
图形和文本在数据挖掘中扮演着关键的角色,每种都具有独特的特性,通常需要不同的建模方法。挖掘图形数据和文本数据的技术通常是分开设计的。然而,数据经常包含这两种模态的混合,它们的信息常常相互补充。例如,在电子商务数据中,产品-用户图和产品描述提供了对产品特性的不同洞察。同样,在科学文献中,引用图、作者信息以及论文内容共同有助于模拟论文的影响力。 在本教程中,我们的重点将是探索利用预训练语言模型(PLMs)的图挖掘技术的最新进展,以及通过加入图结构信息来增强文本挖掘方法。我们将提供一个组织化的图景,展示图形和文本如何相互受益,并导致更深层次的知识发现,内容大纲如下: (1) 介绍图形和文本在现实数据中如何相互交织,以及如何设计图神经网络和预训练语言模型来从图形和文本模态中捕获信号; (2) 从文本构建图形:从文本构建句子级图形、事件图形、推理、知识图形。 (3) 使用语言模型的网络挖掘:基于语言模型的图和语言模型预训练的表示学习方法。 (4) 带有结构信息的文本挖掘:使用图结构作为辅助信息的文本分类、文献检索和问答。 (5) 朝向一个集成的语义和结构挖掘范式。 目录: * Introduction [Slides] * Part I: Introducing network structure into text corpus [Slides] * Part II: Graph Mining with LLMs [Slides] * Part III: Text Mining with Structured Information [Slides] * Summary [Slides]





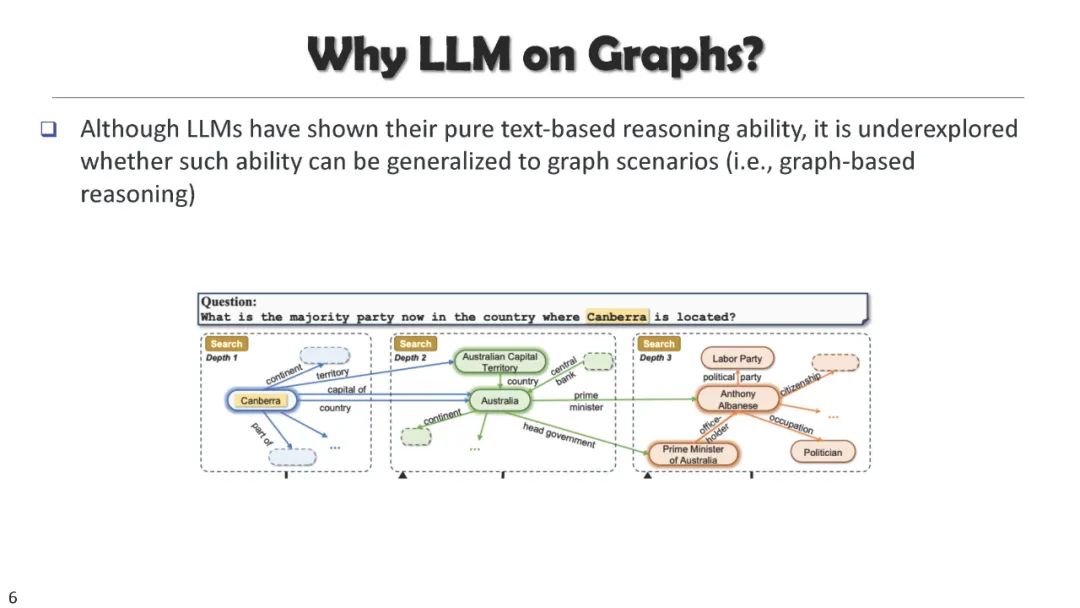

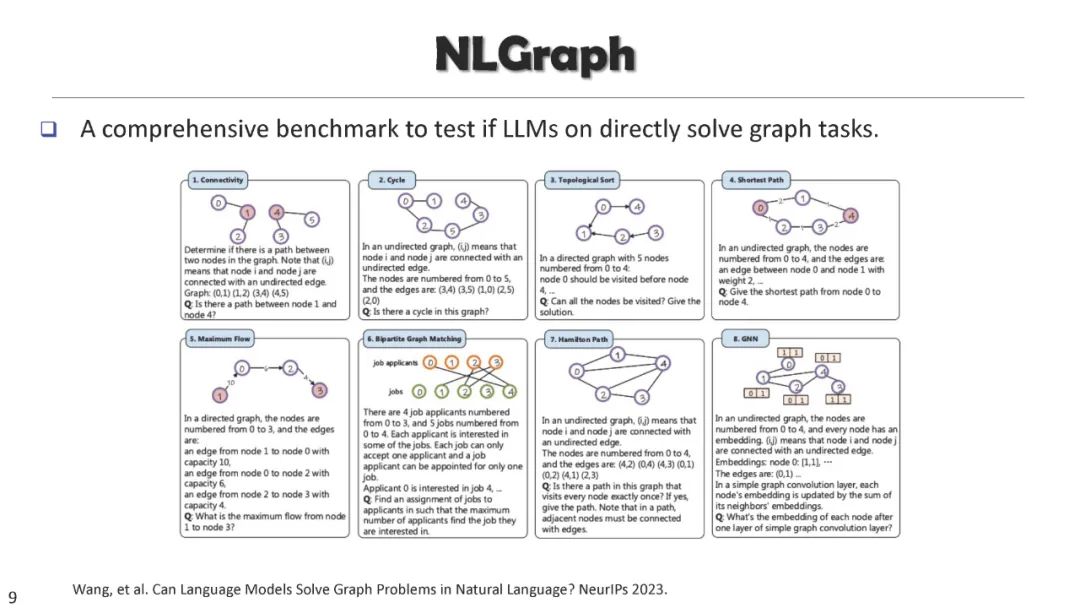

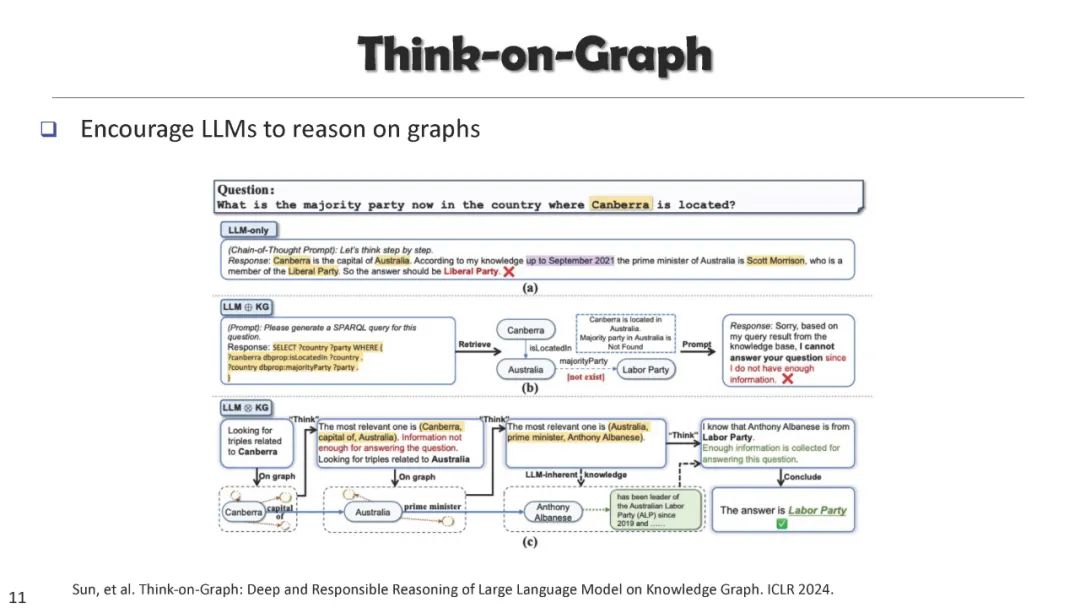
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日


相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日