近期必读的5篇顶会CVPR 2021【视频理解】相关论文和代码
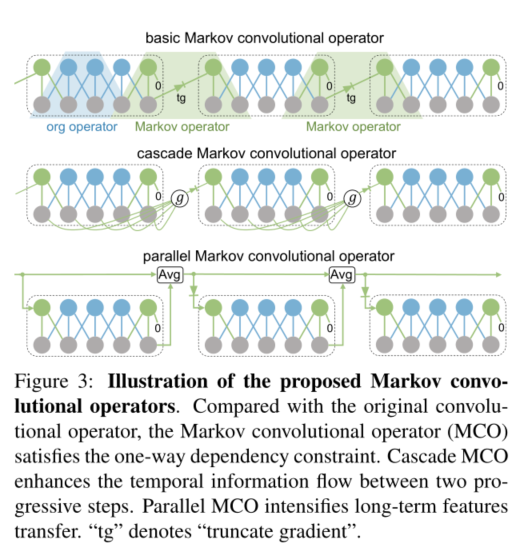
1. PGT: A Progressive Method for Training Models on Long Videos
作者:Bo Pang, Gao Peng, Yizhuo Li, Cewu Lu
摘要:卷积视频模型的计算复杂度比其对应的图像级模型大一个数量级。受计算资源的约束,没有模型或训练方法可以端到端训练长视频序列。目前,主流方法是将原始视频分割成片段,导致片段时间信息流不完整,受自然语言处理长句的启发,我们建议将视频视为满足马尔可夫性质的连续片段,并将其训练为通过逐步扩展信息在时间维度上的整体传播。这种渐进式训练(PGT)方法能够以有限的资源端对端地训练长视频,并确保信息的有效传输。作为一种通用且强大的训练方法,我们通过经验证明了该方法在不同模型和数据集上均具有显着的性能改进。作为说明性示例,我们提出的方法将Chalow上的SlowOnly网络提高了3.7 mAP,在Kinetics 方面提高了1.9 top-1的精度,而参数和计算开销却可以忽略不计。
代码:
https://github.com/BoPang1996/PGT
网址:
https://arxiv.org/abs/2103.11313
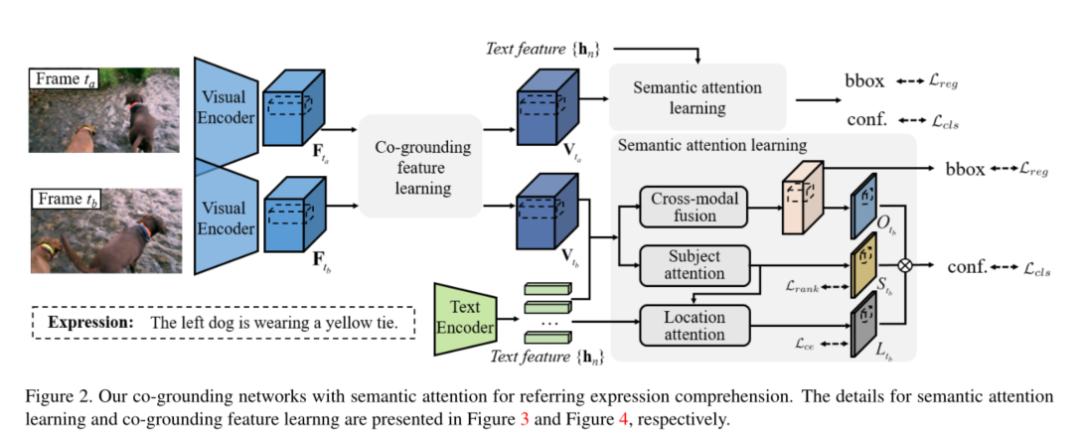
2. Co-Grounding Networks with Semantic Attention for Referring Expression Comprehension in Videos
作者:Sijie Song, Xudong Lin, Jiaying Liu, Zongming Guo, Shih-Fu Chang
摘要:在本文中,我们解决了在视频中引用了指称表达(Referring Expression)的问题,这个任务由于复杂的表达和场景动态而具有挑战性。与以前的解决方案可以在多个阶段(即跟踪,基于proposal的匹配)解决问题的方法不同,我们从新颖的角度出发使用单阶段框架—co-grounding。我们通过语义注意力学习来提高单帧 grounding 的准确性,并通过联合co-grounding特征学习来提高跨帧 grounding的一致性。语义注意力学习显式地解析具有不同属性的线索,以减少复杂表达中的歧义。co-groundin特征学习通过集成时间相关性来减少由场景动态引起的模糊性,从而增强了视觉特征表示。实验结果证明了我们的框架在video grounding数据集VID和LiOTB上的优越性,可以跨帧生成准确而稳定的结果。我们的模型还适用于引用图像中的指称表达(Referring Expression),这可以通过RefCOCO数据集上的改进性能来说明。
代码:
https://sijiesong.github.io/co-grounding
网址:
https://arxiv.org/abs/2103.12346
3. VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples
作者:Tian Pan, Yibing Song, Tianyu Yang, Wenhao Jiang, Wei Liu
摘要:MOCO对于无监督的图像表示学习是有效的。在本文中,我们针对无监督视频表示学习提出VideomoCo。给出视频序列作为输入样本,我们从两个视角改善MoCo的时间特征表示。首先,我们介绍一个生成器,以便在时间上删除几个帧。然后学习鉴别器以编码类似的特征表示,无论帧移除如何。通过在训练攻击期间自适应地丢弃不同的帧,我们将该输入样本增强以训练一个时间鲁棒的编码器。其次,在计算对比损耗时,我们使用时间衰减来模拟内存队列中的键(key)衰减。动量编码器在键进入后进行更新,当我们使用当前输入样本进行对比学习时,这些键的表示能力会下降。这种下降通过时间衰减反映出来,以使输入样本进入队列中的最近键。结果,我们使MoCo能够学习视频表示,而无需凭经验设计pretext任务。通过增强编码器的时间鲁棒性并为键的时间衰减建模,我们的VideoMoCo基于对比学习在时间上提高了MoCo。在包括UCF101和HMDB51在内的基准数据集上进行的实验表明,VideoMoCo是最先进的视频表示学习方法。

代码:
https://github.com/tinapanpt/VideoMoCo
网址:
https://arxiv.org/abs/2103.05905
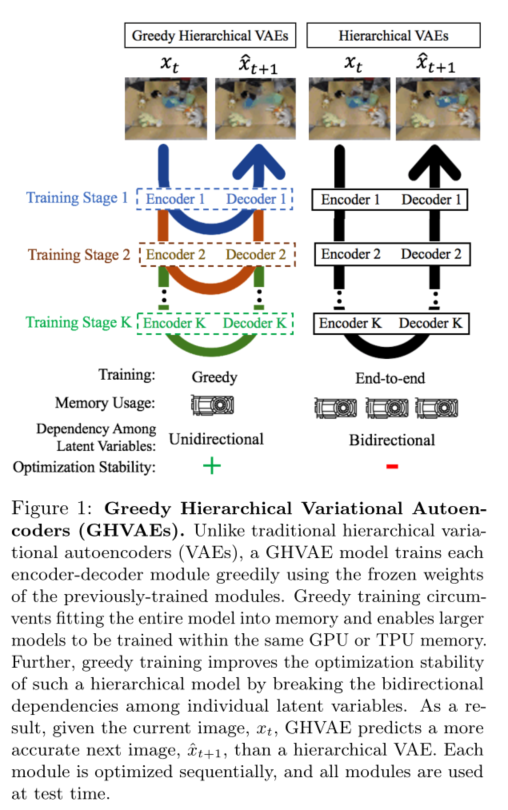
4. Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction
作者:Bohan Wu, Suraj Nair, Roberto Martin-Martin, Li Fei-Fei, Chelsea Finn
摘要:拓展到不同场景的视频预测模型将使智能体(agent)能够通过使用模型规划来执行多种任务。然而,虽然现有的视频预测模型在小型数据集上产生了有希望的结果,但在大型和多样化的数据集上训练时,它们会遭受严重的欠拟合(underfitting)。为了解决这种欠拟合挑战,我们首先观察到训练更大的视频预测模型的能力通常是通过GPU或TPU的内存限制的。同时,深层次的潜在变量模型可以通过捕获未来观测值的多级随机性来产生更高质量的预测,但是这种模型的端到端优化特别困难。我们的主要想法在于,通过对分层自编码器的贪婪和模块化优化可以同时解决内存限制和大规模视频预测的优化挑战。我们介绍贪婪的分层变分自编码器(GHVAES),这是一种通过贪婪训练分层自编码器的每个级别来学习Highfivelity视频预测的方法。GHVAE在四个视频数据集上的预测性能提高了17-55%,在实际机器人任务上的成功率提高了35-40%,并且可以通过简单地添加更多内容来提高性能模块。
代码:
https://sites.google.com/view/ghvae
网址:
https://arxiv.org/abs/2103.04174
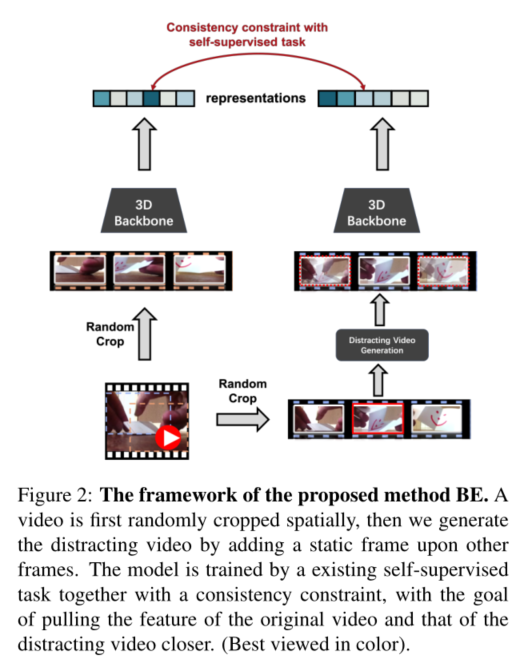
5. Removing the Background by Adding the Background: Towards Background Robust Self-supervised Video Representation Learning
作者:Jinpeng Wang, Yuting Gao, Ke Li, Yiqi Lin, Andy J. Ma, Hao Cheng, Pai Peng, Rongrong Ji, Xing Sun
摘要:通过从数据本身监督,自监督学习表现出了提高深神经网络的视频表示能力的巨大潜力。然而,一些当前的方法倾向于从背景中欺骗,即,预测高度依赖于视频背景而不是运动,使得模型容易受到背景的变化。为了减轻模型依赖背景,我们建议通过添加背景来消除背景影响。也就是说,给定视频,我们随机选择静态帧并将其添加到每个其他帧以构建分散注意力的视频样本。然后我们强制模型拉动分散的视频的特征和原始视频的特征,以便明确地限制模型以抵抗背景影响,更多地关注运动变化。我们将我们的方法命名为Background Erasing (BE)。值得注意的是,我们的方法的实现非常简单,可以很轻松地添加到大多数SOTA方法中。具体而言,在严重bias的数据集UCF101和HMDB51上具有16.4%和19.1%的改善,对较少bias的数据集Diving48改进了14.5%。
网址:
https://arxiv.org/abs/2009.05769
请关注专知公众号(点击上方蓝色专知关注)
后台回复“CVPR2021VU” 就可以获取《5篇顶会CVPR 2021视频理解(Video Understanding)相关论文》的pdf下载链接~





