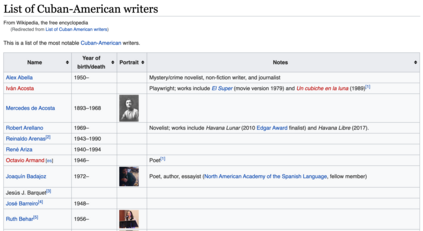
When it comes to factual knowledge about a wide range of domains, Wikipedia is often the prime source of information on the web. DBpedia and YAGO, as large cross-domain knowledge graphs, encode a subset of that knowledge by creating an entity for each page in Wikipedia, and connecting them through edges. It is well known, however, that Wikipedia-based knowledge graphs are far from complete. Especially, as Wikipedia's policies permit pages about subjects only if they have a certain popularity, such graphs tend to lack information about less well-known entities. Information about these entities is oftentimes available in the encyclopedia, but not represented as an individual page. In this paper, we present a two-phased approach for the extraction of entities from Wikipedia's list pages, which have proven to serve as a valuable source of information. In the first phase, we build a large taxonomy from categories and list pages with DBpedia as a backbone. With distant supervision, we extract training data for the identification of new entities in list pages that we use in the second phase to train a classification model. With this approach we extract over 700k new entities and extend DBpedia with 7.5M new type statements and 3.8M new facts of high precision.
翻译:当涉及到对广泛领域的实际了解时,维基百科往往是网上信息的主要来源。DBpedia和YAGO,作为大型跨域知识图表,通过在维基百科中为每个页面创建一个实体来编码该知识的子集,并通过边缘将其连接起来。然而,众所周知,维基百科知识图远非完整。特别是,维基百科政策允许只有具有一定广度的科目网页,这些图表往往缺乏不太为人所知的实体的信息。关于这些实体的信息常常在百科全书中提供,但并不是单个页面。在本文中,我们介绍了从维基百科列表页面中提取实体的两阶段方法,这些实体已被证明是宝贵的信息来源。在第一阶段,我们用DBpedia作为主干,从类别和列表页面中建立大型分类学。在遥远的监督下,我们为在列表页面中识别我们在第二阶段用于培训分类模型的新实体提取培训时间,但没有作为单个网页。我们从维基百科列表页面中提取了7000M的新数据,并扩展了D7.5M新数据。