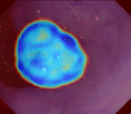
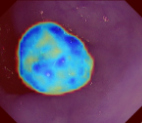
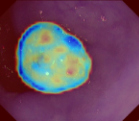
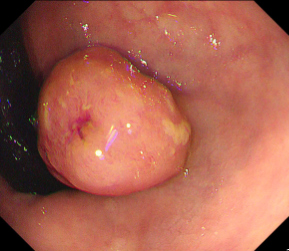
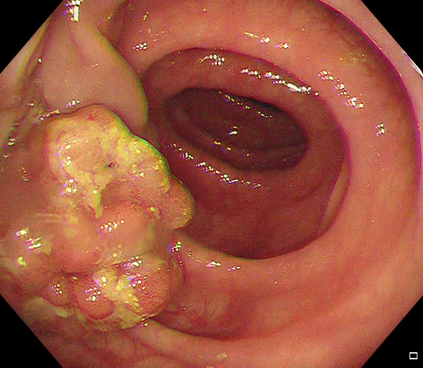
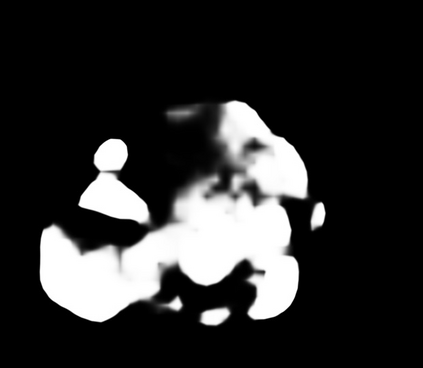
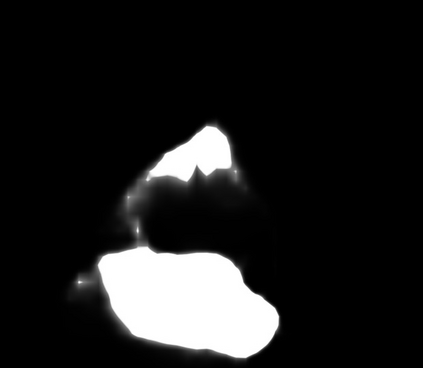
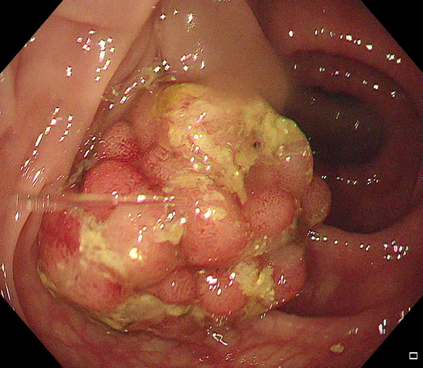
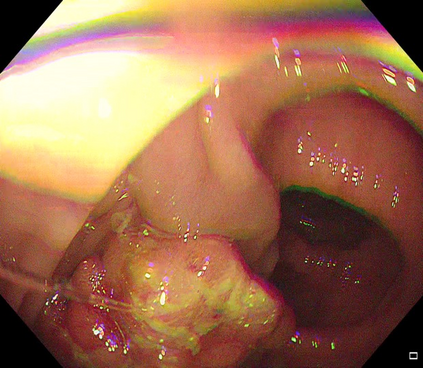
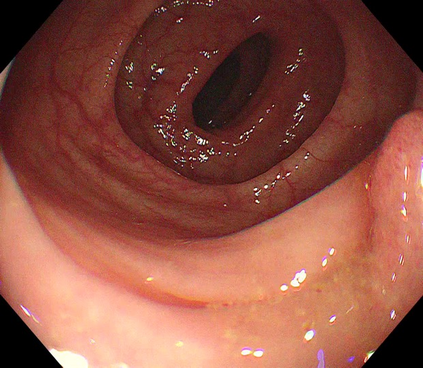
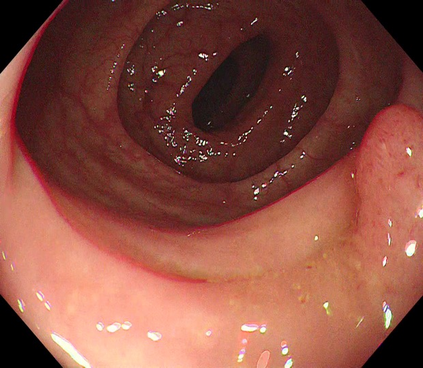
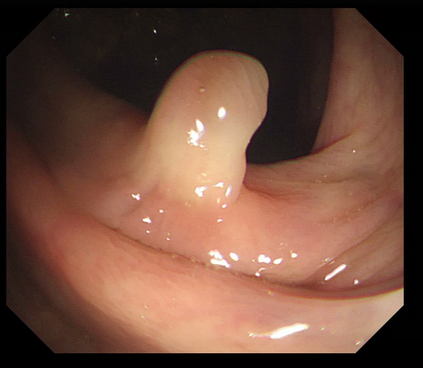
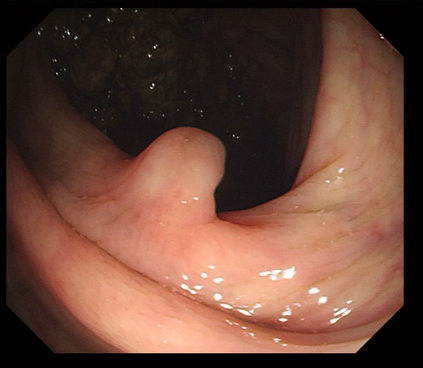
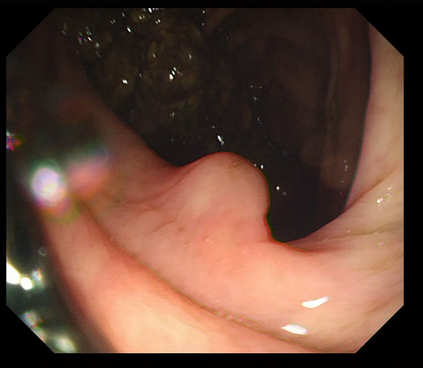
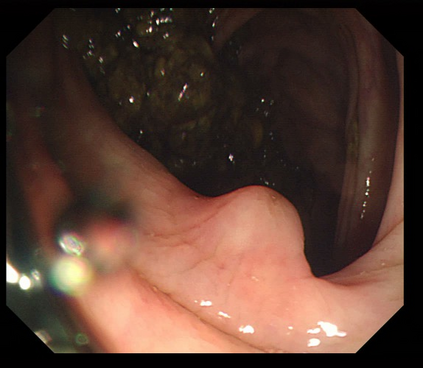
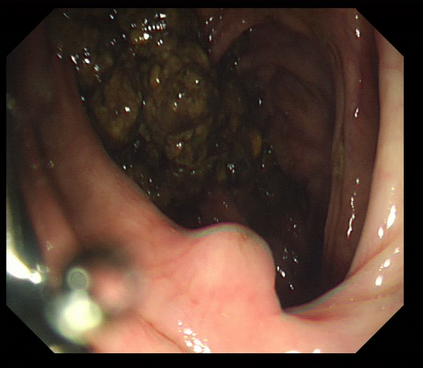
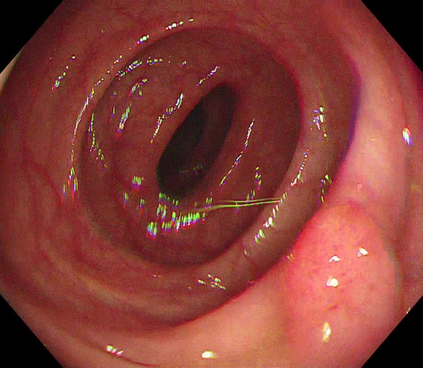
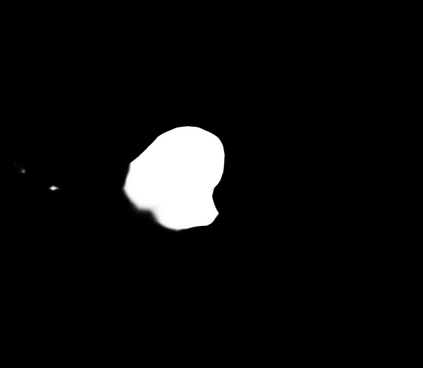
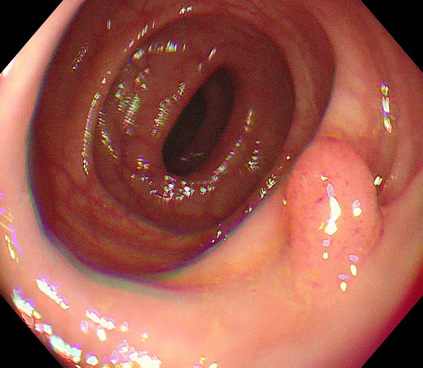
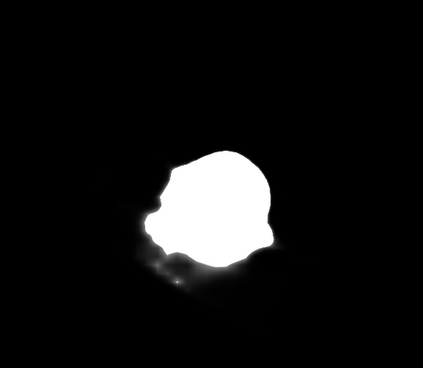
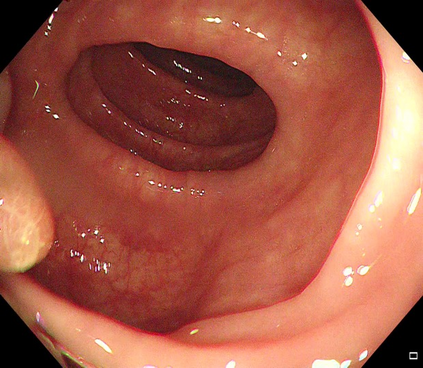
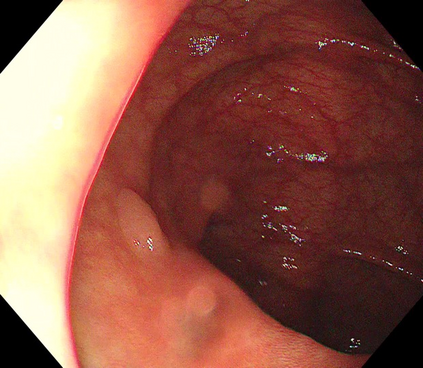
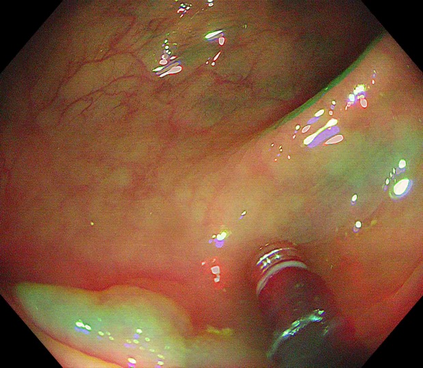
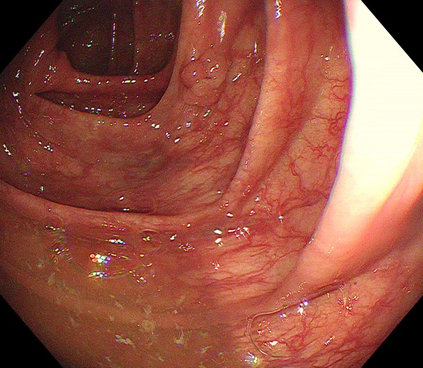
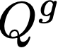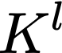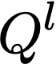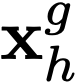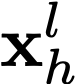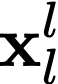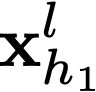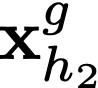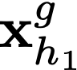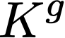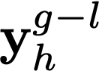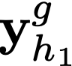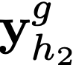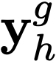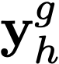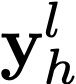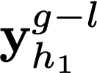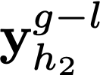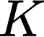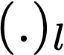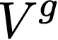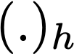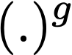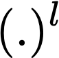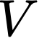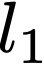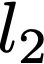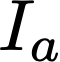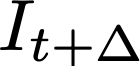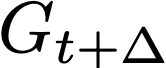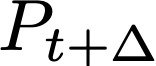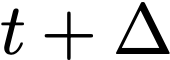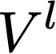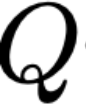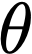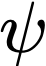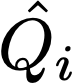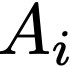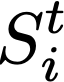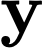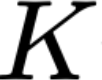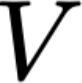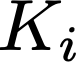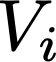Polyps are early cancer indicators, so assessing occurrences of polyps and their removal is critical. They are observed through a colonoscopy screening procedure that generates a stream of video frames. Segmenting polyps in their natural video screening procedure has several challenges, such as the co-existence of imaging artefacts, motion blur, and floating debris. Most existing polyp segmentation algorithms are developed on curated still image datasets that do not represent real-world colonoscopy. Their performance often degrades on video data. We propose a video polyp segmentation method that performs self-supervised learning as an auxiliary task and a spatial-temporal self-attention mechanism for improved representation learning. Our end-to-end configuration and joint optimisation of losses enable the network to learn more discriminative contextual features in videos. Our experimental results demonstrate an improvement with respect to several state-of-the-art (SOTA) methods. Our ablation study also confirms that the choice of the proposed joint end-to-end training improves network accuracy by over 3% and nearly 10% on both the Dice similarity coefficient and intersection-over-union compared to the recently proposed method PNS+ and Polyp-PVT, respectively. Results on previously unseen video data indicate that the proposed method generalises.
翻译:暂无翻译