导读 | CVPR全称为国际计算机视觉与模式识别会议,是计算机视觉领域三大顶级会议之一,2023年将在加拿大温哥华举办。本届会议中科院自动化所共有33篇论文录用,我们将通过上下两期推文对相关研究进行简要介绍(排名不分先后),欢迎大家一起交流讨论。
来源公众号:中国科学院自动化研究所
**01. **基于分解扩散模型的高质量视频生成
Decomposed Diffusion Models for High-Quality Video Generation 作者:罗正雄,陈大友,张迎亚,黄岩,王亮,沈宇军,赵德利,周靖人,谭铁牛 最近扩散模型在图像生成上取得了巨大成功,然而其在视频生成上的应用仍旧面临挑战。之前的基于扩散模型的视频生成方法主要采用标准的扩散过程,即给视频片段中的每一帧都单独加噪,忽略了视频帧之间的时序相关性和内容上的冗余。本工作介绍了一种分解扩散模型,其将加给每一帧的噪声拆分为了一个帧间共享的基础噪声和一个帧间独立的残差噪声,并对应地使用两个联合训练的神经网络来分别估计两个噪声。实验表明,我们方法可以在主流数据集上取得更好的量化结果,同时也可以很好的支持文本到视频的生成。
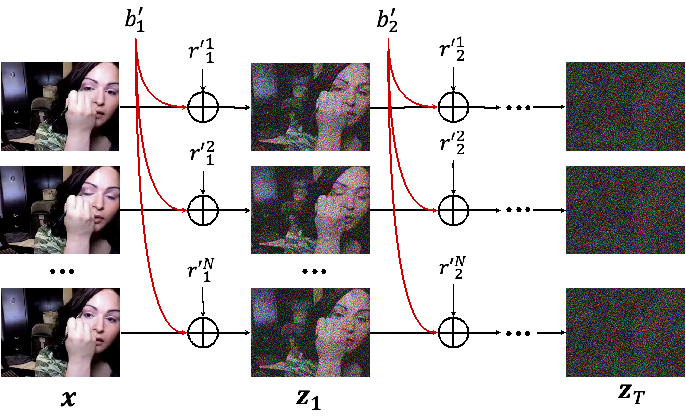
图1. 分解扩散模型的加噪过程
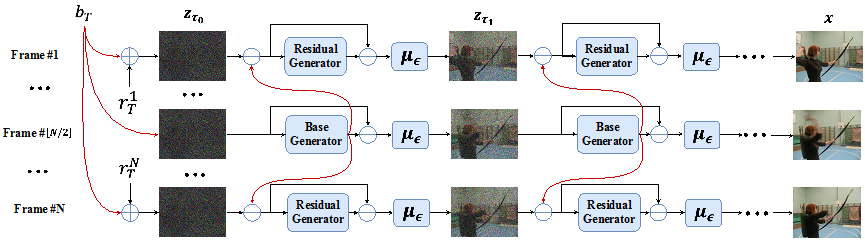
图2. 分解扩散模型的生成过程
**02. **基于语义提示的小样本学习
Semantic Prompt for Few-Shot Learning 作者:陈文弢,司晨阳,张彰,王亮,王子磊,谭铁牛 小样本学习是一个非常有挑战性的任务,因为它要求只使用少量几个示例样本学习一个全新的类别。近期的一些研究工作尝试使用语义信息来增强小样本分类器的鲁棒性,但仍存在小样本图像的特征判别能力差的问题,因此性能提升有限。本项研究工作中,我们提出了一个新的语义提示方法来解决小样本学习问题。该方法创新性地使用语义信息作为提示词,以自适应地调整特征提取器的行为,使得特征提取器获取到和语义提示相关的物体本征视觉特征。为了实现这一点,本项工作设计了两种信息交互机制,它们分别使得语义信息能够在空间维度和通道维度上和图像局部特征进行信息交互。通过将这两种机制融合,本项工作在四个小样本学习数据集上取得了领先的结果,将1-shot学习的平均精度提升3.67%。
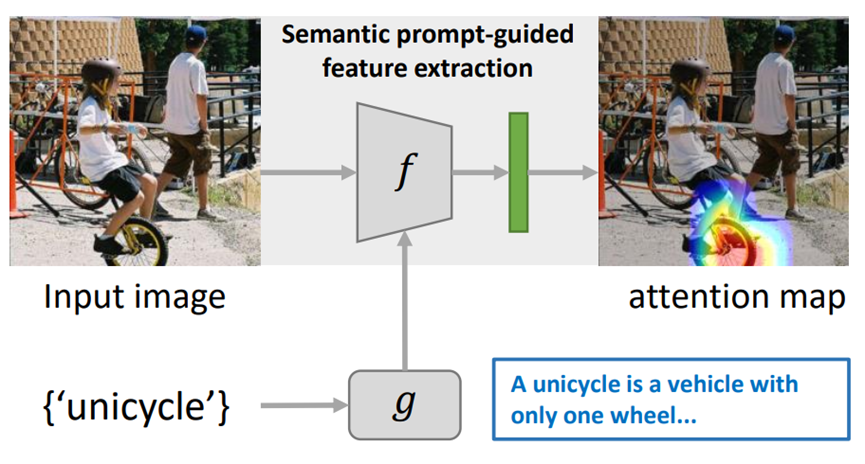
图1.语义提示方法示意图
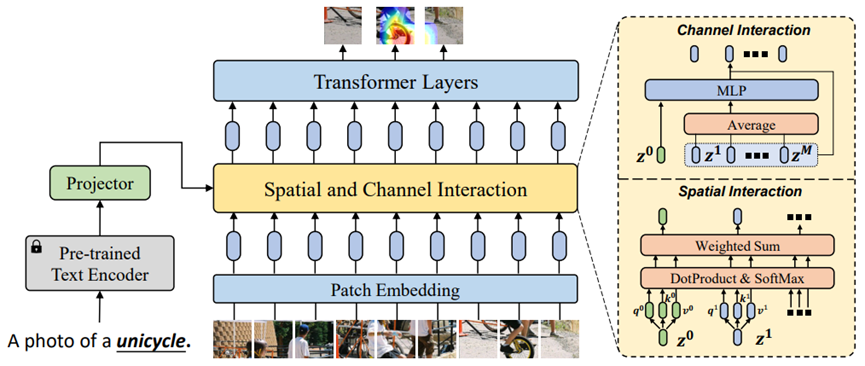
图2. 语义提示方法网络框架图
**03. **用于行人重识别的换装特征增广
Clothing-Change Feature Augmentation for Person Re-Identification 作者:韩苛,龚少刚,黄岩,王亮,谭铁牛 换装行人重识别的目标是匹配在不同摄像头下改变着装的同一个行人。当前的换装行人重识别模型训练往往会受到训练数据中不充分的衣服变化数量和程度的限制。该论文为换装行人重识别提出了一个换装特征增广(CCFA)模型用于在特征空间中大量增广换装数据。具体来说,该方法首先利用换装数据估计一个反映衣服颜色和纹理变化的换装正态分布,然后使用一个增广生成器来模拟衣服变化、身份不变的特征增广。最后,该方法采用一种基于ID的增广策略增加训练数据的ID内换装差异、减小ID间换装差异,从而迫使模型自动学习与着装无关的身份特征。该方法不仅在换装行人重识别数据集上达到了优良的准确率,而且提升了模型的泛化能力。
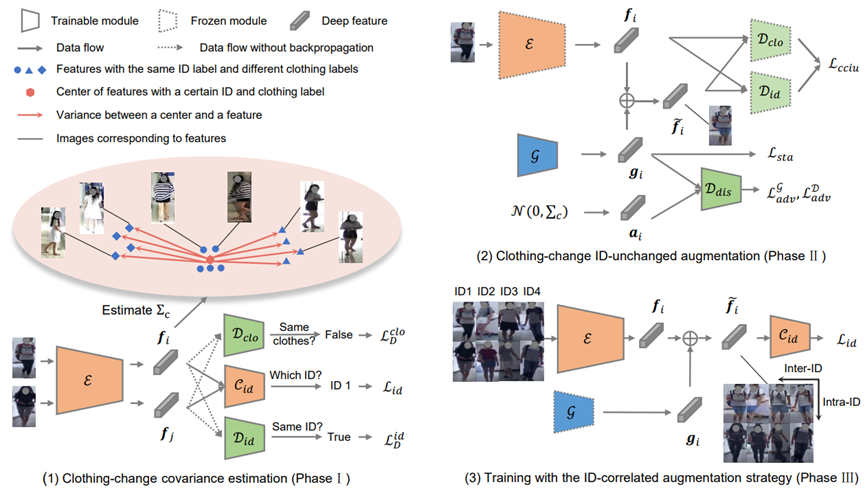
换装特征增广模型示意图
**04. **差值编辑器:探索无文本参与训练下的文本驱动图像编辑
DeltaEdit: Exploring Text-free Training for Text-Driven Image Manipulation 作者:吕月明,林天威,李甫,何栋梁,董晶,谭铁牛 文本驱动的图像编辑在训练或推理灵活性方面仍然具有挑战性。条件生成模型在很大程度上依赖于昂贵的训练数据标注。本文提出了一个名为DeltaEdit的新框架。我们的关键想法是研究和识别一个空间,即图像和文本差值空间,它在两幅图像的CLIP视觉特征差异和源文本和目标文本的CLIP文本嵌入差异之间具有良好的对齐分布。基于CLIP差值空间,DeltaEdit网络被设计为在训练阶段将CLIP视觉特征差异映射到StyleGAN的编辑方向。然后,在推理阶段,DeltaEdit从CLIP文本特征的差异中预测StyleGAN的编辑方向。通过这种方式,DeltaEdit以一种无文本的方式被训练。一旦经过训练,它可以很好地泛化到各种文本驱动的编辑上。实验证明,本方法具有较好性能,同时在训练和推理方面具有更好的灵活性。

由DeltaEdit在无文本参与训练下的多种文本驱动操作的例子
**05. **基于隐空间加解密器的可逆多样化人脸匿名
RiDDLE: Reversible and Diversified De-identification with Latent Encryptor 作者:李东泽,王伟,赵康,董晶,谭铁牛 本研究提出RiDDLE(基于隐空间加密器的可逆多样化人脸匿名),以保护人们的身份信息不被滥用。RiDDLE构建于预训练好的StyleGAN2生成器之上,能够在其隐空间内对人脸身份进行加解密。本方法生成的加密人脸,正确解密人脸以及错误解密人脸如图1所示。RiDDLE具有如下特性。第一,加密过程由密码引导,每一个密码对应独一无二的匿名身份,保证匿名过程的安全性与多样性。第二,只有使用正确的密码才能解密真实身份并恢复出原始人脸,否则系统将返回另一张匿名人脸,以保护人脸隐私信息。第三,人脸的加解密过程都基于同一个轻量级加解密器,高效便捷。与现有替代方案比较,本方法以更好的质量、更高的多样性和更强的可逆性完成了人脸匿名任务。我们进一步证明了其在视频人脸匿名任务上的有效性。

图1.人脸加解密结果
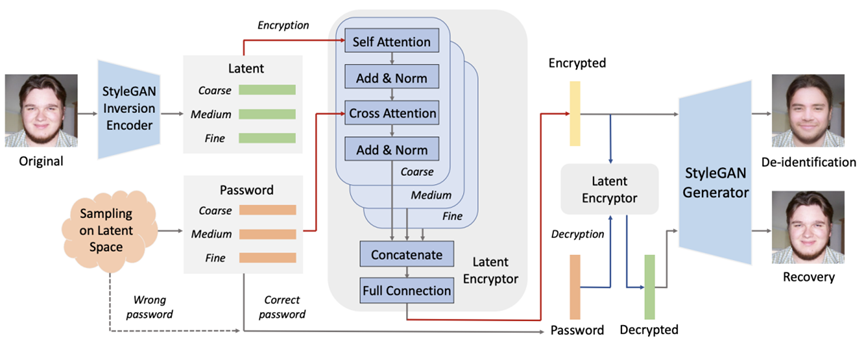
图2.本方法的训练流程图代码:https://github.com/ldz666666/RiDDLE
**06. **FrustumFormer: 自适应前景实例区域重采样的多目3D目标检测器
FrustumFormer: Adaptive Instance-aware Resampling for Multi-view 3D Detection
作者:王宇琪,陈韫韬,张兆翔 将特征从二维图像空间转换到三维空间在多目视觉下的物体检测中发挥着重要作用。最近的方法主要关注视图特征的转换,而在特征转换过程中等同地处理所有像素或网格,没有充分关注不同区域的内容差异。例如,前景的小汽车比背景的天空更具有信息量,应得到更多的关注。为了充分利用图像信息,我们认为视图特征的转换应该根据内容自适应地选择合适的区域。本文提出了名为FrustumFormer的新型检测器,它通过自适应实例感知重采样更加关注实例区域中的特征。该模型利用图像视图的候选物体区域在鸟瞰图上获取实例锥体。通过学习实例锥体内的占用掩码,进一步优化实例位置,并通过时间锥体的交集来减少位置的不确定性。实验表明,FrustumFormer具有优异的检测性能,达到新的最高水平。
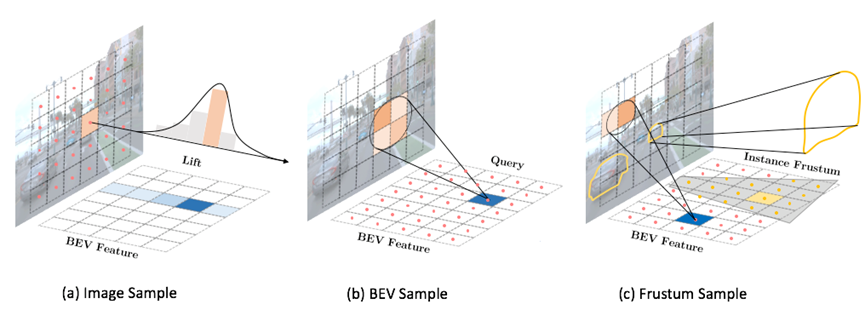
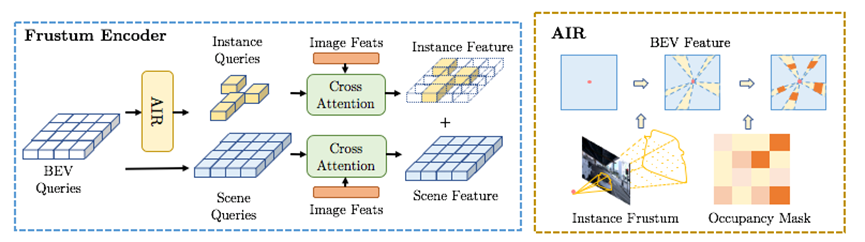
论文链接:https://arxiv.org/pdf/2301.04467.pdf
**07. **基于以物体为中心的预测模型的隐式物理概念发现
Intrinsic Physical Concepts Discovery with Object-Centric Predictive Models 作者:唐渠、朱翔昱、雷震、张兆翔 直觉物理是常识学习的重要领域,即推理宏观物体的性质和相互作用所依据的概念知识。然而尽管付出了相当大的努力,人工智能领域还没有提出一个对直觉物理的理解可以与年幼的儿童相媲美的系统。基于发展心理学的启发,我们提出一个深度学习系统PHYCINE(PHYsical Concept Inference NEtwork),通过对输入的观测分离表示场景中各个物体的显式外观属性(颜色、大小、形状…),借助物理事件推断物体的隐式物理属性(速度、质量、电荷),以赋予模型类人的物体物理属性表示,使其能够处理物理世界的运行规则以处理更为上层的任务,例如因果推理、视频预测等。我们在包含不同质量和电荷量的多物体交互场景数据集训练模型,可以成功推断解耦的物理概念,并有效提升物理事件相关的因果推理任务。
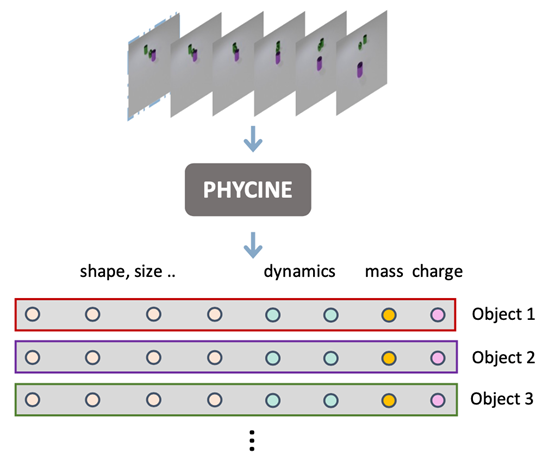
PHYCINE模型图
**08. **用于域泛化的锐度感知梯度匹配
Sharpness-Aware Gradient Matching for Domain Generalization 作者:王鹏飞,张兆翔,雷震,张磊 最近开发的锐度感知最小化(SAM)方法旨在通过最小化损失景观的锐度度量来提高模型的泛化能力。尽管SAM及其变体已经展示了令人印象深刻的DG性能,但它们可能并不总是以较小的损失值收敛到所需的平坦区域。本文首先提出了两个条件来确保模型以较小的损失收敛到平坦的最小值,然后提出了一种名为锐度感知梯度匹配(SAGM)的算法来满足这两个条件以提高模型的泛化能力。具体来说,SAGM的优化目标将同时最小化经验风险、扰动损失(即参数空间中邻域内的最大损失)以及它们之间的差距。通过隐式对齐经验风险和扰动损失之间的梯度方向,SAGM在不增加计算成本的情况下提高了SAM及其变体的泛化能力。广泛的实验结果表明,我们提出的SAGM方法在五个DG基准测试中始终优于最先进的方法。
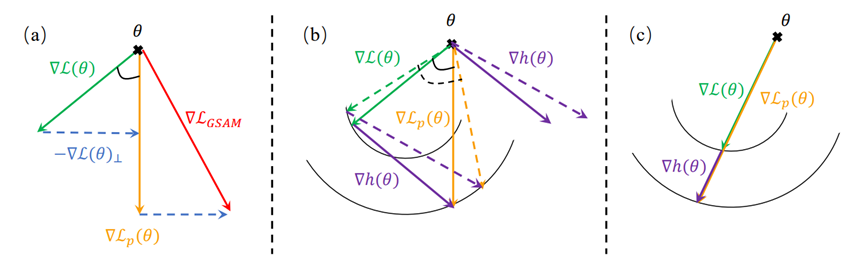
SAGM算法的motivation的简要说明 代码即将开源在: https://github.com/Wang-pengfei/SAGM
**09. **基于以物体为中心的可学习全局优化的三维视频物体检测
3D Video Object Detection with Learnable Object-Centric Global Optimization 作者:何嘉伟、陈韫韬、王乃岩、张兆翔 在这项工作中,我们研究了利用基于长时序视觉对应的优化来进行三维视频物体检测。视觉对应是指多个图像中像素的一对一映射。基于对应的优化是三维场景重建的基石,但在三维物体检测中研究较少,因为运动物体违反了多视图几何约束,在场景重建过程中被视为异常值而被过滤掉。我们通过在优化过程中以物体为中心来解决这个问题。在这项工作中,我们提出了BA-Det,一种端到端可优化的三维物体检测器,并设计了以物体为中心的时序对应学习和以特征度量的物体光束法平差损失函数。在实验上,我们验证了BA-Det在各种实验设置下的有效性和高效性。我们的BA-Det在大规模Waymo开放数据集(WOD)上实现了SOTA性能,仅需很少的额外计算成本。
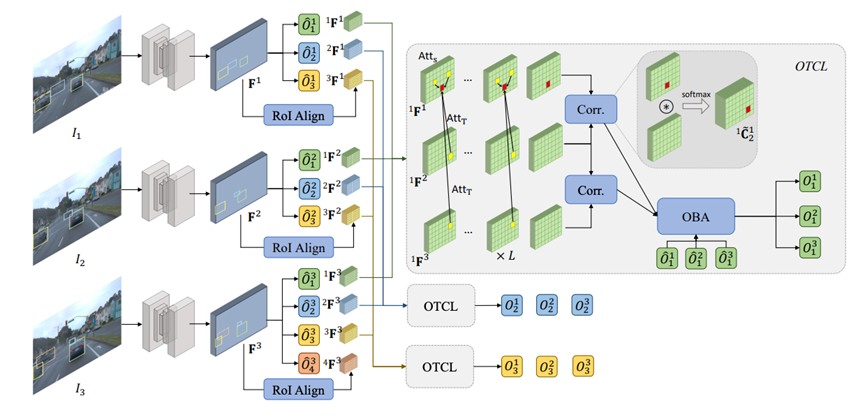
BA-Det模型示意图
**10. **用于鸟瞰图语义分割的双向前置交互Transformers模型
BAEFormer: Bi-directional and Early Interaction Transformers for Bird’s Eye View Semantic Segmentation 作者:潘聪,何泳澔,彭君然,张骞,隋伟,张兆翔 基于纯视觉的感知方法由于其较高的信噪比和较低的成本,逐渐在自动驾驶领域中占有重要地位,其中,鸟瞰图(BEV)语义分割是重要任务之一。现有方法是先提取图像特征再利用图像特征与BEV特征的单向交互,将透视图(PV)转换为BEV,PV-BEV转换仍然具有挑战性。我们提出了一个新的双向和前置交互的Transformers框架,称为BAEFromer,包括(1)一个前置的相互作用的PV-BEV管道和(2)一个双向的交叉注意机制。此外,我们发现在交叉注意力模块中,图像特征图的分辨率对于最后的性能影响不大,在这一关键观察结果下,通过扩大输入图像的大小,并对环视图像特征进行降采样再进行交互,可进一步提高性能同时保持计算量的可控性。BEV语义分割方法的有效性在nuScenes数据集上得到验证,并且在实时推理模型中达到了最好的性能。
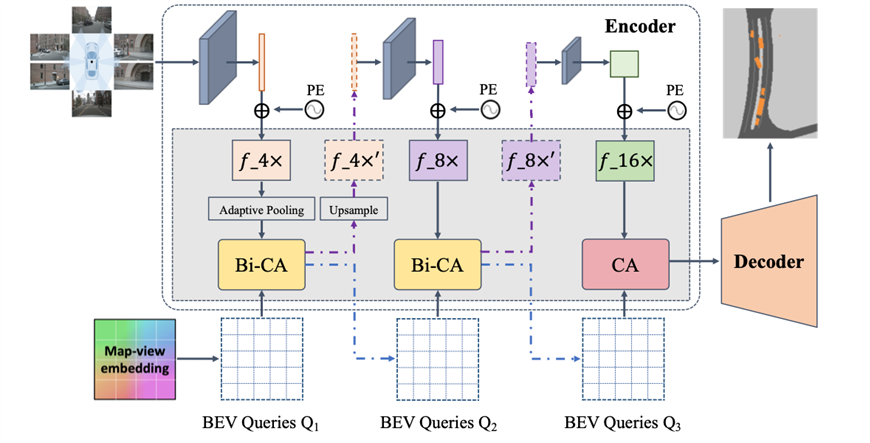
BAEFromer模型示意图
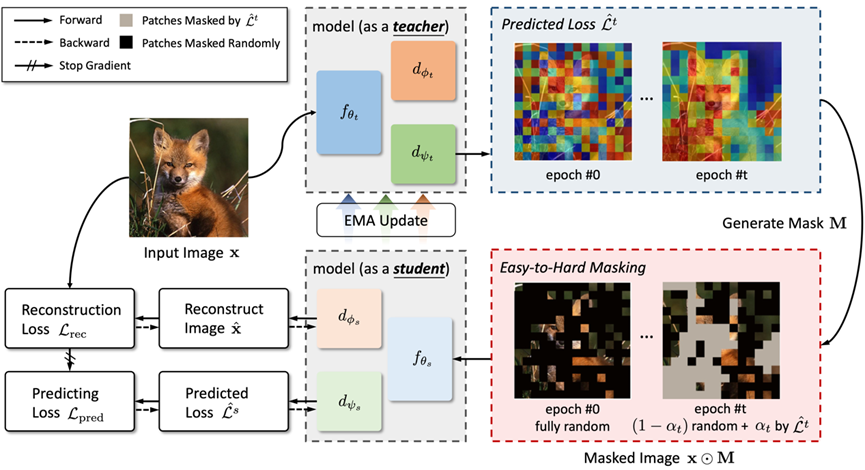
**11. **自监督掩码学习中的困难样本挖掘
Hard Patches Mining for Masked Image Modeling 作者:王淏辰,宋开友,樊峻菘,王玉玺,谢津,张兆翔 自监督掩码学习(Masked Image Modeling,MIM)引起了许多研究人员的关注。在典型的方法中,模型通常专注于预测掩码图块的特定内容,其性能与预定义的掩码策略密切相关。这个过程可以被视为训练一个学生(模型)解决给定的问题(预测掩码图块)。然而,我们认为模型不仅应该专注于解决给定的问题,还应该站在教师的角度,自己提出更具挑战性的问题。为此,我们提出了一种全新的MIM预训练框架——Hard Patches Mining(HPM)。我们观察到,重建损失自然可以作为预训练任务的难度指标。因此,我们引入了辅助损失预测器,首先预测每个图像块的损失,并决定下一步应该遮蔽哪些部分。实验表明,HPM在构建掩码图像方面具有有效性。 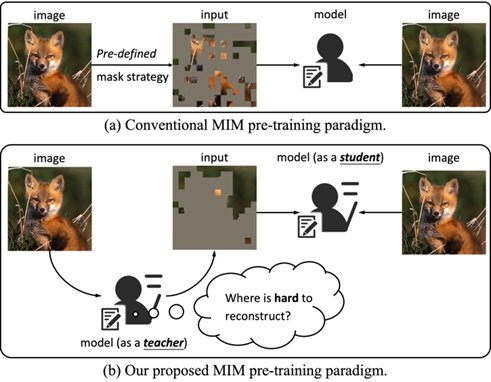
12. 基于有缺陷图层和神经过滤的盲视频去闪烁
Blind Video Deflickering by Neural Filtering with a Flawed Atlas 作者:雷晨阳 任烜池 张兆翔 陈启峰 许多视频都存在闪烁问题,导致闪烁的常见原因包括视频处理算法、视频生成算法或在特定情况下捕获视频。为了消除闪烁,之前的工作通常需要特定的指导,如闪烁频率、手动标注或额外一致的视频。本研究提出了一个通用的闪烁消除框架,只接收一个闪烁的视频作为输入而无需额外的指导。由于它不需要知道特定的闪烁类型或指导,我们将其命名为“盲去闪烁”。方法的核心是结合神经图层与神经过滤策略。神经图层是视频中所有帧的统一表示,可提供时间一致性指导,但在许多情况下存在缺陷。为此,我们训练了一个神经网络来模拟过滤器,该过滤器从图层中学习时域一致的特征并避免引入图层伪影。为了验证我们的方法,我们构建了一个包含各种真实世界闪烁视频的数据集。广泛的实验表明,本方法实现了令人满意的去闪烁性能,甚至在公共基准测试中优于使用额外指导的基线。

盲去闪烁效果图
代码:https://chenyanglei.github.io/deflicker
**13. **BEVFormer v2: 通过透视监督将现代图像骨干网络应用于鸟瞰视图识别
BEVFormer v2: Adapting Modern Image Backbones to Bird’s-Eye-View Recognition via Perspective Supervision
作者:杨晨煜,陈韫韬,田昊,陶辰昕,朱锡洲,张兆翔,黄高,李弘扬,乔宇,卢乐炜,周杰,代季峰
我们提出了一种新颖的鸟瞰图(BEV)检测器,具有透视监督,可以更快地收敛,并更适合现代图像骨干网络。现有的最先进的BEV检测器通常与特定的深度预训练骨干网络(如VoVNet)绑定在一起,阻碍了蓬勃发展的图像骨干网络和BEV检测器之间的协同作用。为了解决这个限制,我们优先考虑通过引入透视视图监督来简化BEV检测器的优化。为此,我们提出了一个两阶段的BEV检测器,其中来自透视头的提议被送入BEV头进行最终预测。为评估我们的模型的有效性,我们进行了广泛的消融实验,重点关注监督形式和所提出的检测器的通用性。该方法通过广泛的传统和现代图像骨干网络进行验证,并在大规模的nuScenes数据集上实现了新的SoTA结果。
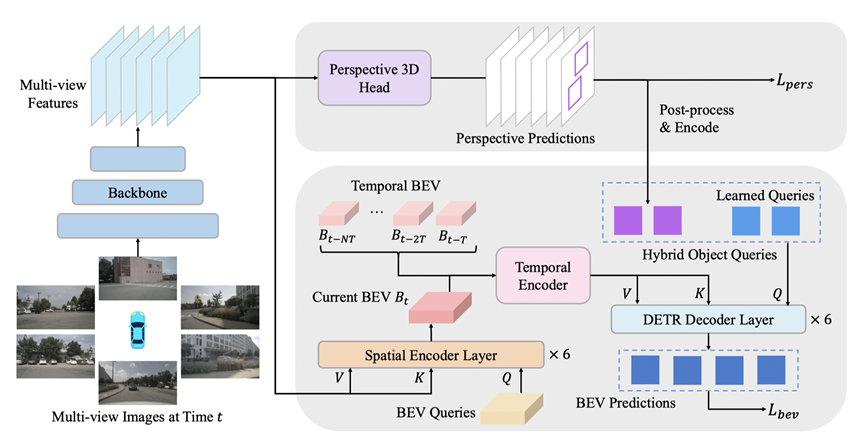
BEVFormer v2模型示意图 全文链接:https://arxiv.org/abs/2211.10439
**14. **基于超令牌采样的视觉Transformer网络设计
Vision Transformer with Super Token Sampling 作者:黄怀波,周晓强,曹杰,赫然,谭铁牛 基于Transformer的视觉主干网络在众多计算机视觉任务中取得了优异的性能表现,但其在网络浅层提取局部特征的过程中,存在着大量的表征冗余。一些方法采用局部自注意力机制和卷积层来避免这一问题,但会弱化模型对于全局特征依赖的建模。本文要解决的问题,就是如何在浅层网络中高效地提取全局特征。受传统计算机视觉中超像素的启发,我们提出超令牌的概念。在视觉Transformer中引入超令牌的设计,可以通过减少图像基元的数量来减少自注意力模块的计算量,并实现对全局特征依赖关系的高效建模。具体地:首先通过稀疏关联的方式,来从特征中采样超令牌。然后在超令牌空间执行自注意力计算过程,并将计算后的特征图投影回原始的图像空间。这种基于超令牌的自注意力机制STA将原始的全局自注意力计算分解为稀疏关联矩阵和低维空间自注意力图的乘积。基于STA,本文设计了一种层次化的视觉Transformer主干网络SViT,在众多视觉任务上取得领先性能。
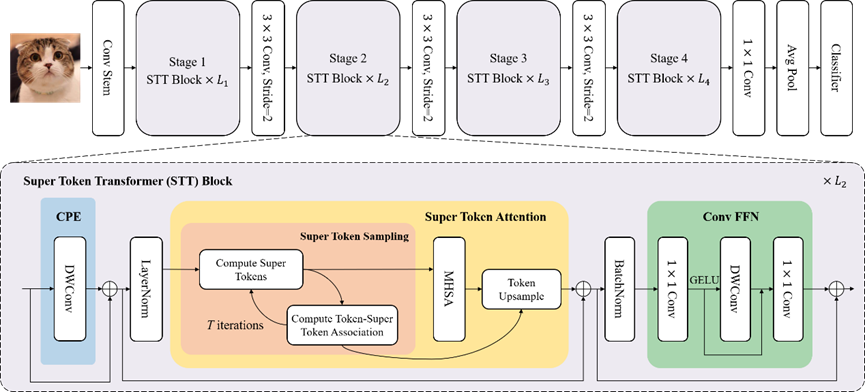
SViT网络结构 全文链接: https://arxiv.org/abs/2211.11167 代码: https://github.com/hhb072/SViT
**15. **增广策略下图分布外泛化的标签偏移问题
Mind the Label-shift for Augmentation-based Graph Out-of-distribution Generalization 作者:余俊驰,梁坚,赫然 提升分布外泛化能力是图学习领域的一个重要问题。最近的工作使用基于图结构编辑的数据增广策略并学习具有分布外泛化能力的图神经网络。然而,由于图结构编辑不可避免地会导致增广数据的标签偏移,引入了不利于泛化的标签噪声。为了解决这个问题,我们提出了基于标签不变(Label-invariant)子图(Subgraph)增强(Augmentation)的图数据增广策略LiSA。具体地,LiSA首先设计了变分子图生成器来提取局部预测模式并构建多个标签不变子图。然后,同标签下不同的子图被划分为不同的增广训练环境。为了进一步提升增广环境的多样性,LiSA进一步引入了一种基于能量的分布多样性正则化。对节点级和图级OOD分布外泛化基准数据集的大量实验表明,LiSA能够大幅提升提升多种GNN骨架的泛化性能。
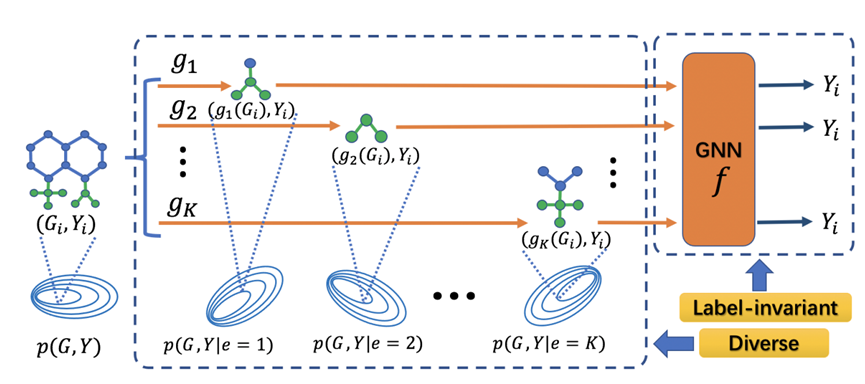
LiSA模型示意图 相关链接: https://github.com/Samyu0304/LiSA
**16. **探索分布之外的样本以检测分类错误
OpenMix: Exploring Out-of-Distribution samples for Misclassification Detection 作者:朱飞,程真,张煦尧,刘成林 在高风险的应用环境中,机器学习系统需要预测的结果具有可靠的置信度,以提升模型的安全性。然而,基于深度神经网络的模型往往对其错误预测过度自信。受到认知科学里的心智模式的启发,本文研究了来自未知类别的无标记数据是否可以用于提高模型在已知类别上的准确率和置信度估计性能。我们提出了一种新的错分样本检测方法,该方法包含拒识类别增广和分布外样本变换两个部分,可以有效地帮助模型整合开放环境下的不确定性知识。相关实验结果表明,该方法能够帮助模型检测和过滤错误分类的样本,在多种情况下提升模型的安全性和可靠性。
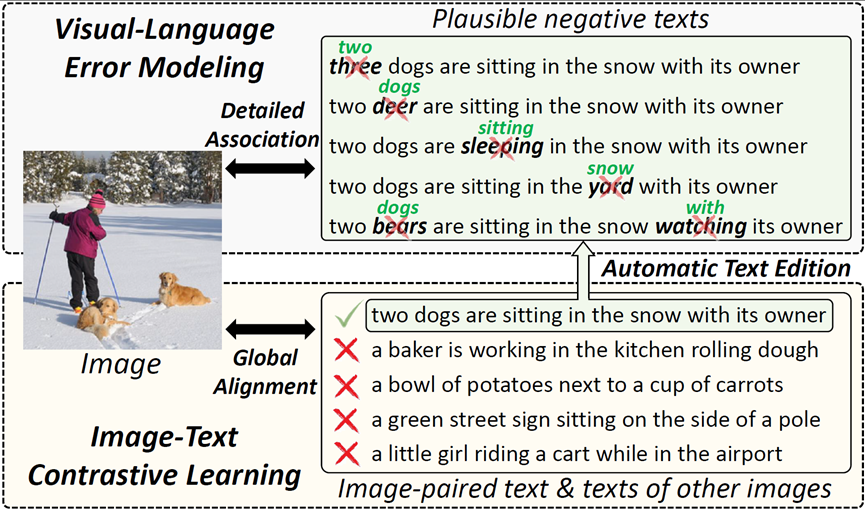
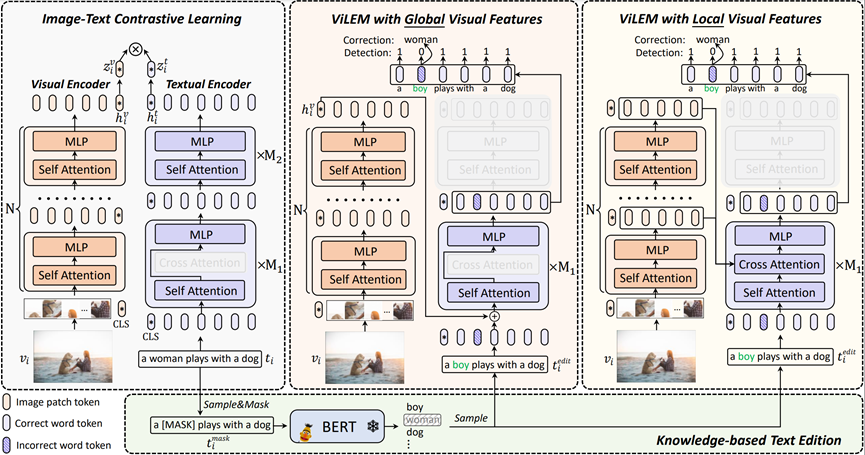
**17. **用于图文检索的视觉语言错误建模
ViLEM: Visual-Language Error Modeling for Image-Text Retrieval 作者:陈禹昕,马宗扬,张子琦,祁仲昂,原春锋,单瀛,李兵,胡卫明,郄小虎,吴建平 主流的用于图文检索的预训练模型采用“双编码器”架构以实现高效率,其中使用两个编码器来提取图像和文本表示,并采用对比学习进行全局对齐,但粗粒度的全局对齐忽略了图像和文本之间细粒度的语义关联。本工作提出一种新颖的代理任务,称为视觉语言错误建模(ViLEM),通过参考图像信息,对文本中的每个单词进行“校对”,将细粒度图像文本关联注入“双编码器”模型中。此外,我们提出一种多粒度交互框架,通过文本特征与全局和局部图像特征之间的交互,关联局部文本语义与高层视觉上下文信息和多级局部视觉信息,从而执行ViLEM任务。本方法在图像文本检索任务上大幅超越最先进的“双编码器”方法,显著提高了对局部文本语义的区分性,并可以很好地推广到视频文本检索。
**18. **基于面部动作单元一致性的伪造人脸检测
AUNet: Learning Relations Between Action Units for Face Forgery Detection 作者:白炜铭,刘雨帆,张志鹏,李兵,胡卫明 在伪造人脸检测中,当训练和测试的伪造人脸样本来自同一种伪造技术时,现有伪造检测方法表现优秀。但当推广到训练期间未见过的方法创造的伪造人脸时,效果仍有待提升。本工作提出了面部单元关系学习框架,以提高伪造人脸检测的通用性。方法由面部单元关系学习网络(ART)和篡改面部单元预测任务(TAP)组成。ART通过面部单元个体分支和面部单元群体分支从不同层面构建不同面部单元之间的关系,两个分支共同为伪造人脸检测提供有效线索。在篡改面部单元预测任务中,我们在图像层面篡改与动作单元相关的区域,在特征层面合成伪造样本,然后对模型进行训练,用生成的篡改区域监督信息来预测被篡改的面部单元区域。实验结果表明,我们的方法在数据集内和跨数据集的评估中都能取得目前最佳的性能。
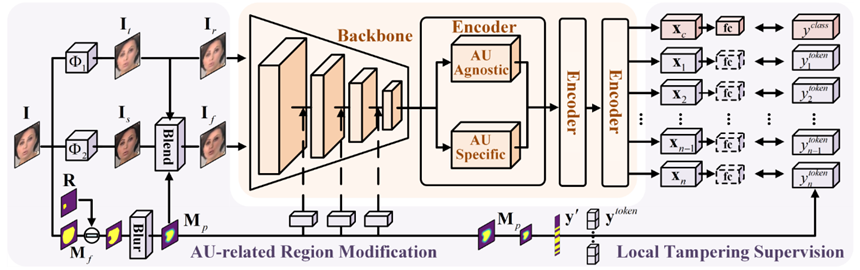
相关链接:https://github.com/wmbai/AUNet
**19. **利用序列先验知识进行图像处理流程优化
Learning to Exploit the Sequence-Specific Prior Knowledge for Image Processing Pipelines Optimization 作者:覃海纳,韩龙飞,王隽,熊伟华,马文涛,李兵,胡卫明 图像信号处理器(ISP)是成像传感器和下游应用之间的中间层,将传感器信号处理成RGB图像。ISP的可编程性较差,由一系列的处理模块组成。每个处理模块处理一个子任务,包含一组可调整的超参数。大量的超参数与ISP的RGB输出形成了复杂的映射关系。工业界通常依靠图像专家的手动和耗时的超参数调整,偏重于人类的感知。最近,一些使用下游评估指标的自动ISP超参数优化方法开始出现。然而现有的ISP调整方法将高维参数空间作为一个全局空间进行优化和预测,而没有引入ISP的结构知识。为此,我们提出了一个序列化的ISP超参数预测框架,利用ISP模块间的顺序关系和参数间的相似性来指导模型的序列过程。我们在目标检测、图像分割和图像质量任务上验证了提出的方法。
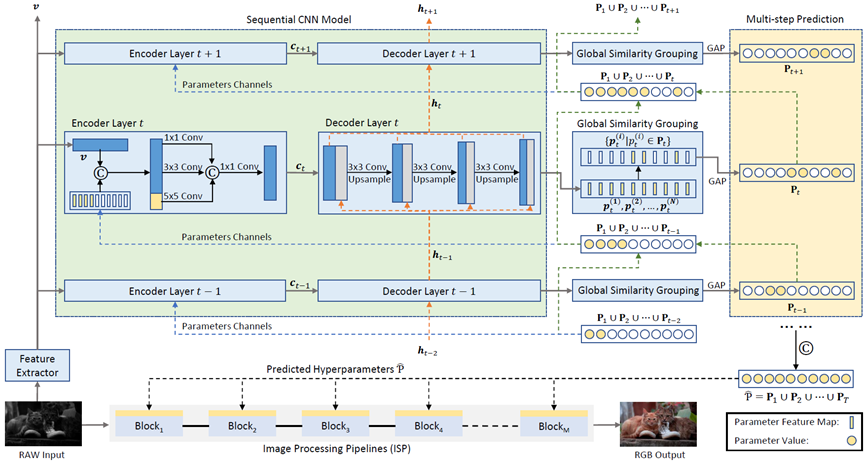
ISP超参数序列预测框架和 ISP 调优过程
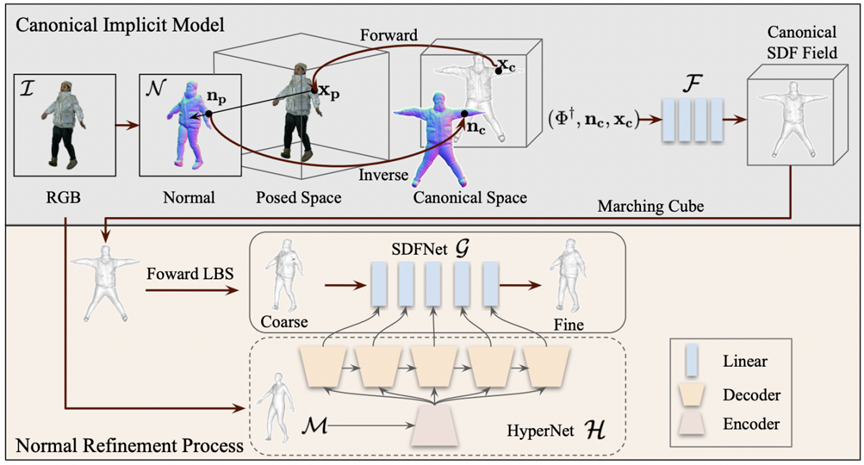
**20. **单张图像高保真三维穿衣人体重建
High-Fidelity Clothed Avatar Reconstruction from a Single Image
作者:廖婷婷,张小梅,修宇亮,易鸿伟, 刘旭东,齐国君,张勇,王璇, 朱翔昱,雷震 本文提出了一种由粗到精两阶段的三维人体穿衣重建方法。在第一阶段中,本文采用一个有向距离函数(Signed Distance Function SDF)隐式表式标准姿态空间中人体的形态。在标准三维空间中,我们通过每个点的图像特征、标准空间法相和点坐标来估计一个有向距离场,然后通过Marching Cube方法得到粗糙三维人体。第二阶段中,本文仍然采用隐式表示方法对人体表面细节进行精细优化,相比传统显示表示方法利用顶点偏移量对人体进行形变,本文方法更加灵活且可以避免几何塌陷和不规则形变。此外,本文提出一个超参网络以加快精细优化阶段收敛速度,我们采用元学习方法将人体先验映射为一组参数,从而将精细重建网络初始化为一个大致的三维人体,相比于随机初始化,超参网络可以很大程度上加快优化速度。
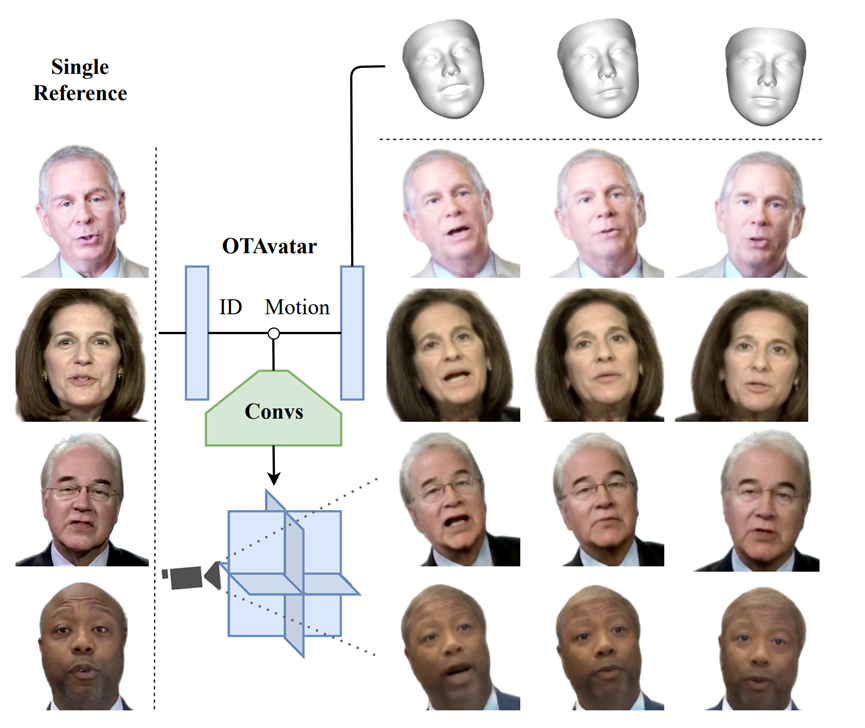
**21. **基于可控三平面渲染的单样本说话人像合成
OTAvatar: One-shot Talking Face Avatar with Controllable Tri-plane Rendering
作者:马致远,朱翔昱,齐国君,雷震,张磊 单样本说话人像合成是指根据单一人像图片提取身份特征并能够驱动人像得到较为流畅的说话视频。目前的人像驱动方法大都基于二维卷积和图像密集形变来实现人像表情和姿态的变化,在渲染时存在不自然的图像扭曲,不能保证渲染效果的多视角一致性。体渲染作为一种可微的三维渲染技术,广泛应用于视角一致的物体、场景、人体等渲染领域,但基于此的方法大多无法兼顾身份泛化性和可驱动性,少数兼顾渲染多身份人像和可驱动的方法也效果不佳。本文提出单样本三维说话人像合成方法,名为OTAvatar。它通过一种身份泛化的可控三平面渲染方案构建人像的三维表征,每个身份的三维表征只需要一张肖像图片作为参考来构建。核心创新点为一种新颖的解耦重演策略,它通过基于优化的图像反演来解藕潜向量中的身份和运动信息。我们在 A100 上以 35 FPS 的速度实现了身份泛化的人像的可控渲染,并且保证了三维一致性。
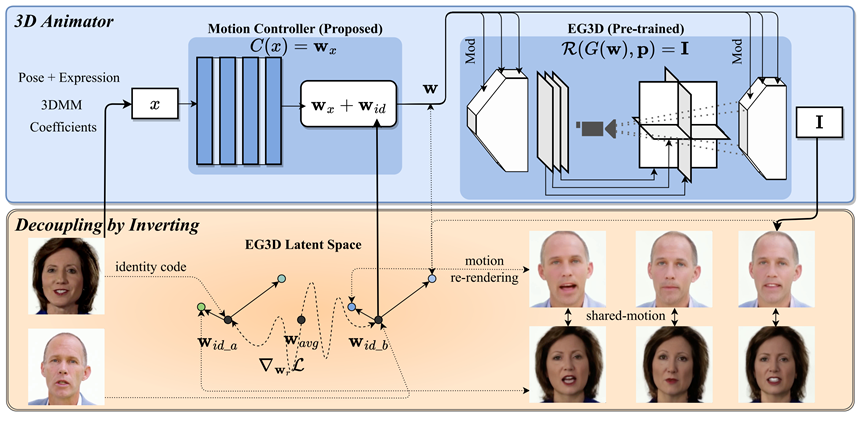
**22. **图形胶囊:从2D图像中学习层次化3D人脸表征
Graphics Capsule: Learning Hierarchical 3D Face Representations from 2D Images
作者:于畅,朱翔昱,张小梅,张兆翔,雷震 本研究提出一种新的逆图形胶囊网络,旨在从大量的无监督人脸图像中自适应构建人脸的三维结构化表征,探索神经网络对于人脸的理解方式,提升下游的分析决策任务的可解释性。在图形胶囊神经网络中,物体被表述为结构化的图形胶囊,其中每个图形胶囊包含了对当前实体的三维描述,低层次的胶囊通过融合得到高层次的胶囊,以实现物体的结构化描述。在图形胶囊中每个参数可以通过对应的胶囊解码器获得其显示化表达,利用深度信息在标准视角下对部件进行融合,可以得到物体级别的描述,再利用姿态参数变换到对应的图像视角下,通过渲染即可得到重建后的图像,由此实现图形胶囊的无监督学习。通过网络结构中的胶囊解析模块以及相应的语义一致性损失,结合重建及稀疏约束等,图形胶囊神经网络可以有效自主构建人脸的结构化表征,展示了神经网络对人脸结构的理解方式。
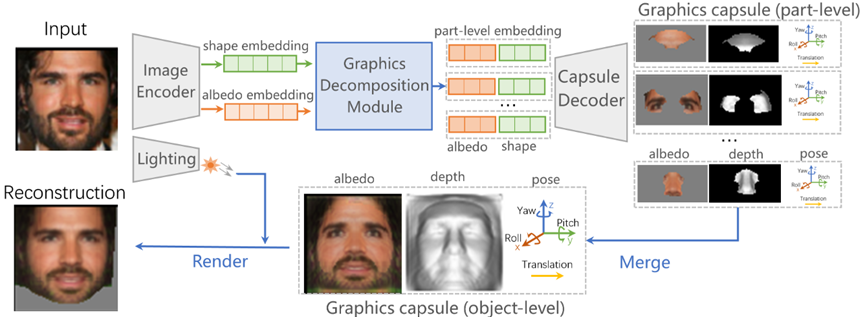
**23. **分离视频目标、背景和运动信息的视频预测方法
MOSO: Decomposing MOtion, Scene and Object for Video Prediction
作者:孙铭真,王卫宁,朱欣鑫,刘静 视频是一种记录目标运动信息的媒介,其包含三种视觉成分:主体目标,视频背景和运动变化。因此,本文提出分离视频的三种视觉成分的两阶段视频预测方法。在第一阶段,MOSO-VQVAE分解视频的三种视觉成分,并分别用离散码字表示各个视觉成分的信息。在第二阶段,MOSO-Transformer基于离散码字建模视频预测任务。在测试时,MOSO-Transformer先基于已知视频片段的离散码字预测未来视频片段的主题目标和视频背景的离散码字,再生成与主体目标和视频背景对应的运动信息。本方法可以直接拓展至视频生成和视频插帧任务,其在视频预测和视频生成领域中的五个基准任务上均取得了当前最佳性能。

相关链接:https://arxiv.org/abs/2303.03684
**24. **基于视觉大模型的零样本开放场景前景检测方法
ZBS: Zero-shot Background Subtraction via Instance-level Background Modeling and Foreground Selection
作者:安永琪,赵旭,于涛,郭海云,赵朝阳,唐明,王金桥 视频前景目标检测旨在提取视频帧中的所有移动物体。传统方法往往难以处理复杂场景。近年来基于深度学习的监督学习方法和无监督学习方法都只能检测到少量预先设定的前景类别之内的物体。基于视觉预训练大模型的世界知识建模能力和场景目标的强辨别能力,该论文提出了一种基于实例级背景模型的前景提取方法。基于由视觉预训练大模型转化得到的零样本开放类别实例分割器,该方法将视频帧结构化为包含超大规模物体类别的精确实例级表达,通过分析目标运动信息构建实例级背景模型,通过比较视频帧和背景模型有效辨别前景。该方法在复杂场景下有效克服了背景噪声、弱光照场景物体漏检等问题,并能有效处理前景物体所属类别众多的难点。实验表明,该方法准确率相较于最先进的同类方法提升了4.7%。
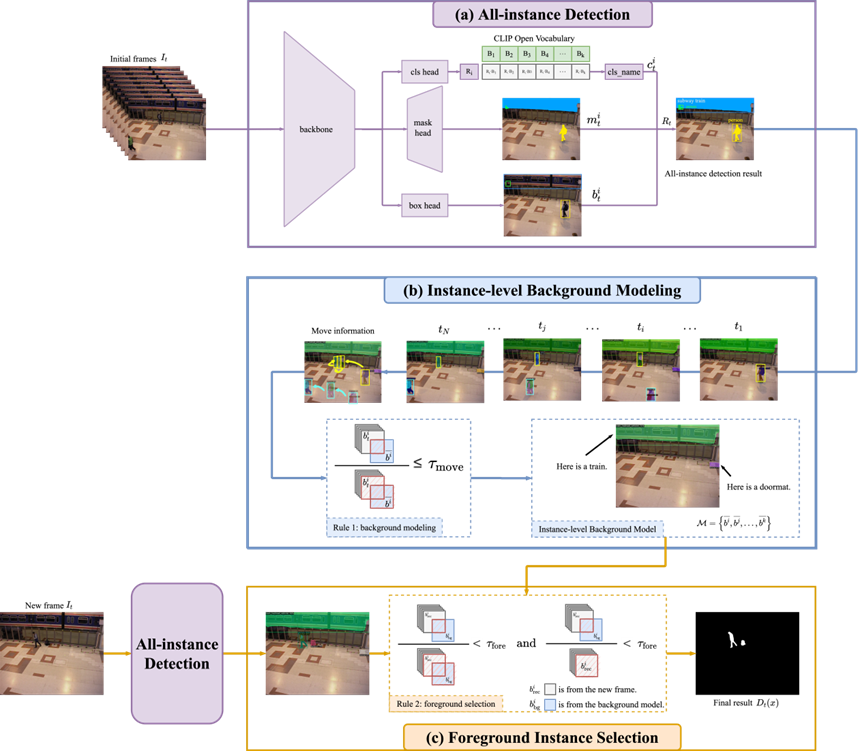
ZBS算法框架图
**25. **面向开放世界弱监督时序动作定位的级联证据学习
Cascade Evidential Learning for Open-world Weakly-supervised Temporal Action Localization 作者:陈孟沅,高君宇,徐常胜 弱监督时序动作定位在识别和定位仅具有视频级标签的动作片段方面取得了显著进展。然而在动态变化的开放世界中,前所未见的未知行为不断涌现,使得现有时序动作定位方法的闭集假设失效。与传统的开放集识别任务相比,开放世界时序动作定位不仅无法获得未知样本的标注,而且已知动作实例的细粒度标注也只能从视频类别标签中模糊地推导出来,使其更具有挑战性。为了解决上述问题,本文首次以开放世界时序动作定位为目标,在证据层面上提出了级联证据学习框架,联合利用多尺度时间上下文和知识引导的原型信息,逐步收集已知动作、未知动作和背景分离的级联增强证据。我们在THUMOS-14和ActivityNet-v1.3上进行的大量实验充分验证了所提方法的有效性。此外,除了以往开放集识别方法所采用的各种分类指标,我们还采用定位指标对开放世界时序动作定位结果进行了评估。
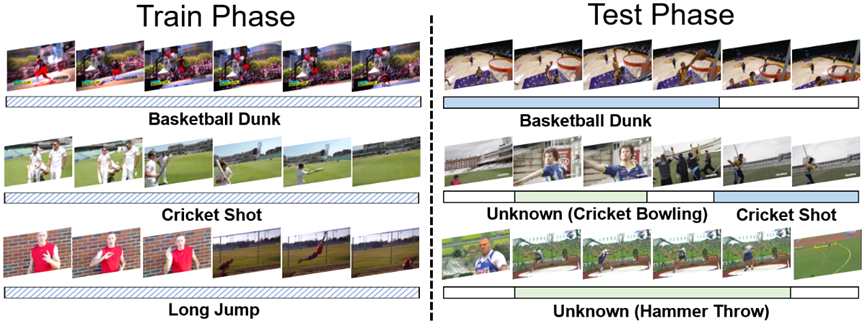
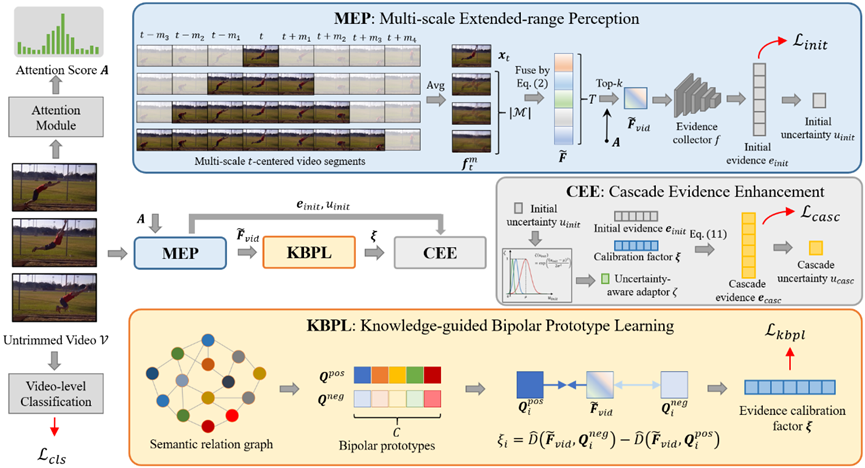
**26. **面向弱监督视听事件感知的跨模态存缺证据收集
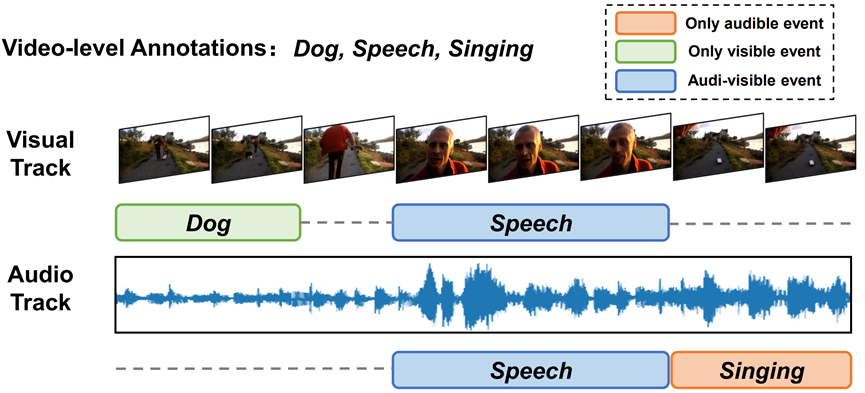
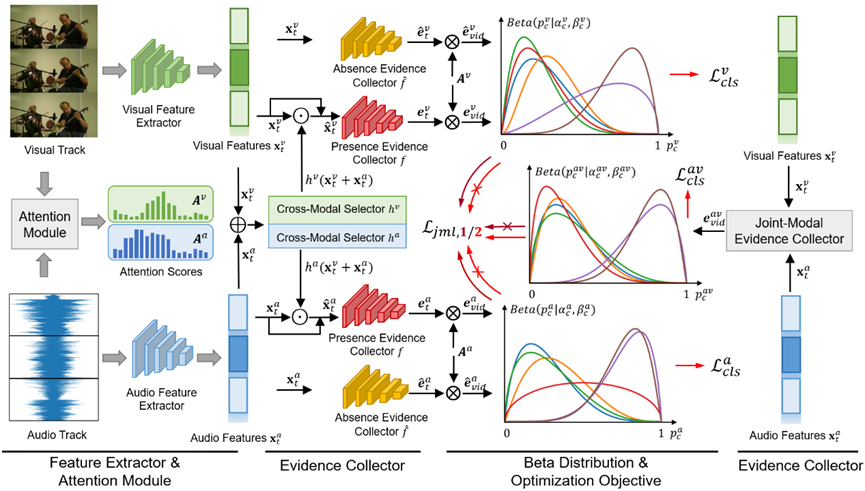
Collecting Cross-Modal Presence-Absence Evidence for Weakly-Supervised Audio-Visual Event Perception 作者:高君宇,陈孟沅,徐常胜 本文在仅使用视频级事件标签的情况下,探索了弱监督视听事件感知任务,即对属于各种音-视频模态的事件进行时间上的定位和分类。尽管近期相关研究已取得了一些进展,但大多数现有方法都忽略了视听轨迹的不同步特性,或忽略了利用模态间的互补性质来进行显式增强。本文认为对于驻留在单一模态中的事件,模态本身应提供该事件的充分存在证据,并鼓励另一种互补模态提供该事件的缺失证据作为参考信号。因此,我们建议在统一的框架中收集跨模态存在/缺失证据,具体地说,我们通过利用单模态和跨模态表示,在主观逻辑理论的指导下设计了存在/缺失证据收集器。为了将学习得到的证据控制在可靠范围内,本文还提出了一种联合模态互学习方案,自适应地动态校准不同的可听、可见和可视听事件的证据。实验证明了该方法的有效性,本文所提出方法取得了SOTA性能。
**27. **基于知识引导上下文优化的提示学习方法
Visual-Language Prompt Tuning with Knowledge-guided Context Optimization 作者:姚涵涛,张蕊,徐常胜 提示学习是利用与任务相关的文本模板来使预训练视觉语言模型适应下游任务的有效方法。基于CoOp的工作是利用提供的标记数据学习与任务密切相关的特定文本模板。然而,由于学习的特定文本模板忘记了具有较强泛化能力的通用知识,它对不可见类的泛化能力较差。并且我们发现未知域上性能的下降程度与其对应的文本语义空间的距离正相关(图1)。基于此,我们设计了一种新的基于知识引导上下文优化 (KgCoOp)的提示学习算法来增强模型对不可见类的泛化能力(图2)。KgCoOp的关键是通过减少可学习的模板和手工设计模板之间的差异减轻对通用知识的遗忘。具体而言,在标准的对比约束之上,KgCoOp约束了生成的文本语义空间与手工模板生成的文本语义空间之间的差异尽量小。评估表明,本方法是一种有效的提示学习方法,可以用更少的训练时间到达更好的性能。
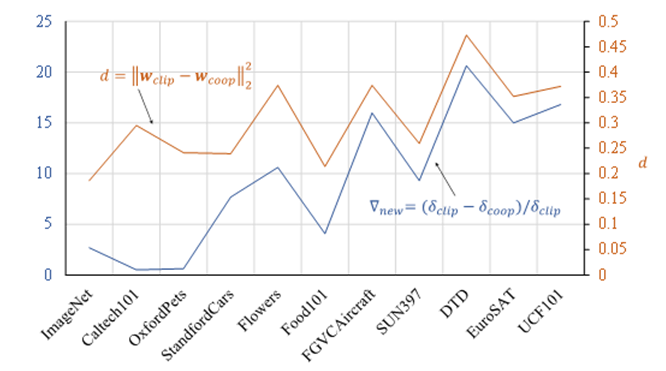
图1. 未知域上性能下降程度与其对应的文本空间的距离正相关
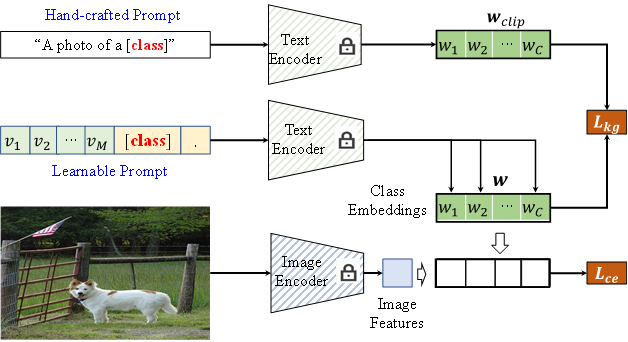
图2. 基于知识引导上下文优化的提示学习方法
**28. **VQACL:一种新颖的视觉问答连续学习设定
VQACL: A Novel Visual Question Answering Continual Learning Setting
作者:张熙,张飞飞,徐常胜 针对连续学习,研究者们近年在单模态任务中开展了大量工作,但对视觉问答(VQA)等多模态任务的关注较少。本文建立了一个如图1所示的新颖的VQA连续学习设置VQACL,其中包含两个关键组件:视觉和语言数据嵌套的双层任务序列,以及包含新技能(skill)-概念(concept)组合的泛化性测试。前者致力于模拟现实世界中不断变化的多模态数据流,后者旨在衡量模型在认知推理中的泛化能力。基于VQACL,我们对五种经典的连续学习方法进行了深入评估,发现它们存在灾难性遗忘问题且泛化能力较弱。为此,本文提出了如图2所示的一种新的表示学习方法,利用样本特定和样本不变的特征来学习既具有判别力又可泛化的表示。同时,通过分别为视觉和文本输入提取这种表示,所提出的方法可以显式地解耦技能和概念。大量的实验结果表明所提方法明显优于现有模型,证明了所提方法的有效性和组合泛化性。
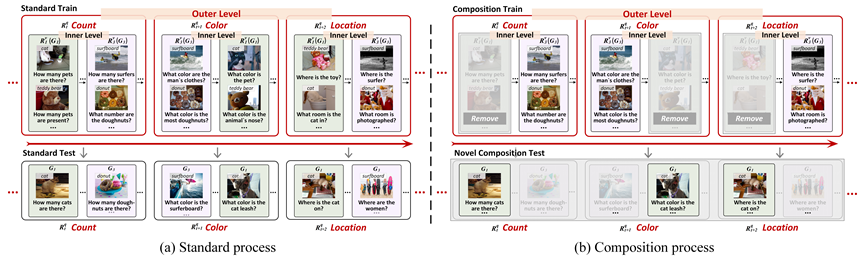
图1
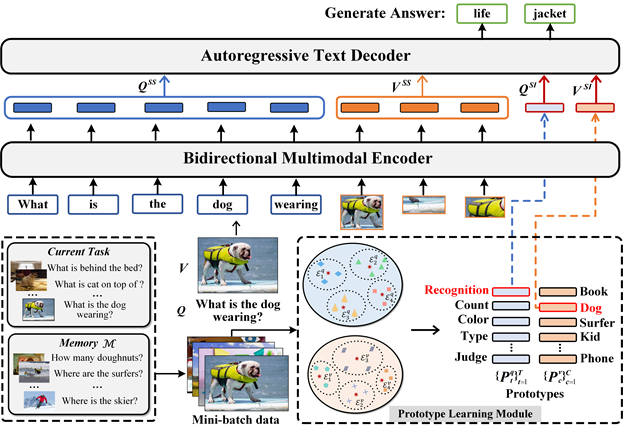
图2
**29. **基于反演方法和扩散模型的图像风格迁移
Inversion-Based Style Transfer with Diffusion Models 作者:张宇欣,黄妮莎,唐帆,黄海斌,马重阳,董未名,徐常胜 绘画的艺术风格是一种表达方式,不仅包括绘画材料、色彩、笔触,还包括语义元素、物体形状等高层次属性。传统任意实例引导的艺术图像生成方法通常无法控制形状变化或传达语义元素。预训练的文本到图像生成扩散概率模型已取得了卓越的视觉效果,但通常需要大量的文本描述才能准确描绘特定绘画的属性。我们认为一件艺术品的独特性恰恰在于它无法用语言文字来准确描述。本工作关键思想是直接从一幅画中学习艺术风格,然后在不提供复杂的文本描述的情况下指导合成,即我们假设风格是一幅画的可学习的文本描述。我们提出了一种基于注意力的反演方法,可以高效准确地学习图像的整体和细节信息,从而捕捉一幅画的完整艺术风格。本方法在各种艺术家和风格的众多画作上展示了质量和效率。实验证明其在生成图片的风格准确性、可编辑性和模型收敛速度上都达到了目前最先进的水平。

图1. 风格迁移结果

图2 文字控制的艺术图像生成对比结果 代码:https://github.com/zyxElsa/creativity-transfer
**30. **基于主动式多模态互补特征学习的小样本动作识别
Active Exploration of Multimodal Complementarity for Few-Shot Action Recognition 作者:完颜宇洋、杨小汕、陈超凡、徐常胜 近期,小样本动作识别研究受到越来越多的关注并取得了显著进展。然而,现有方法主要依赖于有限的单模态数据(例如 RGB 帧),而多模态信息仍然未得到充分研究。本文提出了一种新颖的主动多模态小样本动作识别(AMFAR)框架,根据任务相关的上下文信息主动为每个样本找到可靠的模态,以改进小样本推理过程。在元训练阶段,我们设计了一个主动样本选择(ASS)模块,根据模态特定的后验分布将模态可靠性差异较大的查询样本划分到不同的集合中。此外,我们设计了一个主动互蒸馏模块(AMD)来从可靠模态中提取有区分度的任务特定知识,通过双向知识蒸馏改进不可靠模态的表示学习。在元测试阶段,我们采用自适应多模态推理(AMI)赋予可靠模态较大权重,自适应地融合模态特定的后验分布。实验结果表明我们的模型与现有的单模态和多模态方法相比取得了显著的性能改进。
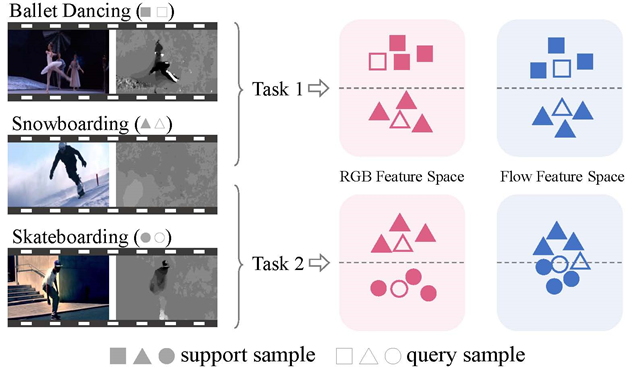
Figure 1: Illustration of multimodal few-shot action recognition task. The main challenge is that the contribution of a specific modality highly depends on task-specific contextual information.
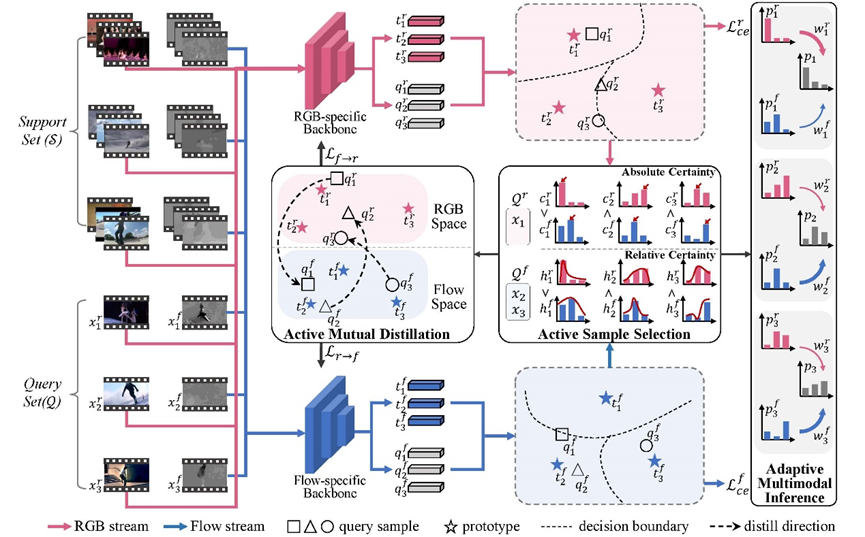
Figure 2:Illustration of the proposed AMFAR framework in the 3-way 3-shot setting Illustration of the proposed AMFAR framework in the 3-way 3-shot setting. Firstly, query representations and prototypes are obtained from modality-specific backbone networks for both RGB and optical flow. Secondly, Active Sample Selection (ASS) is adopted to organize query samples with large differences in the reliability of two modalities into RGB-dominant group and Flow-dominant group. Thirdly, Active Mutual Distillation (AMD) is adopted to capture discriminative task-specific knowledge from the reliable modality to improve the representation learning of the unreliable modality. Finally, Adaptive Multimodal Inference (AMI) is adopted to combine the predictions of different modalities by paying more attention to the reliable modality. Best viewed in color.
**31. **通用视频肖像编辑中的姿态和表达解耦
DPE: Disentanglement of Pose and Expression for General Video Portrait Editing
作者:庞有鑫、张勇、全卫泽、樊艳波、寸晓东、Ying Shan、严冬明 说话人脸视频驱动的目标为将一个视频中人脸的属性迁移到任意另一个人脸肖像视频中。目前多数方法均为one-shot形式,即将面部表达和头部姿态两个属性同时进行迁移。该驱动方式导致只能针对单张肖像图像进行驱动,而无法进行视频编辑。因为视频编辑要求能够对面部表达和头部姿态进行解耦,而多数已有方法不具备该功能。数据集的缺少是学习解耦的较大障碍之一,因此目前能够实现解耦功能的方法均利用了3DMM本身对两个属性显式解耦的特性。但由于blendshapes数量的限制,3DMM对于面部细节的表示仍然不是特别准确。针对上述问题,本工作提出了一个自监督的解耦框架,利用双向循环的方式,在不借助3DMM和成对数据的情况下实现了面部表达和头部姿态的解耦,并且经过实验证明在面部细节上优于基于3DMM的SOTA方法。

相关链接:https://carlyx.github.io/DPE/
**32. **基于草图-拉伸命令学习的自监督三维逆向建模
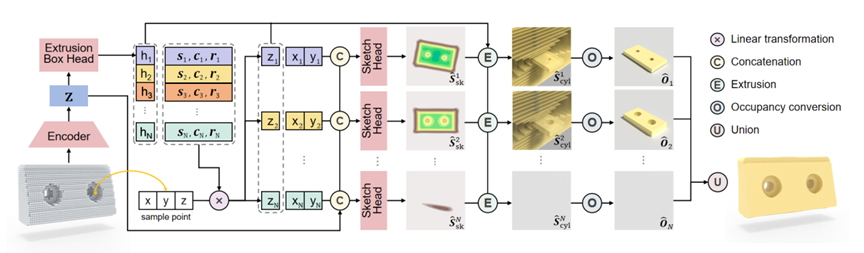
SECAD-Net: Self-Supervised CAD Reconstruction by Learning Sketch-Extrude Operations 作者:李朴;郭建伟;张晓鹏;严冬明 从原始几何数据进行逆向三维模型的重建是构建数字孪生虚拟环境的重要手段,也是一个经典但困难的研究问题。本文提出了一种端到端的神经网络,SECAD-Net,旨在以自监督的方式重建紧凑且易于编辑的CAD三维模型。我们从现代 CAD 软件常用的建模语言中汲取灵感,从整体三维形状中学习CAD基元的隐式二维草图(sketch)和拉伸(Extrude)参数,通过将每个草图从二维平面拉伸为三维空间以得到一系列三维柱体。最后通过使用布尔运算(并操作)将这些圆柱体组合并接近目标几何形状。相比以往方法,SECAD-Net采用二维隐式场表示草图,对草图形状表达能力更强,因此重建效果更好且更简洁,并易于编辑。我们在 ABC 和 Fusion 360 数据集上进行大量对比实验,证明了本文方法的优越性能。
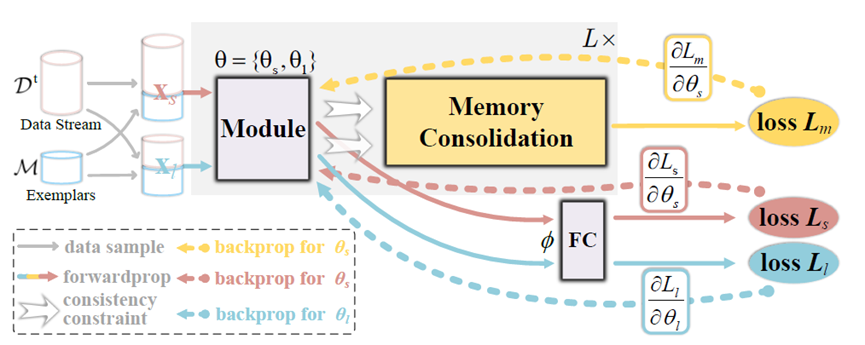
**33. **双侧记忆巩固的连续学习方法
Bilateral Memory Consolidation for Continual Learning
作者:聂兴,许世雄,刘希岩,孟高峰,霍春雷,向世明 人类擅长不断获取和整合新知识,相比之下,深度模型会灾难性地遗忘,尤其是在处理非常长的任务序列时。受人类大脑不断重写和巩固过去记忆的方式的启发,本文提出了一种新的双边记忆巩固(BiMeCo)框架,专注于增强模型的记忆交互能力。BiMeCo显式地将模型参数解耦为短期记忆模块和长期记忆模块,分别负责模型的表征能力和对已学习过的任务的泛化能力。BiMeCo通过知识蒸馏和基于动量的更新,鼓励两个记忆模块之间的动态交互,从而形成通用知识来防止遗忘。值得注意的是,所提出的BiMeCo是参数高效的,可以无缝集成到现有的连续学习算法中。在具有挑战性的数据集上进行的大量实验表明,BiMeCo显著提高了现有连续学习算法的性能。