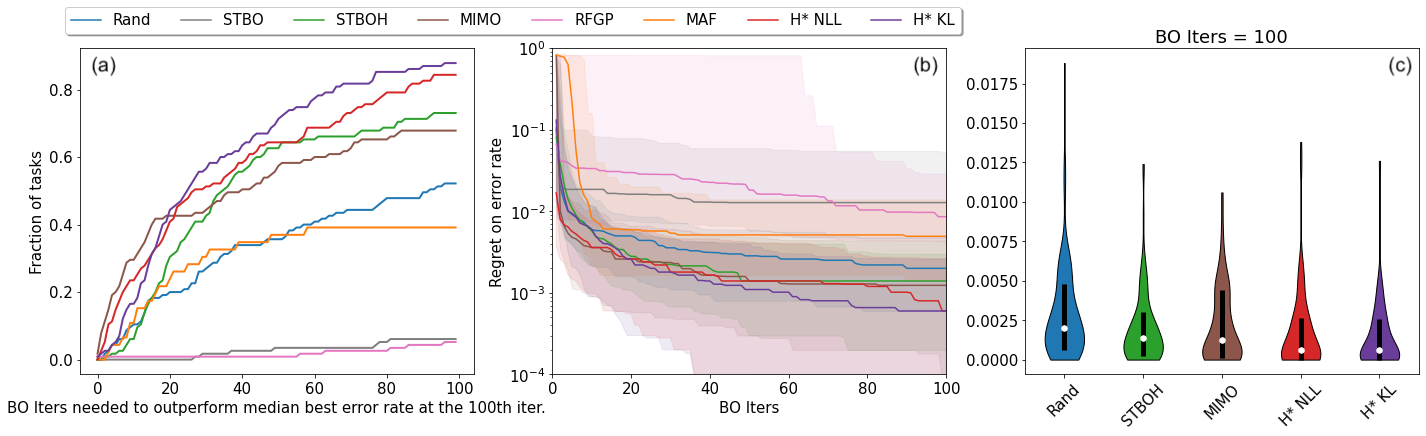
Bayesian optimization (BO) has become a popular strategy for global optimization of many expensive real-world functions. Contrary to a common belief that BO is suited to optimizing black-box functions, it actually requires domain knowledge on characteristics of those functions to deploy BO successfully. Such domain knowledge often manifests in Gaussian process priors that specify initial beliefs on functions. However, even with expert knowledge, it is not an easy task to select a prior. This is especially true for hyperparameter tuning problems on complex machine learning models, where landscapes of tuning objectives are often difficult to comprehend. We seek an alternative practice for setting these functional priors. In particular, we consider the scenario where we have data from similar functions that allow us to pre-train a tighter distribution a priori. To verify our approach in realistic model training setups, we collected a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art models on popular image and text datasets, as well as a protein sequence dataset. Our results show that on average, our method is able to locate good hyperparameters at least 3 times more efficiently than the best competing methods.
翻译:Bayesian优化(BO)已经成为全球优化许多昂贵现实世界功能的流行战略。 与人们普遍认为BO适合优化黑盒功能的通用观点相反,它实际上需要有关这些功能特点的域知识才能成功部署BO。 这种域知识通常表现在指定功能初始信念的高山进程前期。 然而,即使有专家知识,也不容易选择一个先行任务。 对于复杂机器学习模型的超参数调调控问题来说尤其如此,因为那里的调控目标的景观往往难以理解。 我们寻求一种替代做法来设置这些功能前置。 特别是,我们考虑的情景是,我们拥有类似功能的数据,使我们能够事先进行更严密的配置。 为了在现实的模型培训设置中验证我们的方法,我们收集了一个大型的多任务超参数调整数据集,通过培训数以万计的近州级图像和文本数据集模型配置以及蛋白质序列数据集来调整。 我们的结果显示,平均而言,我们的方法能够更高效地定位优于3次的超标准。