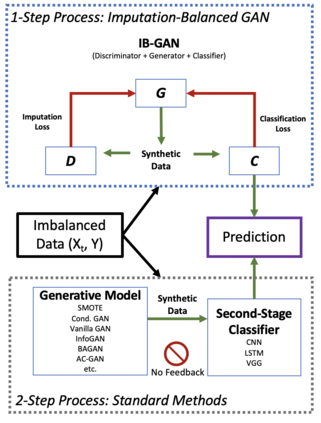
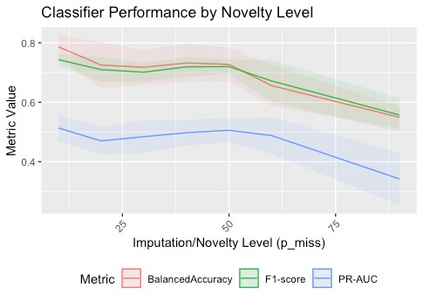
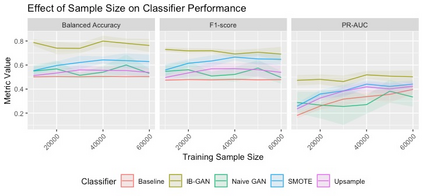
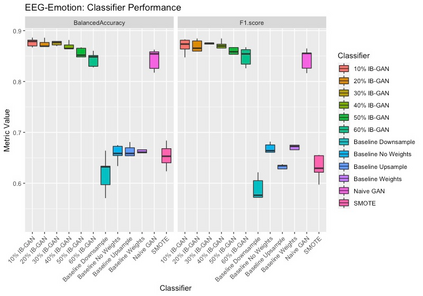
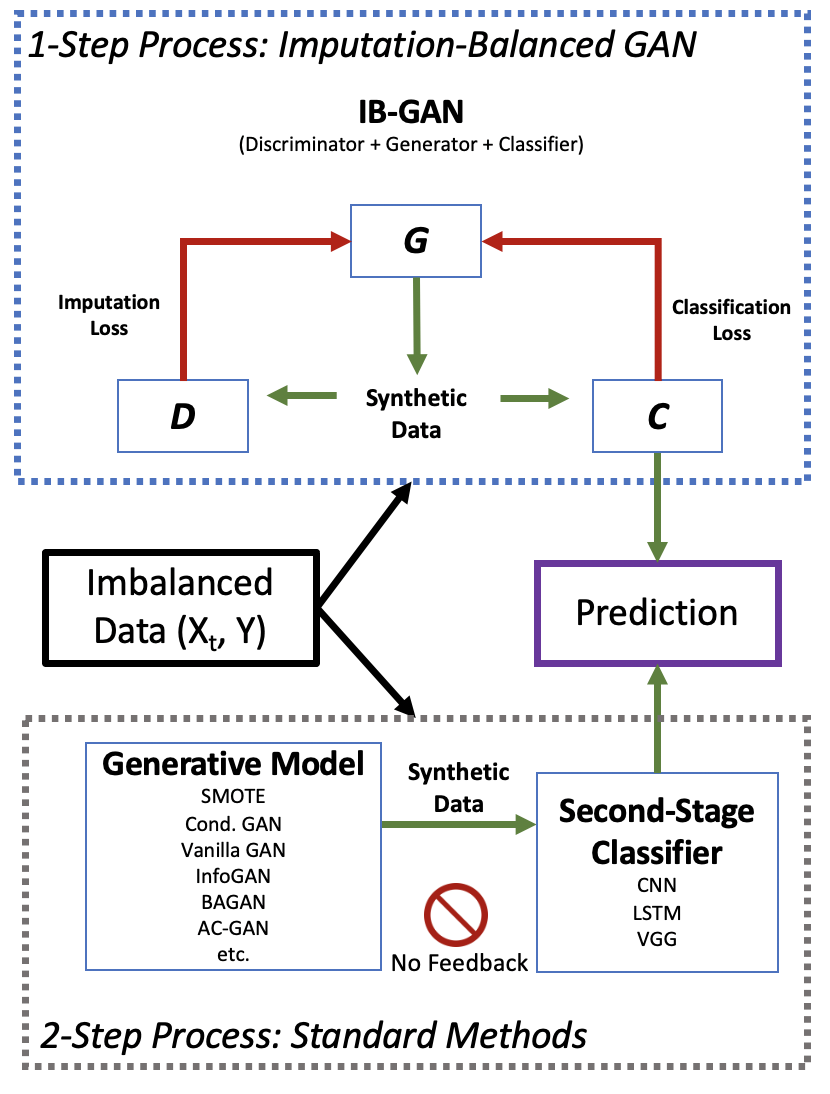
Classification of large multivariate time series with strong class imbalance is an important task in real-world applications. Standard methods of class weights, oversampling, or parametric data augmentation do not always yield significant improvements for predicting minority classes of interest. Non-parametric data augmentation with Generative Adversarial Networks (GANs) offers a promising solution. We propose Imputation Balanced GAN (IB-GAN), a novel method that joins data augmentation and classification in a one-step process via an imputation-balancing approach. IB-GAN uses imputation and resampling techniques to generate higher quality samples from randomly masked vectors than from white noise, and augments classification through a class-balanced set of real and synthetic samples. Imputation hyperparameter $p_{miss}$ allows for regularization of classifier variability by tuning innovations introduced via generator imputation. IB-GAN is simple to train and model-agnostic, pairing any deep learning classifier with a generator-discriminator duo and resulting in higher accuracy for under-observed classes. Empirical experiments on open-source UCR data and proprietary 90K product dataset show significant performance gains against state-of-the-art parametric and GAN baselines.
翻译:大型多变时间序列的分类存在严重的阶级不平衡,这是现实世界应用中的一项重要任务。标准级权重、过度抽样或参数数据增强方法并不总能显著改进对少数利益阶层的预测。与基因反versarial网络(GANs)一起的非参数数据增强提供了有希望的解决办法。我们建议了光化平衡GAN(IB-GAN)这一新方法,它通过估算平衡方法将数据扩大和分类纳入一个一步骤的过程。IB-GAN使用测算和重新采样技术,从随机遮盖的矢量中产生比白噪音高质量的样品,并通过一系列实际和合成样品来增加分类。光化超光化超参数使通过发电机光化来调整创新,使分类变异性规范化。IB-GAN简单地将任何深层次的学习分级与发电机分级相配对,使低度掩码矢量遮盖矢量矢量矢量矢量矢量矢量矢量矢量的矢量样本产生更高的精度样本,并通过一组等级平衡的实际和合成样品样品样本样本样本样本进行精确度的分级分析。EPAL-AN实验,以显示显著的硬度基准数据。