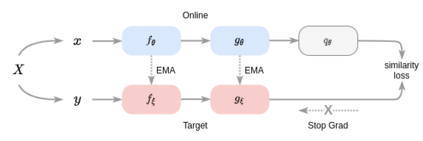
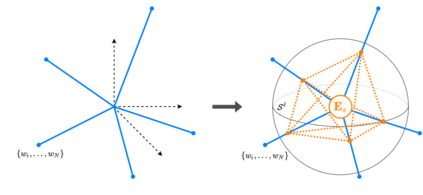
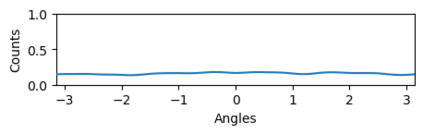
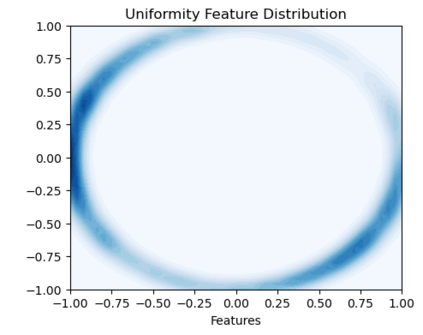
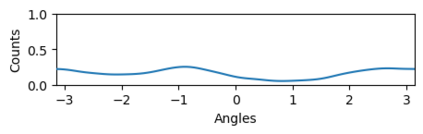
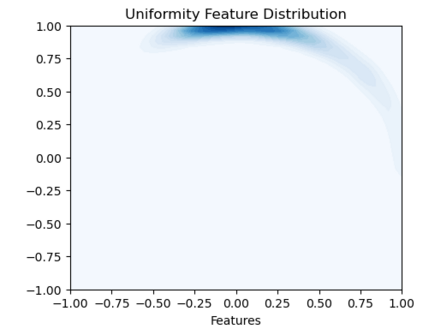
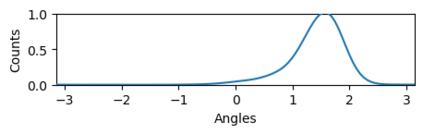
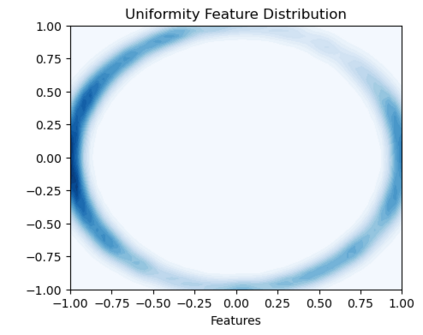
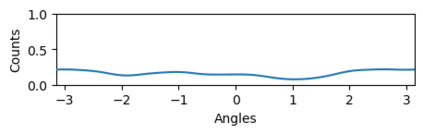
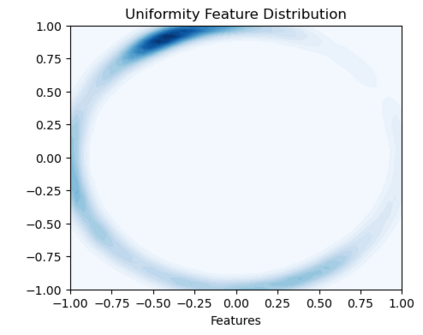
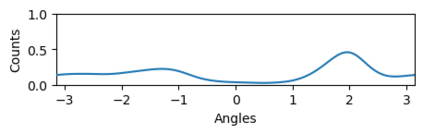
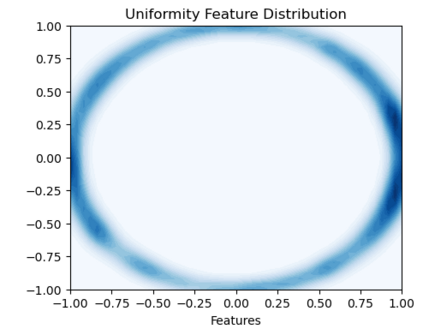
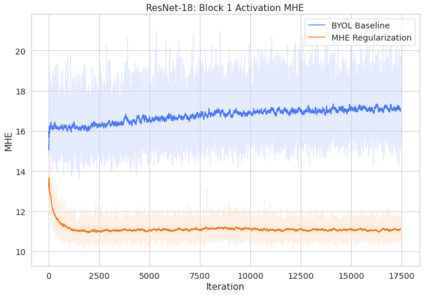
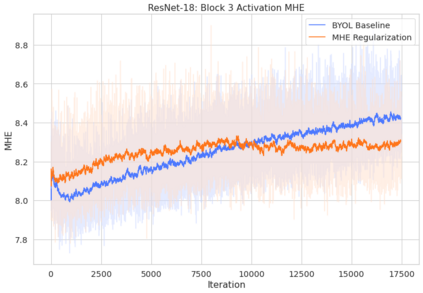
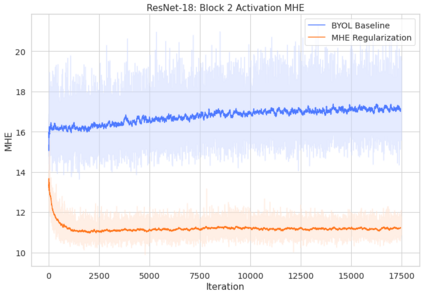
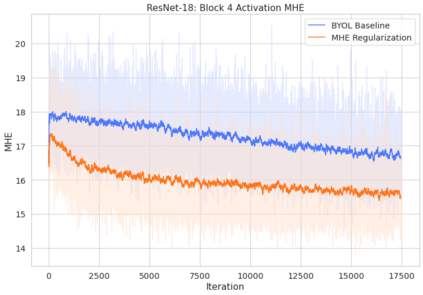
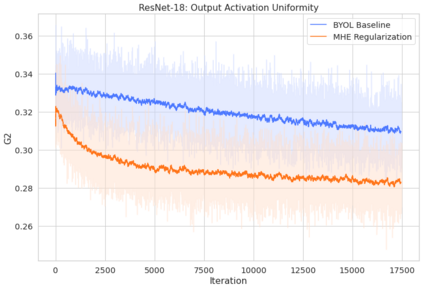
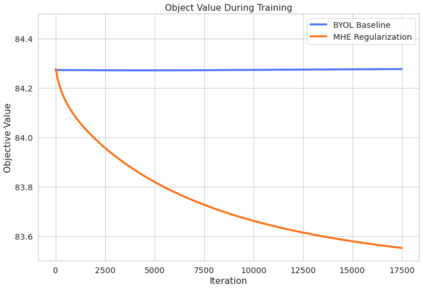
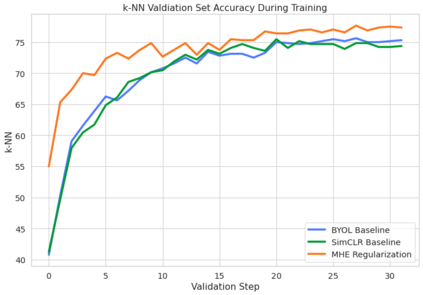
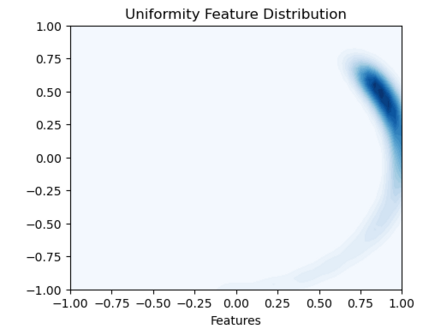
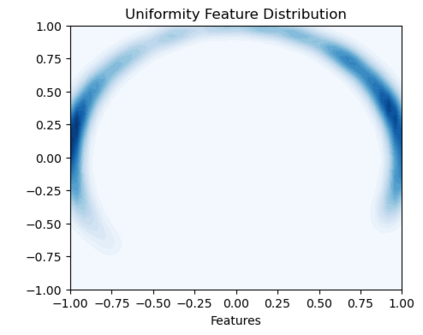
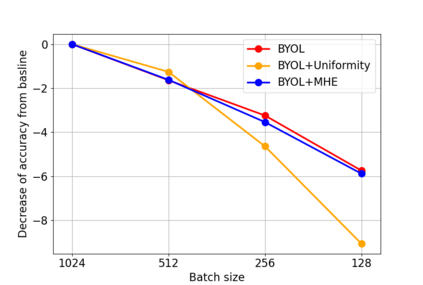
Bootstrap Your Own Latent (BYOL) introduced an approach to self-supervised learning avoiding the contrastive paradigm and subsequently removing the computational burden of negative sampling associated with such methods. However, we empirically find that the image representations produced under the BYOL's self-distillation paradigm are poorly distributed in representation space compared to contrastive methods. This work empirically demonstrates that feature diversity enforced by contrastive losses is beneficial to image representation uniformity when employed in BYOL, and as such, provides greater inter-class representation separability. Additionally, we explore and advocate the use of regularization methods, specifically the layer-wise minimization of hyperspherical energy (i.e. maximization of entropy) of network weights to encourage representation uniformity. We show that directly optimizing a measure of uniformity alongside the standard loss, or regularizing the networks of the BYOL architecture to minimize the hyperspherical energy of neurons can produce more uniformly distributed and therefore better performing representations for downstream tasks.
翻译:然而,我们从经验中发现,与对比方法相比,BYOL自我蒸馏模式下产生的图像展示在代表空间分布不均。 这项工作从经验中表明,对比损失造成的特征多样性有利于在BYOL使用时实现图像表述的统一性,从而提供更大的阶级间代表分离性。 此外,我们探索并倡导使用正规化方法,特别是将网络超球能量(即最大限度地增加英特普)的层位最小化,以鼓励代表性的统一性。我们表明,在标准损失的同时,直接优化统一度,或者将BYOL结构网络正规化,以最大限度地减少神经元超球能,可以产生更统一的分布,从而更好地为下游任务进行演示。