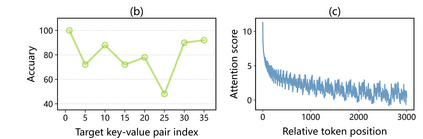
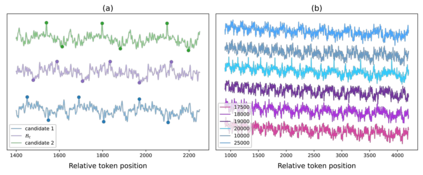
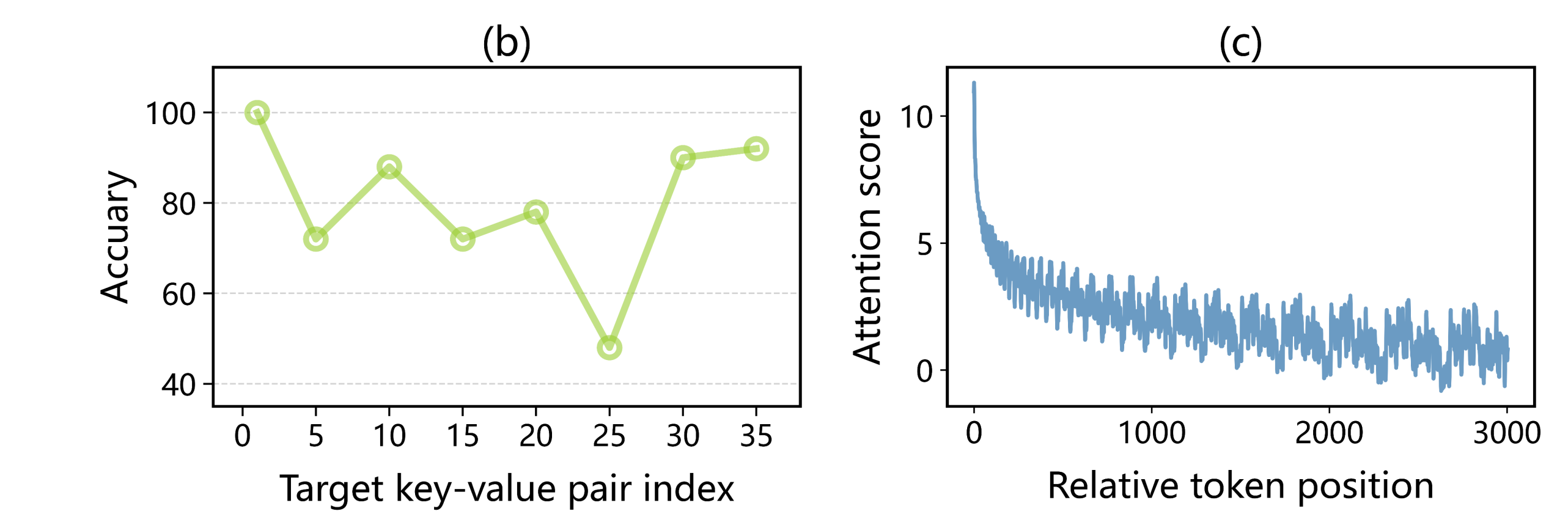
In this paper, we demonstrate that an inherent waveform pattern in the attention allocation of large language models (LLMs) significantly affects their performance in tasks demanding a high degree of context awareness, such as utilizing LLMs for tool-use. Specifically, the crucial information in the context will be potentially overlooked by model when it is positioned in the trough zone of the attention waveform, leading to decreased performance. To address this issue, we propose a novel inference method named Attention Buckets. It allows LLMs to process their input through multiple parallel processes. Each process utilizes a distinct base angle for the rotary position embedding, thereby creating a unique attention waveform. By compensating an attention trough of a particular process with an attention peak of another process, our approach enhances LLM's awareness to various contextual positions, thus mitigating the risk of overlooking crucial information. In the largest tool-use benchmark, our method elevates a 7B model to achieve state-of-the-art performance, comparable to that of GPT-4. On other benchmarks and some RAG tasks, which also demand a thorough understanding of contextual content, Attention Buckets also exhibited notable enhancements in performance.
翻译:暂无翻译