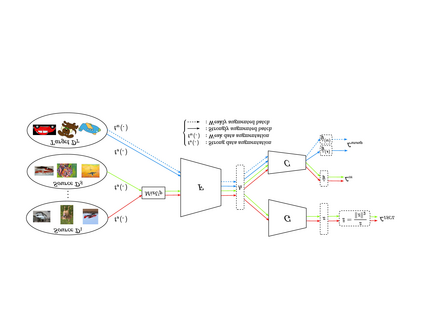
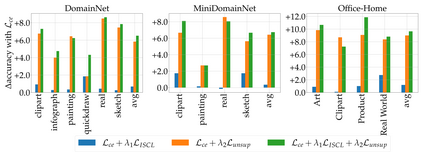
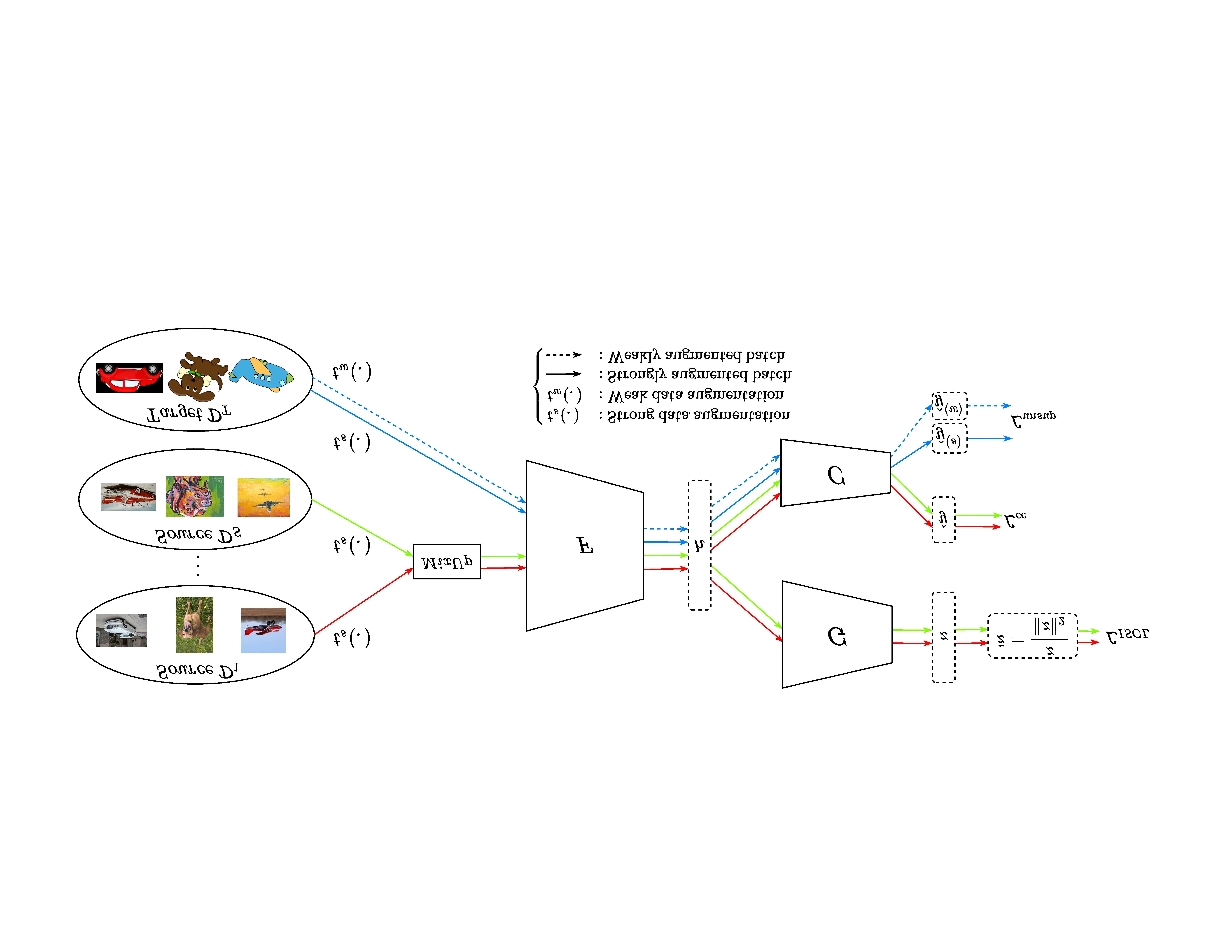
Multi-Source Unsupervised Domain Adaptation (multi-source UDA) aims to learn a model from several labeled source domains while performing well on a different target domain where only unlabeled data are available at training time. To align source and target features distributions, several recent works use source and target explicit statistics matching such as features moments or class centroids. Yet, these approaches do not guarantee class conditional distributions alignment across domains. In this work, we propose a new framework called Contrastive Multi-Source Domain Adaptation (CMSDA) for multi-source UDA that addresses this limitation. Discriminative features are learned from interpolated source examples via cross entropy minimization and from target examples via consistency regularization and hard pseudo-labeling. Simultaneously, interpolated source examples are leveraged to align source class conditional distributions through an interpolated version of the supervised contrastive loss. This alignment leads to more general and transferable features which further improves the generalization on the target domain. Extensive experiments have been carried out on three standard multi-source UDA datasets where our method reports state-of-the-art results.
翻译:多源未受监督的域适应(多源 UDA) 旨在从几个标签源域中学习一个模型,同时在培训时只提供无标签数据的不同目标域中很好地运行。为了对源和目标特性分布进行统一,最近一些著作使用源和目标特性源,并针对明确的统计数据,如特征瞬间或类固醇等。然而,这些方法并不能保证跨域的等级有条件分布一致。在这项工作中,我们提议为多源域UDA提出一个新的框架,称为反源多源域适应(CMSDA),以解决这一限制问题。通过交叉加密最小化和通过一致性正规化和硬伪标签化化化的目标实例,从中间来源实例中学习了差异性特征。同时,还利用了多极来源实例,通过受监督的对比损失的内插式版本,将源类别有条件分布相匹配。这种协调导致更笼统和可转让的特性,从而进一步改善目标域的通用化。在三种标准的多源UDA数据集上进行了广泛的实验,我们的方法报告了最新结果。