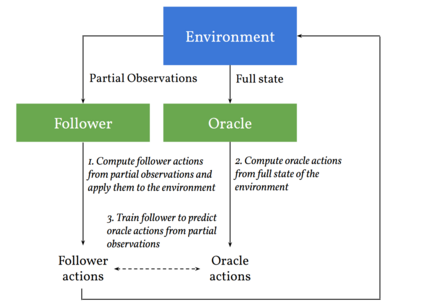
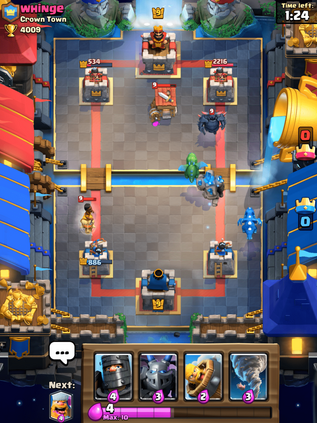
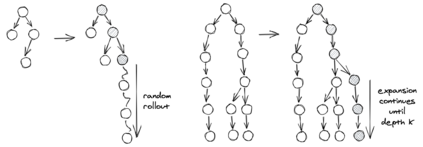
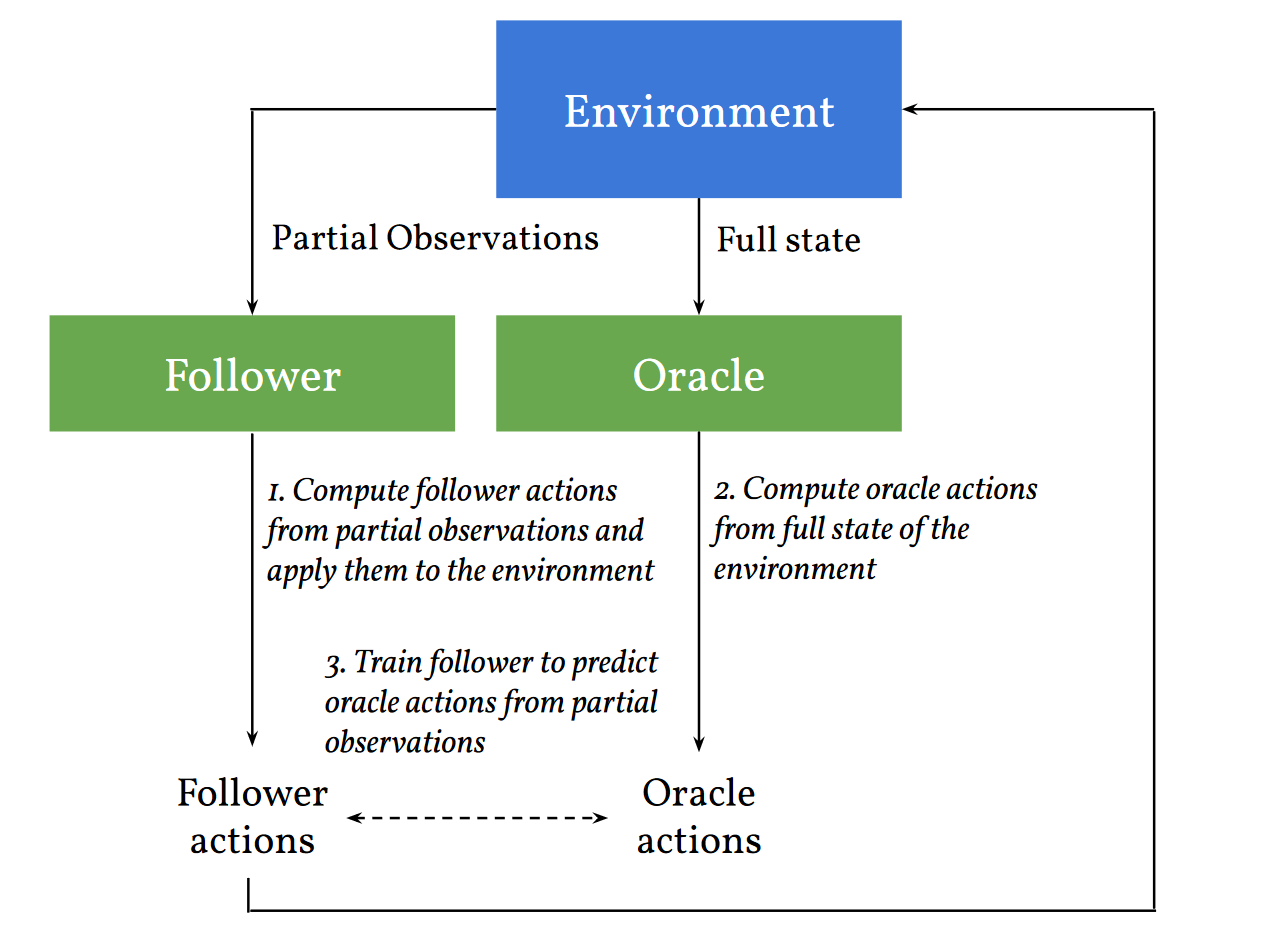
We consider learning to play multiplayer imperfect-information games with simultaneous moves and large state-action spaces. Previous attempts to tackle such challenging games have largely focused on model-free learning methods, often requiring hundreds of years of experience to produce competitive agents. Our approach is based on model-based planning. We tackle the problem of partial observability by first building an (oracle) planner that has access to the full state of the environment and then distilling the knowledge of the oracle to a (follower) agent which is trained to play the imperfect-information game by imitating the oracle's choices. We experimentally show that planning with naive Monte Carlo tree search does not perform very well in large combinatorial action spaces. We therefore propose planning with a fixed-depth tree search and decoupled Thompson sampling for action selection. We show that the planner is able to discover efficient playing strategies in the games of Clash Royale and Pommerman and the follower policy successfully learns to implement them by training on a few hundred battles.
翻译:我们考虑学习玩多玩者不完善的信息游戏,同时进行动作和大型国家行动空间。以前处理这种挑战性游戏的尝试主要集中在无模式学习方法上,通常需要数百年的经验才能产生有竞争力的代理人。我们的方法是以模型为基础的规划为基础。我们首先建造一个能够接触到整个环境状态的(神器)规划员,然后将神器的知识提炼到一个(追随者)代理商身上,该代理商受过训练,通过模仿神器的选择来玩不完善的信息游戏。我们实验性地显示,在大型组合行动空间里,用天真的蒙特卡洛树搜索并不很好。因此我们提议进行固定深度的树搜索,并拆解汤普森取样,以便选择行动。我们表明,规划员能够发现在克莱施罗亚和波默曼的游戏中高效的游戏策略,而后续政策则成功地通过几百场的战斗训练来实施这些策略。