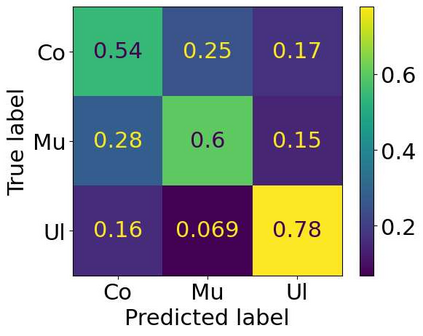
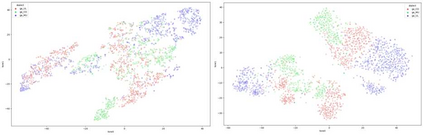
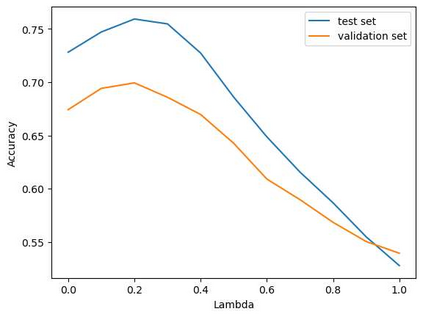
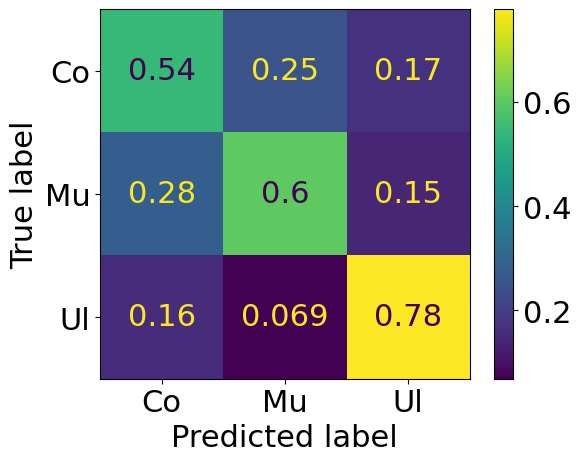
The Irish language is rich in its diversity of dialects and accents. This compounds the difficulty of creating a speech recognition system for the low-resource language, as such a system must contend with a high degree of variability with limited corpora. A recent study investigating dialect bias in Irish ASR found that balanced training corpora gave rise to unequal dialect performance, with performance for the Ulster dialect being consistently worse than for the Connacht or Munster dialects. Motivated by this, the present experiments investigate spoken dialect identification of Irish, with a view to incorporating such a system into the speech recognition pipeline. Two acoustic classification models are tested, XLS-R and ECAPA-TDNN, in conjunction with a text-based classifier using a pretrained Irish-language BERT model. The ECAPA-TDNN, particularly a model pretrained for language identification on the VoxLingua107 dataset, performed best overall, with an accuracy of 73%. This was further improved to 76% by fusing the model's outputs with the text-based model. The Ulster dialect was most accurately identified, with an accuracy of 94%, however the model struggled to disambiguate between the Connacht and Munster dialects, suggesting a more nuanced approach may be necessary to robustly distinguish between the dialects of Irish.
翻译:暂无翻译