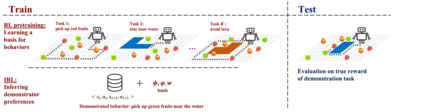
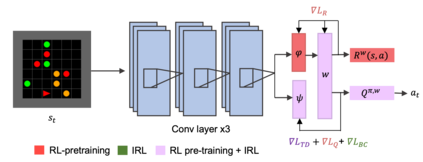
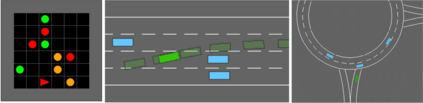
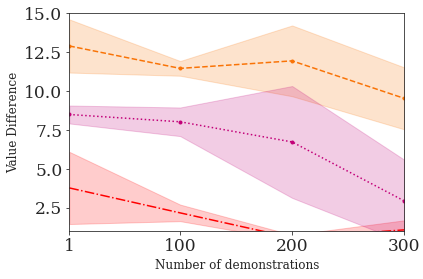
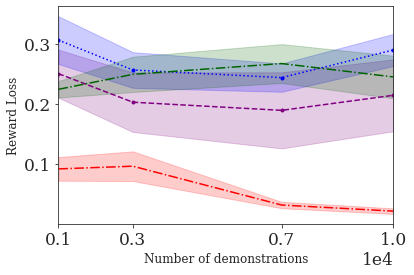
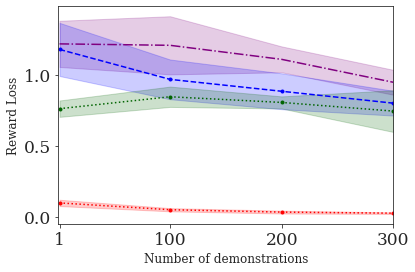
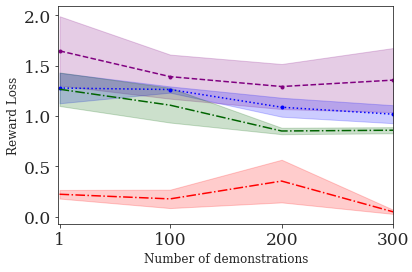
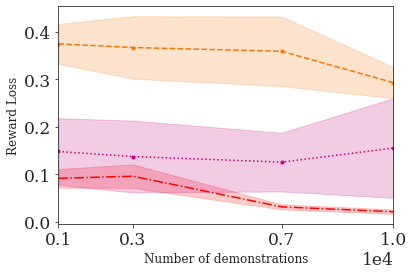
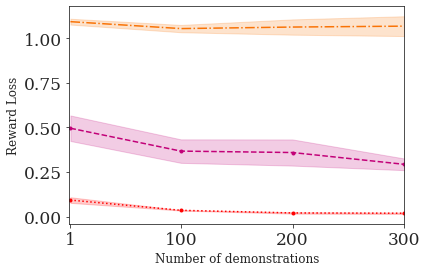
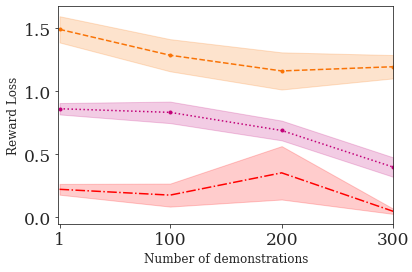
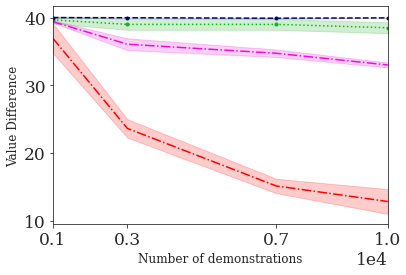
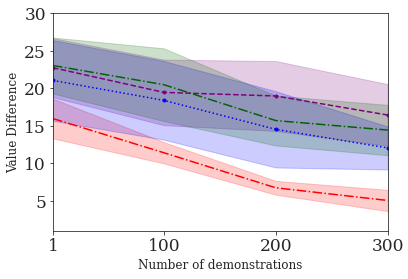
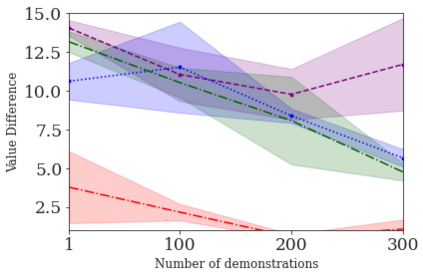
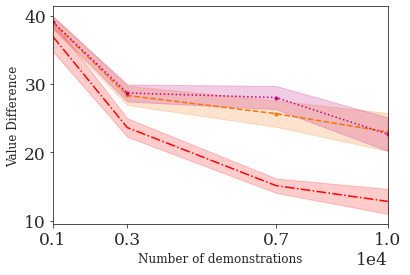
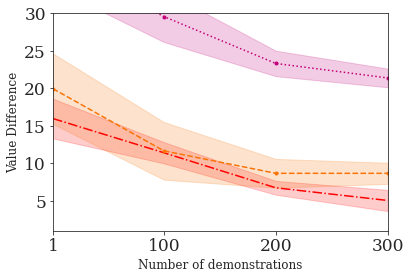
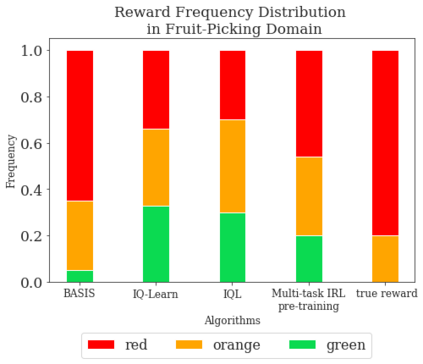
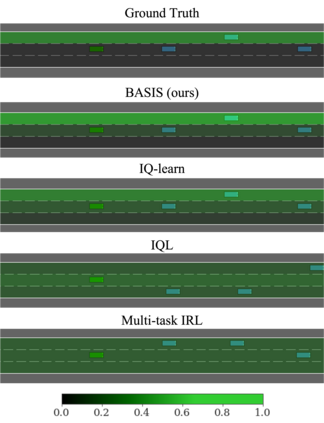
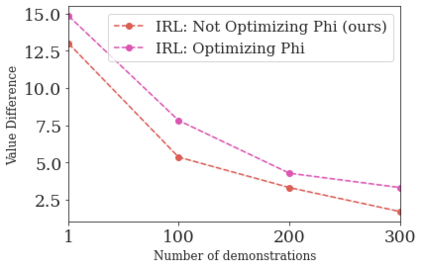
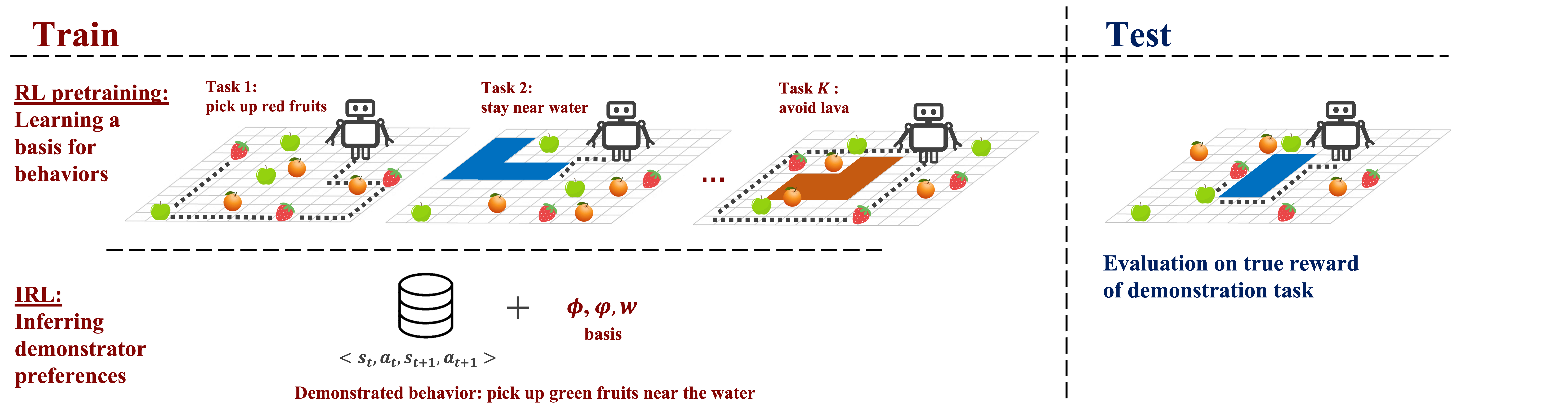
This paper addresses the problem of inverse reinforcement learning (IRL) -- inferring the reward function of an agent from observing its behavior. IRL can provide a generalizable and compact representation for apprenticeship learning, and enable accurately inferring the preferences of a human in order to assist them. %and provide for more accurate prediction. However, effective IRL is challenging, because many reward functions can be compatible with an observed behavior. We focus on how prior reinforcement learning (RL) experience can be leveraged to make learning these preferences faster and more efficient. We propose the IRL algorithm BASIS (Behavior Acquisition through Successor-feature Intention inference from Samples), which leverages multi-task RL pre-training and successor features to allow an agent to build a strong basis for intentions that spans the space of possible goals in a given domain. When exposed to just a few expert demonstrations optimizing a novel goal, the agent uses its basis to quickly and effectively infer the reward function. Our experiments reveal that our method is highly effective at inferring and optimizing demonstrated reward functions, accurately inferring reward functions from less than 100 trajectories.
翻译:本文讨论了反强化学习(IRL)问题 -- -- 推断代理人的奖赏功能是观察其行为。IRL可以为学徒学习提供一个普遍和紧凑的代表性,并能够准确地推断人类的偏好,以协助他们。% 并提供更准确的预测。然而,有效的IRL具有挑战性,因为许多奖励功能可以与观察到的行为相容。我们侧重于如何利用先前的强化学习(RL)经验,使这些偏好更快和更有效地学习。我们建议IRL的算法BASIS(通过从抽样中测算继承和性能能力获得BAISIS),利用多重任务RL的预培训和后续特征,使代理人能够建立强有力的基础,使意图跨越某一领域可能达到的目标空间。当仅仅受到少数专家演示的优化新目标时,代理人利用它的基础快速和有效地推算奖励功能。我们的实验表明,我们的方法在推断和优化已显示的奖赏功能方面非常有效,准确推导出不到100个目标的奖励功能。