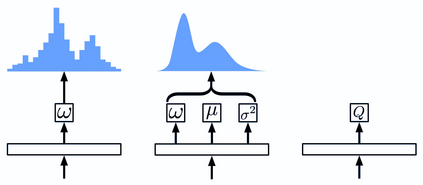
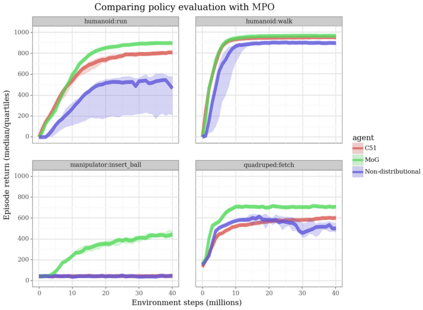
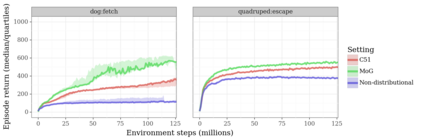
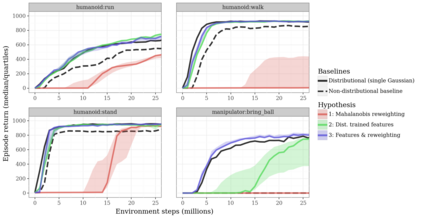
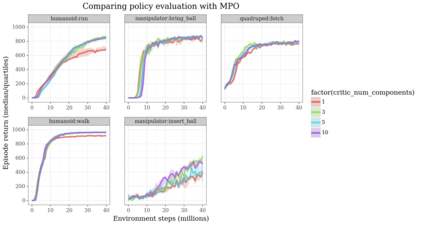
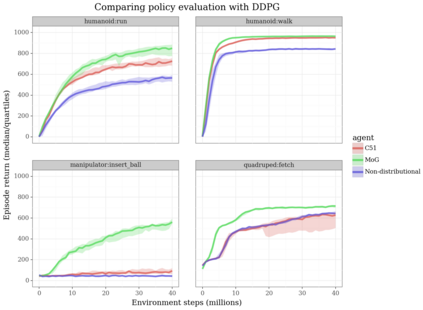
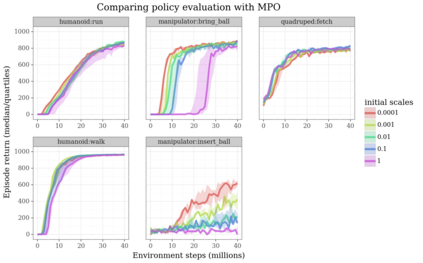
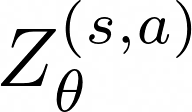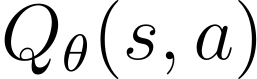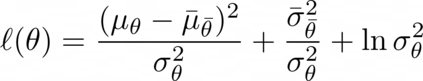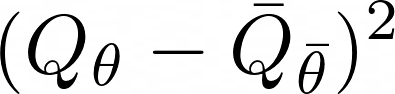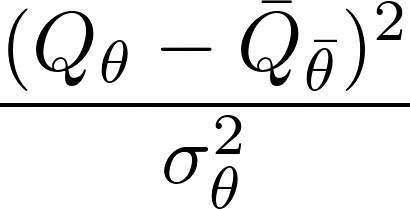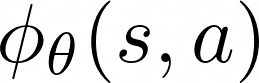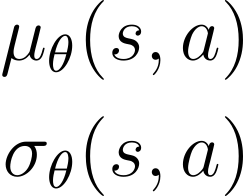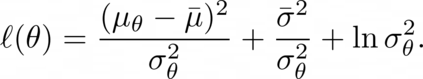Actor-critic algorithms that make use of distributional policy evaluation have frequently been shown to outperform their non-distributional counterparts on many challenging control tasks. Examples of this behavior include the D4PG and DMPO algorithms as compared to DDPG and MPO, respectively [Barth-Maron et al., 2018; Hoffman et al., 2020]. However, both agents rely on the C51 critic for value estimation.One major drawback of the C51 approach is its requirement of prior knowledge about the minimum andmaximum values a policy can attain as well as the number of bins used, which fixes the resolution ofthe distributional estimate. While the DeepMind control suite of tasks utilizes standardized rewards and episode lengths, thus enabling the entire suite to be solved with a single setting of these hyperparameters, this is often not the case. This paper revisits a natural alternative that removes this requirement, namelya mixture of Gaussians, and a simple sample-based loss function to train it in an off-policy regime. We empirically evaluate its performance on a broad range of continuous control tasks and demonstrate that it eliminates the need for these distributional hyperparameters and achieves state-of-the-art performance on a variety of challenging tasks (e.g. the humanoid, dog, quadruped, and manipulator domains). Finallywe provide an implementation in the Acme agent repository.
翻译:利用分配政策评价的Acor-critic 算法经常显示,在很多具有挑战性的控制任务方面,使用分布式政策评价的Act-critical 运算法往往优于其非分布式对应方,例如D4PG和DMPO的算法,分别与DPG和MPO相比(Barth-Maron等人,2018年;Hoffman等人,2020年)。但是,这两种代理商都依赖C51评论家来估计价值。C51方法的一个主要缺点是,它需要事先了解政策所能达到的最低和最高值,以及所使用的确定分配估计解决办法的垃圾箱数量。虽然Dep Mind 任务控制套件使用标准化的奖励和事件长度,从而使整个套件能够用这些超参数的单一设置来解决问题,但情况往往并非如此。本文回顾了一种自然的替代方法,取消了这一要求,即高司的混合物,以及一个简单的基于抽样的损失功能,以在离政策制度下培训它。我们从经验上评估它在一系列广泛的连续控制任务上的表现,并表明它需要高机构在高机构执行这些任务时,最终消除这些业绩。