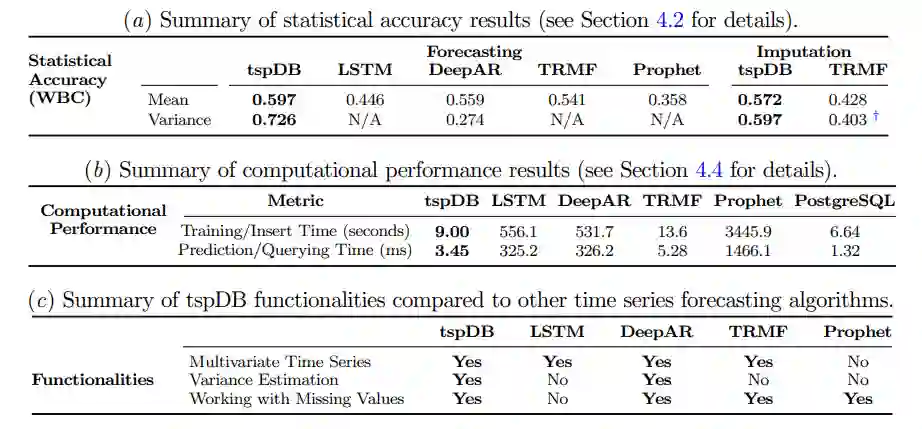
tspDB与PostgreSQL DB相比,在标准的多变量时间序列数据集上,在tspDB中创建预测模型所需的时间是PostgreSQL批量插入时间的0.58倍-1.52倍。在查询延迟方面,在tspDB中回答一个PREDICT查询所需的时间是回答一个标准的PREDICT查询的1.6到2.8倍,与回答一个标准的SELECT查询相比,要高出1.6到2.8倍。
从绝对值来看,这相当于回答一个SELECT查询需要1.32毫秒,而回答一个预测查询需要3.5毫秒,回答一个归纳/预测查询需要3.36/3.45毫秒。
也就是说,tspDB的计算性能接近于从PostgreSQL插入和读取数据所需的时间,基本上可以用于实时预测系统。
因为tspDB还只是一个概念的验证,相当于是PostgreSQL的一个扩展,用户可以对单列或多列创建预测查询;在时间序列关系上创建单列或多列的预测查询,并提供预测区间的估计值。最重要的是,代码是开源的。
代码链接:https://github.com/AbdullahO/tspdb
文章中还提出一个基于时间序列算法的矩阵分解算法,通过将多变量时序数据Page Matrix堆叠起来后,使用SVD算法进行分解,在子矩阵中移除最后一列作为预测值,使用线性回归对目标值进行预测即可。
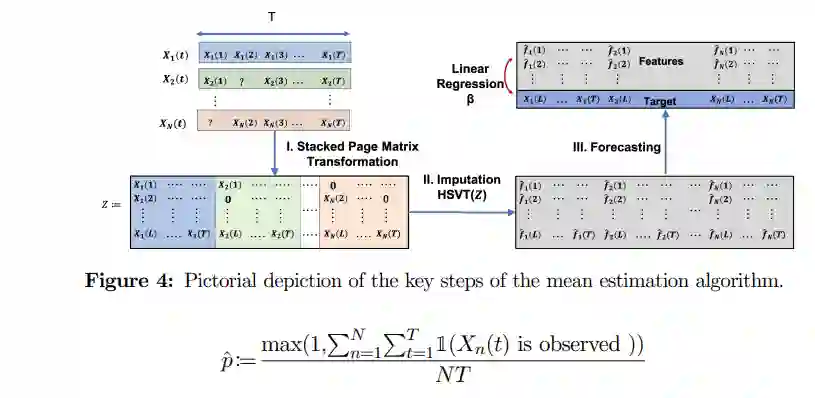
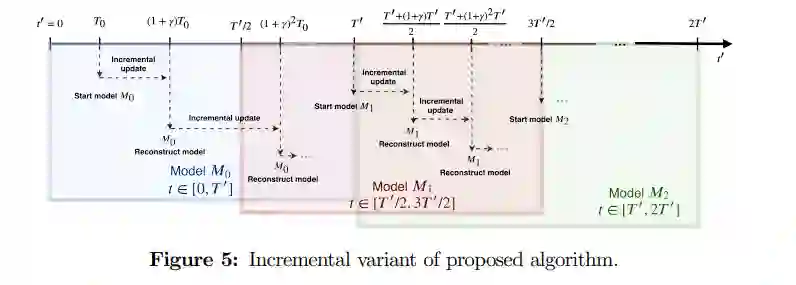
对于不断涌入的时序数据,算法还支持增量的模型更新。
为了对算法进行性能测试,研究人员选择了三个现实世界的数据集,包括电力(Electricity)、交通(Traffic)和金融(Finance)。评价指标采用Normalized Root Mean Square Error (NRMSE)作为准确率。为了量化不同方法的统计准确性,研究人员还加了一个标准Borda Count (WBC)的变体作为评价指标,0.5的值意味着算法的表现和其他算法相比就是平均水平,1代表相比其他算法具有绝对优势,0代表绝对劣势。
将tspDB的预测性能与学术界和工业界最流行的时间序列库如LSTM、DeepAR、TRMF和Prophet进行比较后可以发现,tspDB的表现与深度学习算法(DeepAR和LSTM)相比都相差不多,并且超过了TRMF和Prophet。
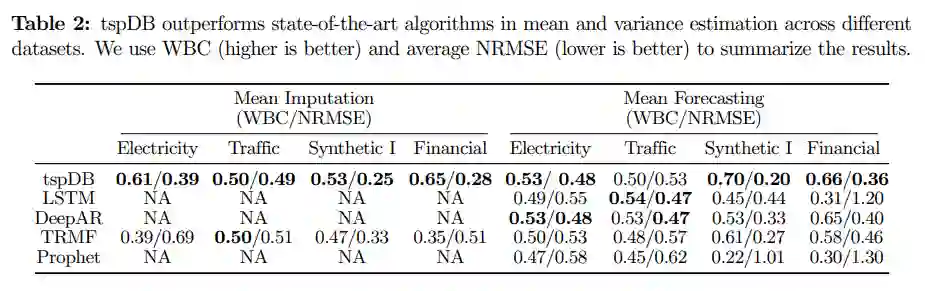
当改变缺失值的比例和添加的噪声时,tspDB在50%的实验中是表现最好的方法,在80%的实验中至少是表现第二好的。使用WBC和NRMSE这两个指标,tspDB在电力、金融数据集中的表现优于其他所有算法,而在交通数据集中的表现可与DeepAR和LSTM匹敌。
在方差估计上,因为我们无法获得现实世界数据中真正的基础时变方差,所以研究人员将分析限制在合成数据上。合成数据集II包括了九组多变量时间序列,每组都有不同的时间序列动态加性组合和不同的噪声观测模型(高斯、泊松、伯努利噪声)。
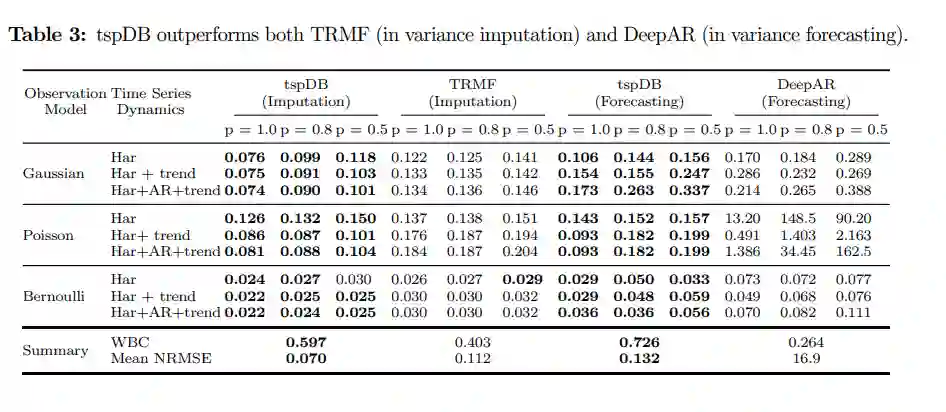
实验结果中可以发现,除了一个实验之外,tspDB在所有的实验中都比TRMF和DeepAR(用于预测)具有更高的性能(>98%)。
总的来说,这些实验显示了tspDB的稳健性,即在估计时间序列的均值和方差时,可以消除部分噪声的影响。
参考资料:
https://news.mit.edu/2022/tensor-predicting-future-0328