

从零开始的强化学习通常需要大量样本来学习复杂任务,但是许多真实世界的应用场景却只需要从少量样本中进行学习。例如,一个有效的新闻推荐系统必须能够在仅观察到少量推荐结果后,适应新用户的口味。为了满足那些需要快速学习或适应新任务的应用的需求,本论文专注于元强化学习(meta-RL)。具体来说,我们考虑的场景是,智能体会反复接触到一些来自相同任务族的新任务。智能体必须在极少的尝试中学会每个新任务,这被形式化为与任务交互的几个阶段。智能体如何利用这些少量尝试至关重要,因为这决定了它是否能够随后解决任务,但学习如何有效使用这些尝试是具有挑战性的,因为这里没有直接的监督。
在本论文中,我们主张有效地利用这些少量的尝试——因此,快速解决新任务需要仔细地将学习如何利用少量尝试与学习解决任务相分离。具体来说,我们证明了现有的元强化学习算法如果不分离这两个问题,就会因为鸡和蛋的问题而无法学习到复杂的策略来有效地利用这些少量的尝试。鸡和蛋的问题是指,有效地利用这些少量尝试的学习依赖于已经学会解决任务,反之亦然。我们用一个新的称为Dream的算法来解决这个问题,它将这两个问题分开。此外,我们还研究了如何在这个场景中利用预先收集的离线数据。我们证明了流行的从离线数据中提取技能以快速学习新任务的方法使用了一个具有退化解决方案的欠规定目标,并通过辅助目标来解决这个问题,使优化问题明确规定。我们的算法使得元强化学习中以前未探索的应用成为可能。具体来说,我们表明:(1) Dream通过在解决并不一定需要语言的任务的过程中学习语言,为无需大型文本数据集的语言学习开启了新的范式。例如,在我们的实验中,Dream在学习如何在各种建筑中导航到特定办公室的过程中,学会了阅读带有语言描述的建筑平面图;(2) Dream可以帮助自动评估通常需要大量手动评级的交互式计算机科学作业。我们在斯坦福大学的入门计算机科学课程中部署了Dream来协助评估Breakout作业,并发现它在不牺牲准确性的情况下将评估速度提高了28%,相当于节省了大约10小时的时间。
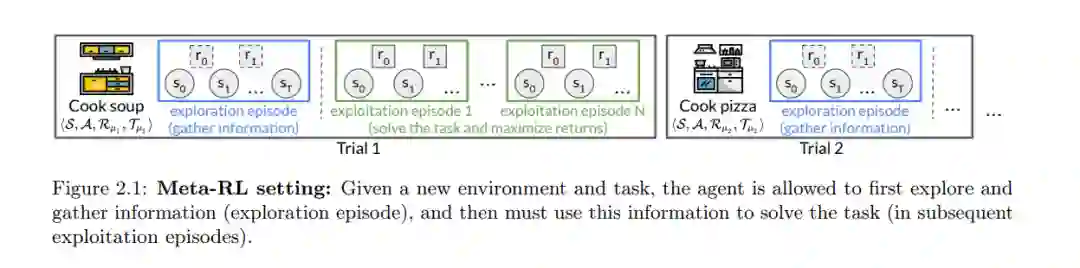
虽然在强化学习(RL)中从零开始(tabula rasa)的训练已经取得了巨大的成功,但这需要大量的数据。例如,从零开始训练以在围棋(Silver等人,2017年)、Dota 2(Berner等人,2019年)和星际争霸 II(Vinyals等人,2019年)中取得专家级的成绩,都需要数百天的TPU或GPU训练时间,相当于从常规云服务提供商那里花费数万或数十万美元。在许多应用领域,对单一任务进行如此长时间的训练,或者仅仅是获取这样的训练数据都是不切实际的——想象一下等待一百天让新闻推荐系统开始推荐好的建议,或者等待新购买的家庭机器人厨师开始烹饪。因此,这篇论文探讨了一种利用以前的经验快速学习新任务的替代范式,称为元强化学习(meta-RL)。在其核心,元强化学习试图解决与标准的从零开始的RL不同的问题。元强化学习的目标不是尝试学习一个全新的任务,而是构建可以快速适应新的,但与之前遇到的任务相关的任务的智能体,例如一个可以在新的家庭厨房中快速开始烹饪的机器人厨师,这得益于它以前的经验(例如,在许多工厂厨房中的训练)。我们主要关注典型的元强化学习环境,即智能体面临一个新任务,并首先允许有少数尝试(即,几个阶段)与任务交互,然后再被要求解决任务。例如,当被放置在一个新厨房中时,机器人厨师可能首先简要探索以寻找食材和烹饪用具,然后利用这些信息来烹制美味的饭菜。最初的几个阶段构成了智能体的“快速学习”过程,因为预计智能体在这几个阶段过后能够解决任务。
元强化学习中最初几个阶段的存在在标准的从零开始的RL中是没有的挑战,这就是如何最好地利用最初的阶段以便之后能解决任务。直观来说,学习如何有效地利用这些阶段可能面临两个主要的挑战:首先,有效地利用这些阶段可能与解决任务大不相同,所以智能体可能需要学习两种复杂的行为模式。例如,通过寻找食材来适应新厨房在质量上与烹饪一顿饭是不同的。其次,对于学习如何有效利用最初的阶段没有直接的监督——智能体在最初阶段收集的信息(例如,食材的位置)可能在智能体学习如何实际使用这些信息之前并不明显有用。因此,现有的元强化学习算法可能会遇到困难,尤其是在需要复杂且不同的行为来利用最初阶段和解决任务的任务家族中。
为了应对这些挑战,本文借鉴了一系列关于元强化学习的研究,始于Schmidhuber的开创性工作(Schmidhuber,1987年)。在深度RL时代的一些早期元强化学习方法(Finn等人,2017年;Houthooft等人,2018年)通过完全不针对最初的几个阶段进行优化,而是专注于构建能够在给定适当数据的情况下有效适应新任务的智能体,来避开了这些挑战。其他早期方法(Duan等人,2016年;Wang等人,2016a年)针对最初的几个阶段进行了优化,但是只是间接地从一个旨在最大化最终回报的端到端目标进行优化,对于最初的几个阶段并没有特别的关注。后来,Stadie等人(2018年)提出了一个观点,即最初的几个阶段最好用于收集信息或探索以找到高回报的区域,从而引领了一系列关于如何最好地进行这种探索的工作(Rakelly等人,2019年;Humplik等人,2019年;Zintgraf等人,2019年;Kamienny等人,2020年)。本文借鉴了Stadie等人(2018年)提出的信息收集观点,并认为在最初的几个阶段有效地进行探索并因此快速适应新任务,需要仔细地将学习探索和学习实际解决任务分离开来。具体来说,在第三章中,我们展示了将这两者结合在一起的算法遇到了一个鸡和蛋的问题,即学习探索依赖于已经学会解决任务,反之亦然。然后,我们提出了一种算法,Dream,它将这两者分离,从而在实际应用(第5章和第6章)上取得了更好的性能。
此外,我们还研究了如何在这种少样本元强化学习环境中有效地利用预先收集的离线数据。具体来说,我们考虑了智能体在训练期间可以访问到其他策略在各种任务上预先收集的离线数据,而智能体的目标仍然是在仅经过几个阶段后在测试时解决新的相关任务。这些离线数据可以通过几种方式来利用,包括学习动态模型(Finn等人,2016年),学习行为先验(Singh等人,2021年),或提取有意义的技能或选项(Sutton等人,1999年;Kipf等人,2019年;Ajay等人,2020年)。我们选择了最后这种方法,即从离线数据中提取常见的行为作为可以代替标准低级行为空间的高级技能,这使得学习新任务变得更容易。提取这种技能的常见方法是学习一个潜在变量模型来重建离线数据,其中潜在变量代表了提取出的技能。然而,我们发现这种方法是欠指定的,因为许多解决方案都可以等同地最大化似然性,包括退化的解决方案。然后,我们使用一个辅助目标来解决这种欠指定,这个目标最小化了提取技能的描述长度,这在直观上鼓励最大限度地提取常见的结构。我们的目标在实践中结果在语义上有意义的技能,可以加速学习新任务。
在本论文的剩余部分,我们首先在第2章中正式定义我们的少样本学习场景。然后,我们在两个主要部分中讨论快速学习新任务:在第一部分,我们讨论了快速学习新任务的算法,并克服了上述挑战,这些算法基于在智能体的少数尝试中有效地探索以揭示解决任务所需的信息(第3章),以及从离线数据中提取可复用技能(第4章)。在第二部分,我们讨论了由第一部分引入的算法所支持的两个应用,具体来说,一种新的机器语言学习范式(第5章)和自动提供初级计算机科学作业的反馈(第6章)。最后,在第7章,我们通过讨论(a)有效利用本论文中提出的元强化学习算法;以及(b)选择适合元强化学习工具箱的应用来结束。尽管元强化学习仍是一个活跃发展的领域,并且其实用性在很大程度上取决于应用的选择,但本论文的目标是为元强化学习实践者提供适用于今天实际部署的工具。





