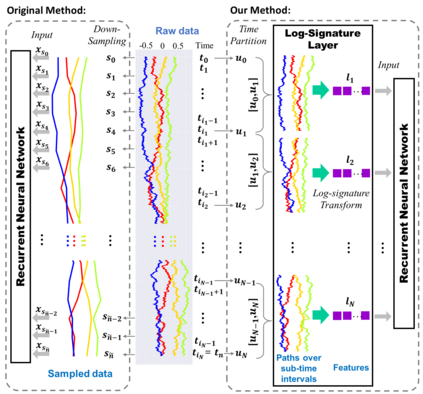
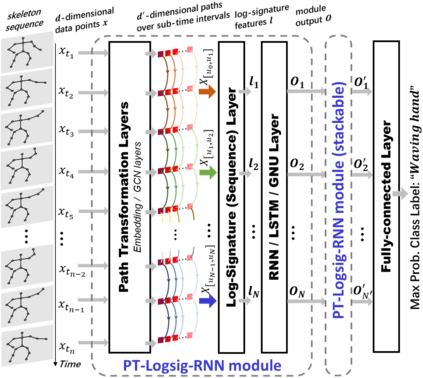
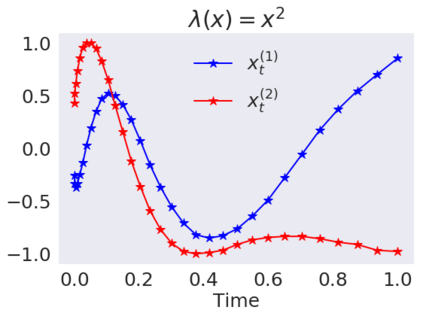
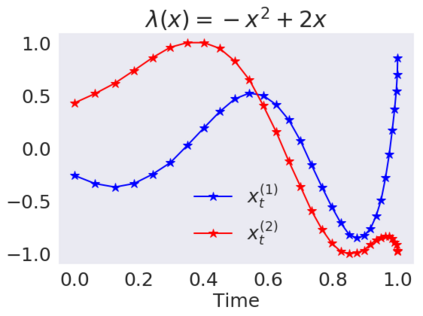
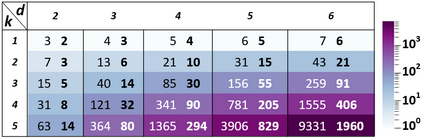
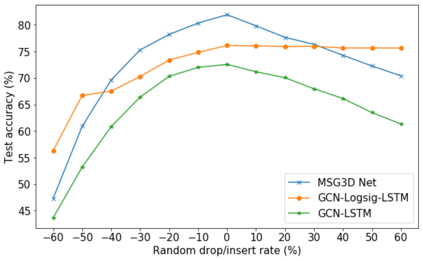
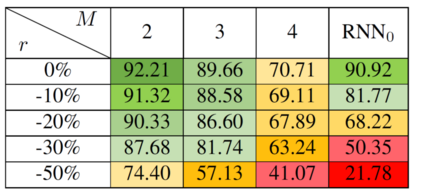
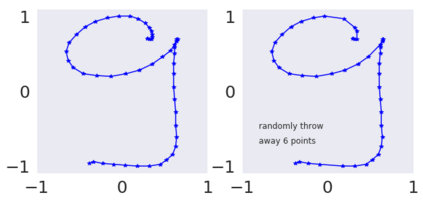
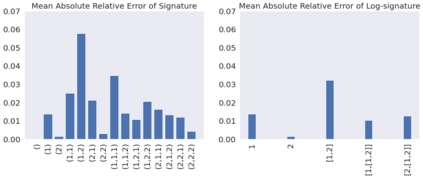
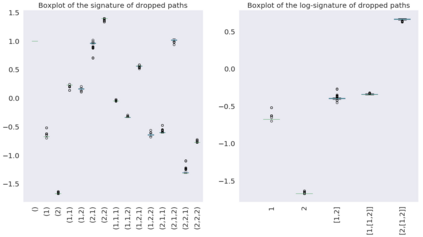
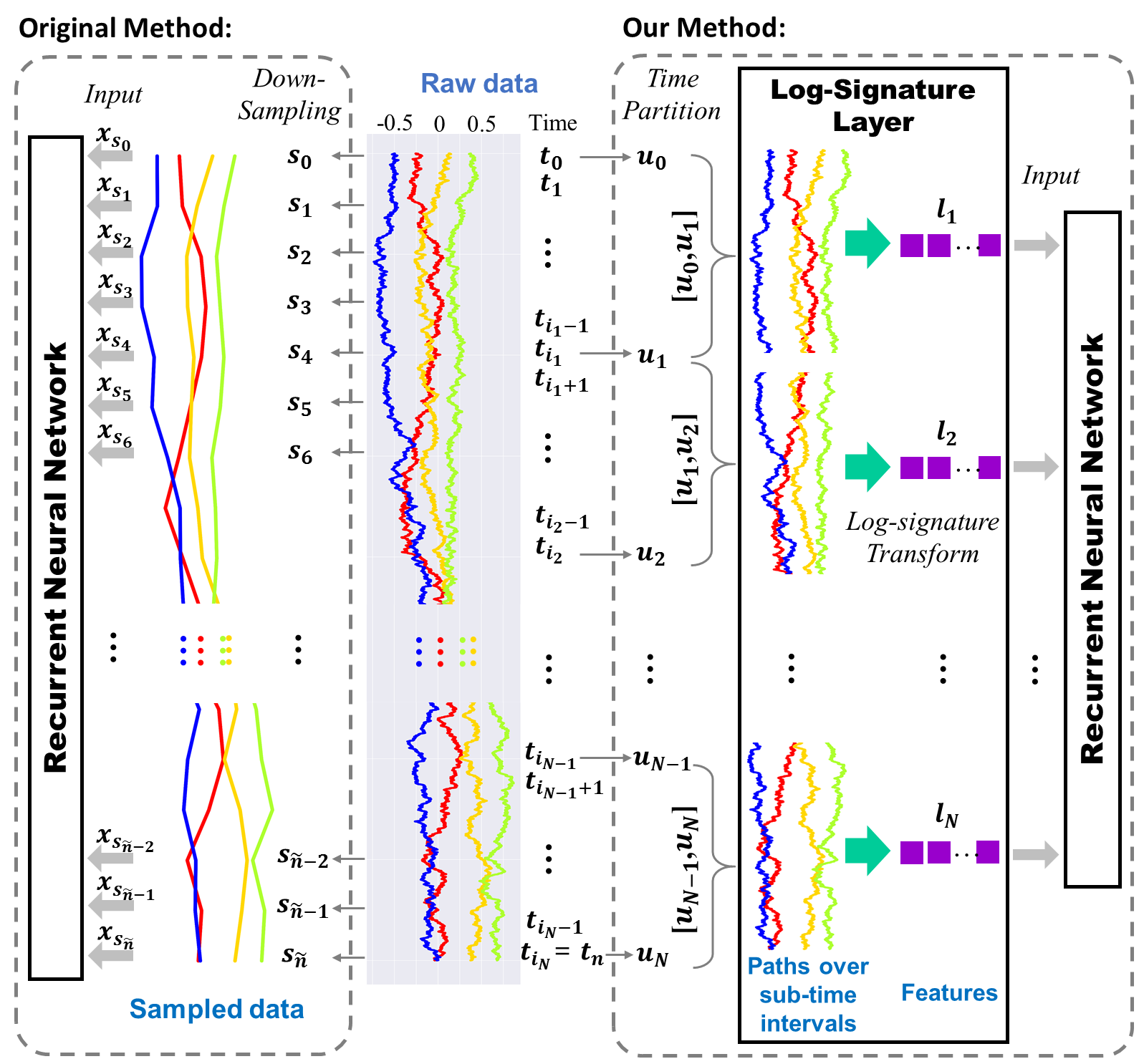
This paper contributes to the challenge of skeleton-based human action recognition in videos. The key step is to develop a generic network architecture to extract discriminative features for the spatio-temporal skeleton data. In this paper, we propose a novel module, namely Logsig-RNN, which is the combination of the log-signature layer and recurrent type neural networks (RNNs). The former one comes from the mathematically principled technology of signatures and log-signatures as representations for streamed data, which can manage high sample rate streams, non-uniform sampling and time series of variable length. It serves as an enhancement of the recurrent layer, which can be conveniently plugged into neural networks. Besides we propose two path transformation layers to significantly reduce path dimension while retaining the essential information fed into the Logsig-RNN module. Finally, numerical results demonstrate that replacing the RNN module by the Logsig-RNN module in SOTA networks consistently improves the performance on both Chalearn gesture data and NTU RGB+D 120 action data in terms of accuracy and robustness. In particular, we achieve the state-of-the-art accuracy on Chalearn2013 gesture data by combining simple path transformation layers with the Logsig-RNN. Codes are available at https://github.com/steveliao93/GCN_LogsigRNN.
翻译:本文有助于应对视频中基于骨架的人类行动识别挑战。 关键步骤是开发一个通用网络架构, 用于为spatio- 时空骨质数据提取歧视性特征。 在本文中, 我们提议了一个新模块, 即 Logsig- RNN, 即日志签名层和经常性型神经网络( RNN) 的组合。 前者来自签名和日志签名的数学原则技术, 以显示流数据, 它可以管理高样本率流、 非统一抽样和时间序列的变长。 它可以增强常态层, 可以方便地插入神经网络。 此外, 我们提议了两个路径转换层, 以大幅降低路径维度, 同时保留输入Logsig- RNNNN 模块的基本信息。 最后, 数字结果显示, SOTA 网络的Logsig- RNNN 模块取代 RNNM 模块, 在准确性和强度方面不断改进 CTU RC+D 120行动数据的性能性。 特别是, 我们实现了州- Rf- NG- NG- sal- adliab sal sal sal silps 。