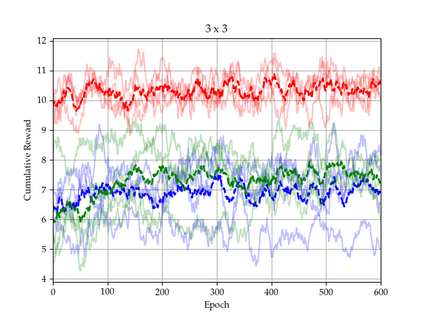
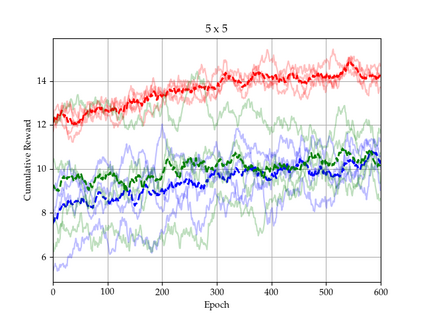
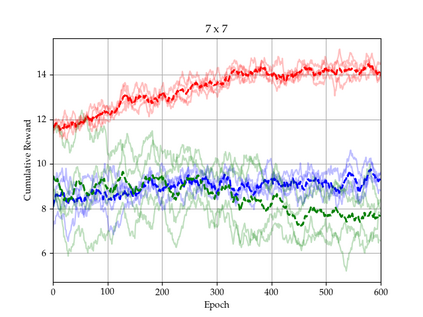
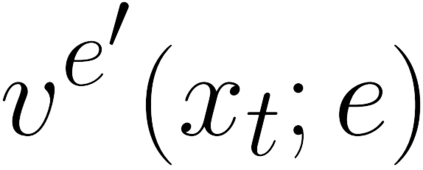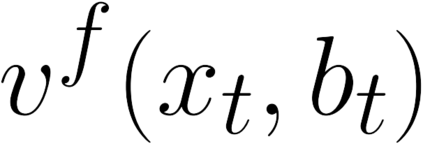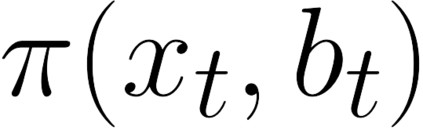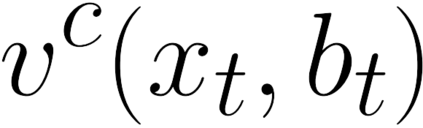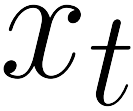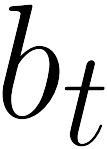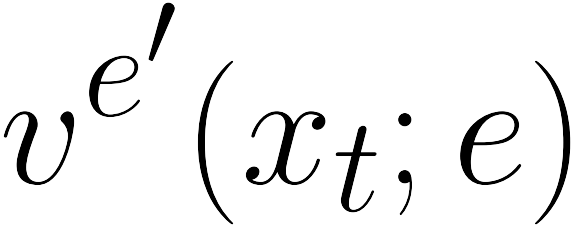There is a strong link between the general concept of intelligence and the ability to collect and use information. The theory of Bayes-adaptive exploration offers an attractive optimality framework for training machines to perform complex information gathering tasks. However, the computational complexity of the resulting optimal control problem has limited the diffusion of the theory to mainstream deep AI research. In this paper we exploit the inherent mathematical structure of Bayes-adaptive problems in order to dramatically simplify the problem by making the reward structure denser while simultaneously decoupling the learning of exploitation and exploration policies. The key to this simplification comes from the novel concept of cross-value (i.e. the value of being in an environment while acting optimally according to another), which we use to quantify the value of currently available information. This results in a new denser reward structure that "cashes in" all future rewards that can be predicted from the current information state. In a set of experiments we show that the approach makes it possible to learn challenging information gathering tasks without the use of shaping and heuristic bonuses in situations where the standard RL algorithms fail.
翻译:情报的一般概念与收集和使用信息的能力之间有着密切的联系。贝耶斯适应性勘探理论为培训机器执行复杂的信息收集任务提供了一个有吸引力的最佳框架。然而,由此产生的最佳控制问题的计算复杂性限制了理论的传播,使其无法将深入的AI研究纳入主流。在本文中,我们利用贝耶斯适应性问题固有的数学结构,通过使奖励结构更加密集,同时分离对开采和勘探政策的学习,大大简化问题。这种简化的关键在于新颖的跨价值概念(即在一个环境中工作的价值,同时根据另一种方法采取最佳行动),我们用这一概念来量化现有信息的价值。这导致一种新的更密集的奖励结构,即从目前的信息状态中可以预测到的所有未来收益。在一系列实验中,我们表明,在标准RL算法失败的情况下,这种方法可以学习挑战性的信息收集任务,而不用形成和超额的奖金。