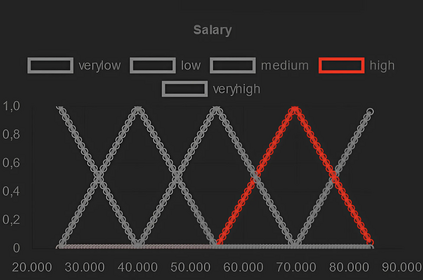
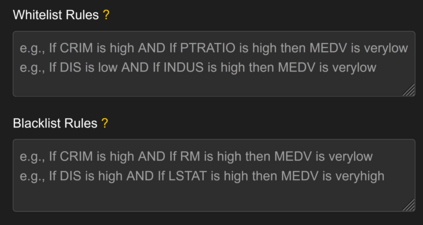
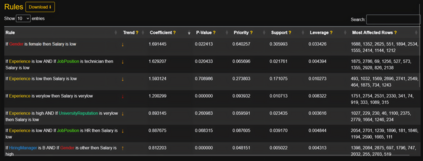
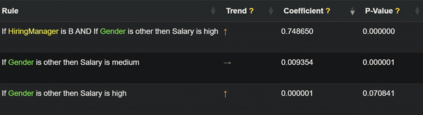
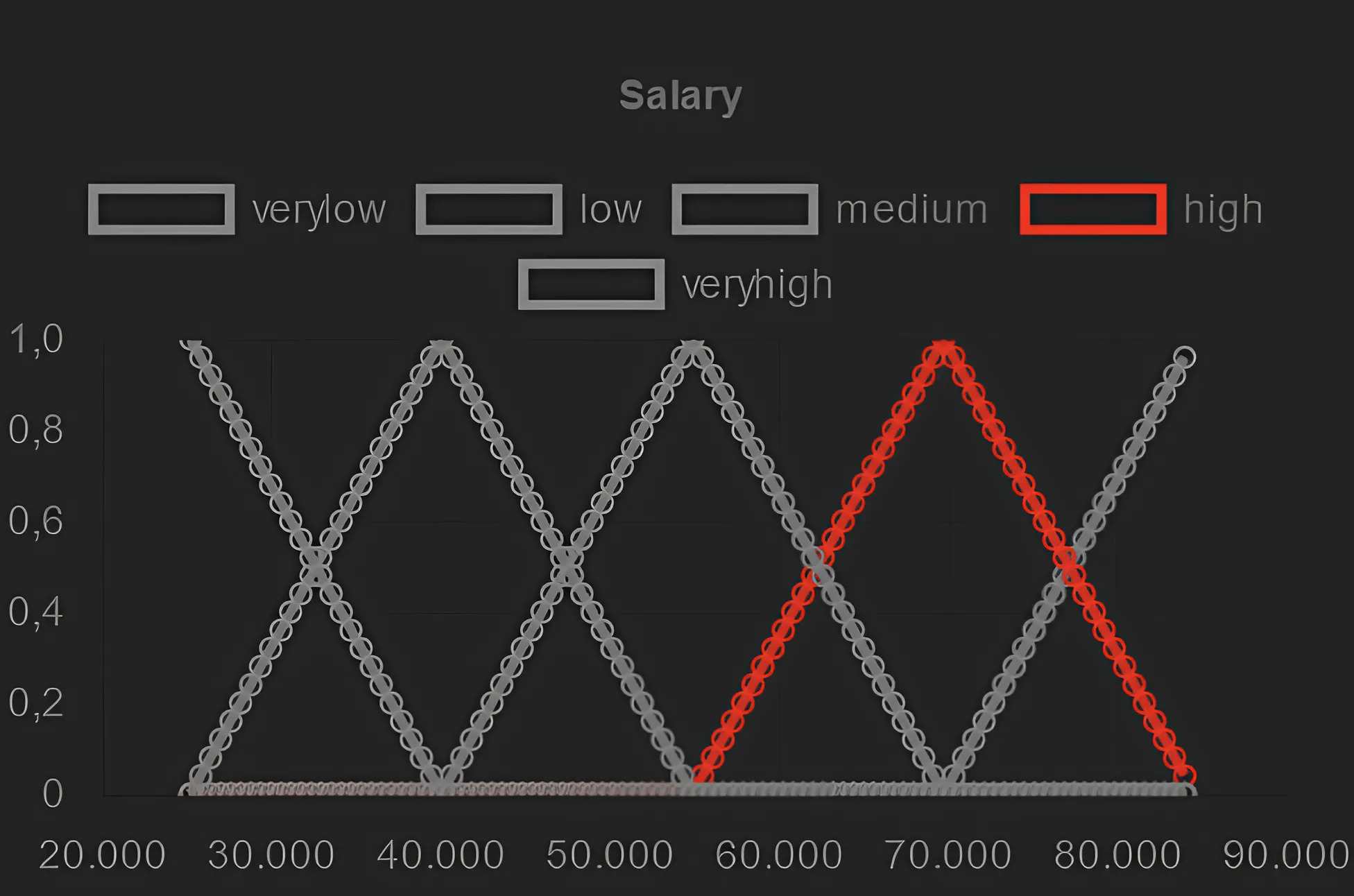
Artificial intelligence models trained from data can only be as good as the underlying data is. Biases in training data propagating through to the output of a machine learning model are a well-documented and well-understood phenomenon, but the machinery to prevent these undesired effects is much less developed. Efforts to ensure data is clean during collection, such as using bias-aware sampling, are most effective when the entity controlling data collection also trains the AI. In cases where the data is already available, how do we find out if the data was already manipulated, i.e., ``poisoned'', so that an undesired behavior would be trained into a machine learning model? This is a challenge fundamentally different to (just) improving approximation accuracy or efficiency, and we provide a method to test training data for flaws, to establish a trustworthy ground-truth for a subsequent training of machine learning models (of any kind). Unlike the well-studied problem of approximating data using fuzzy rules that are generated from the data, our method hinges on a prior definition of rules to happen before seeing the data to be tested. Therefore, the proposed method can also discover hidden error patterns, which may also have substantial influence. Our approach extends the abilities of conventional statistical testing by letting the ``test-condition'' be any Boolean condition to describe a pattern in the data, whose presence we wish to determine. The method puts fuzzy inference into a regression model, to get the best of the two: explainability from fuzzy logic with statistical properties and diagnostics from the regression, and finally also being applicable to ``small data'', hence not requiring large datasets as deep learning methods do. We provide an open source implementation for demonstration and experiments.
翻译:暂无翻译