对可解释人工智能模型的需求日益增长,这促使大量研究致力于提升强化学习(Reinforcement Learning, RL)方法生成策略的可解释性与透明度。该研究领域的一个重要方向是在强化学习解决方案中开发基于决策树的模型,因其具有内在可解释性。本研究开发基于随机森林的强化学习算法,标志着这一学术探索的合理演进。通过OpenAI Gym的三个标准基准环境——CartPole、MountainCar和LunarLander——对这些算法进行评估,并与深度Q学习网络(DQN)及双DQN(DDQN)算法在性能、鲁棒性、效率和可解释性等指标进行对比。基于随机森林的算法在三个环境中的两个表现出优于两种基于神经网络的算法,同时提供易于解释的决策树策略。然而,该方法在解决LunarLander环境时面临挑战,表明其当前在扩展至更大规模环境方面存在局限性。
人工智能(AI)致力于在机器中复现人类智能,使其能够执行包括问题解决与决策制定在内的复杂任务。近年来,AI取得显著进展,通过提升全球互联性与技术扩展推动社会变革,为即将到来的革命铺平道路(Makridakis, 2017)。
2017至2022年间,采用AI的企业比例增长逾一倍,近年稳定在50%-60%区间,这些企业报告称显著降低了成本并实现收入增长。此外,AI指数对127个国家立法记录的分析显示,含有"人工智能"术语的法案通过数量从2016年的1项增至2022年的37项;自2016年以来,全球81个国家立法程序中对AI的提及量增长近6.5倍(Maslej et al., 2023)。这一变革的核心驱动力是机器学习(Machine Learning, ML)——AI的一个专门分支,使机器无需显式编程即可直接从数据中学习。ML在AI中的广泛应用催生出日益强大的模型,标志着第四次工业革命(工业4.0)的到来(Sarker, 2022)。因此,在ML的推动下,AI引领着文本挖掘、自然语言处理、案例推理、视觉分析、计算机视觉、模式识别、搜索优化及混合系统等领域的进步(Sarker, 2022)。
凭借其独特能力,AI正被广泛应用于传统依赖人类决策的领域,此时机器决策验证变得至关重要。Bastani等(2018)指出,自动驾驶汽车、机器人控制器与空中交通管制系统是验证可解释自动决策重要性的典型案例。尽管计算机引导的进步为这些领域带来显著优势,但在关键场景中,人类监督的验证不可或缺。然而,随着高不可解释性ML方法(如深度神经网络DNN)的普及,验证过程可能低效甚至无法实现(Bastani et al., 2018)。DNN作为ML建模的重要分支,其卓越性能支撑了广泛应用(Schmidhuber, 2015),但其复杂结构使验证过程面临挑战。
由于完全自主的高性能AI代理存在遵循不透明决策的风险,对可解释AI的需求日益增长。缺乏透明度可能导致高精度模型对决策者失去价值,而更高透明度可使决策者更清晰理解AI生成的控制逻辑,简化硬件部署流程,并促进复杂系统的适应性改进(Dhebar et al., 2022)。
强化学习(Reinforcement Learning, RL)作为AI的重要分支,采用独特学习范式:通过环境交互与决策反馈实现自适应(Sutton & Barto, 2018)。RL旨在使AI代理理解状态-动作对的后果,通过试错机制掌握不同情境下的最优动作选择。Q-learning是一种通过近似最优动作价值Q函数实现目标的RL算法(Watkins & Dayan, 1992),而策略梯度法则是另一类广泛应用的基于梯度下降的RL技术(Sutton et al., 1999)。本研究聚焦离策略Q-learning方法。
传统Q-learning通过ML方法近似贝尔曼方程,迭代优化状态-动作对特征组合的价值评估及策略生成。深度强化学习(Deep Reinforcement Learning, DRL)将DNN作为RL算法中的价值函数近似机制(Arulkumaran et al., 2017)。过去十年间,DNN与Q-learning结合的深度Q学习(DQN)取得突破性进展,首个成功案例证明AI代理在雅达利游戏中的表现超越人类(Mnih et al., 2013),后续研究更训练出连续五次击败围棋世界冠军的代理(Silver et al., 2016)。虽然深度学习与RL的结合展现出强大潜力,但DNN的不可解释性限制了其可验证性。
这种可解释性缺失反映了AI/ML领域的普遍认知:高性能模型往往复杂度高且难以理解。与支持向量机(SVM)和DNN等黑箱方法不同,基于树的建模技术属于高可解释性范畴(Martens et al., 2011)。图1清晰展示了不同机器学习方法在可读性与性能间的权衡。这种权衡对决策者理解RL代理逻辑至关重要——只有理解代理决策逻辑,决策者才能有效验证或批判其行动建议(Puiutta & Veith, 2020),这也构成本研究的核心关注点。
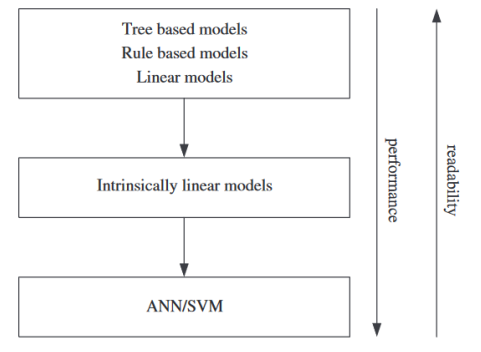
图 1. 性能与可读性的权衡。性能与可读性的权衡概括了机器学习中常见的一种现象,即实现更高性能的方法往往会牺牲用户的可读性和可解释性。改编自 Martens 等人(2011 年)。
基于此,本研究对比了基于DNN与决策树(DT)的Q-learning解决方案,旨在全面探索两类方法在精度、效率、鲁棒性与可解释性方面的权衡。作为最复杂的RL方法之一与最具可解释性的方法之间的对比,本研究以随机森林(Random Forest, RF)为DT集成基础。Breiman(2001)提出的RF通过构建多棵随机生成的分类树,利用有限信息的多树协同揭示数据特征重要性。传统ML中,集成方法通常优于单棵决策树,提示其可能在RL中展现优势。本研究的创新在于将RF应用于Q-learning,并与DQN进行对比。
传统DT与RF并非专为OpenAI Gym的流数据、在线或RL环境设计(Brockman et al., 2016),限制其在信息积累中的适应性(Silva et al., 2020)。但通过算法改良,本研究实现随机DT装袋在RL中的应用。受在线Q-learning启发(Watkins & Dayan, 1992),本研究采用类似DQN的批处理模式构建Q函数近似,理论支持源自Ernst等(2005)在Q-learning中应用DT方法确保序列收敛的研究。相较于KD-Tree、CART、Extra-Trees等DT方法,装袋技术被证明在RL中最有效(Ernst et al., 2005)。本研究创新性地采用优化的CART算法生成随机树,并应用加权装袋实现在线批处理的RF构建。
为从RL视角审视可解释AI问题,本研究选用三个典型环境:CartPole、MountainCar与LunarLander。CartPole环境因动态简单且研究基础广泛,成为初期评估的基准;MountainCar通过稀疏奖励结构与动量学习需求,检验算法在高维状态空间的效率;LunarLander则通过连续空间的精确控制需求,评估算法处理多目标复杂任务的能力。这些环境共同构成评估RL算法可解释性、适应性、鲁棒性与扩展性的综合框架(Brockman et al., 2016)。
本论文结构如下:第二章综述相关文献,系统梳理领域关键贡献;第三章详述研究方法论,涵盖研究设计、模型构建与分析技术;第四章呈现研究结果与分析;第五章总结结论并提出未来研究方向。